 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Disentangled Text-Guided Image Editing via Sparse Latent Constraints
Dec 25, 2025Text-driven image manipulation often suffers from attribute entanglement, where modifying a target attribute (e.g., adding bangs) unintentionally alters other semantic properties such as identity or appearance. The Predict, Prevent, and Evaluate (PPE) framework addresses this issue by leveraging pre-trained vision-language models for disentangled editing. In this work, we analyze the PPE framework, focusing on its architectural components, including BERT-based attribute prediction and StyleGAN2-based image generation on the CelebA-HQ dataset. Through empirical analysis, we identify a limitation in the original regularization strategy, where latent updates remain dense and prone to semantic leakage. To mitigate this issue, we introduce a sparsity-based constraint using L1 regularization on latent space manipulation. Experimental results demonstrate that the proposed approach enforces more focused and controlled edits, effectively reducing unintended changes in non-target attributes while preserving facial identity.
Input-Adaptive Visual Preprocessing for Efficient Fast Vision-Language Model Inference
Dec 23, 2025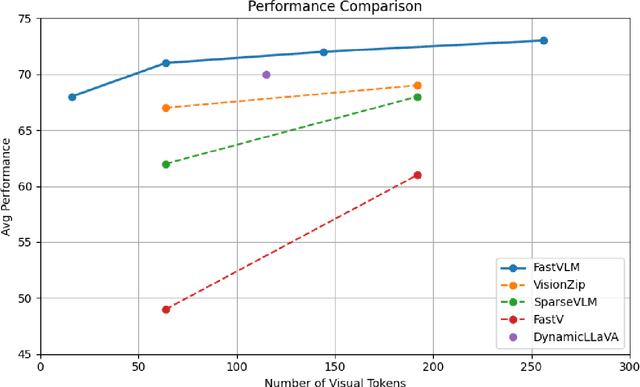
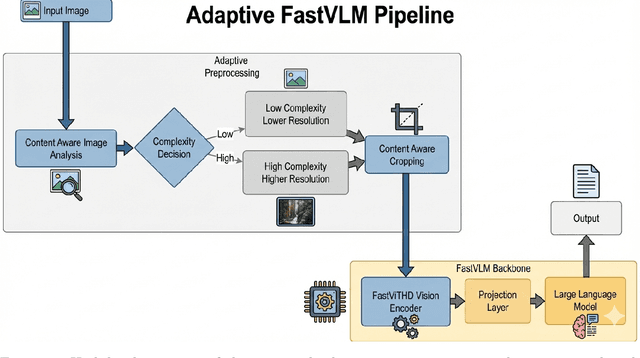
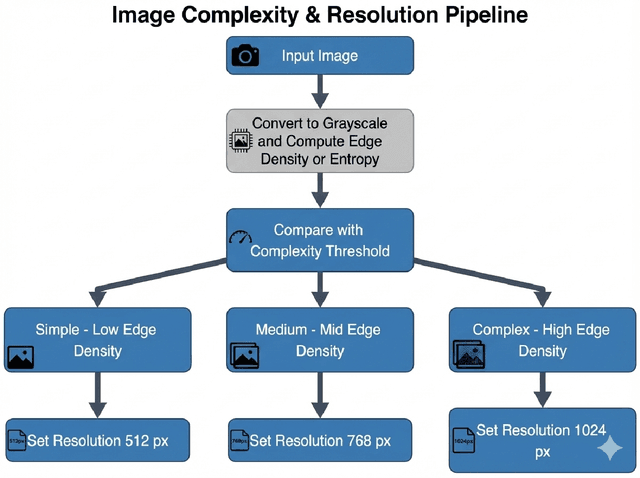
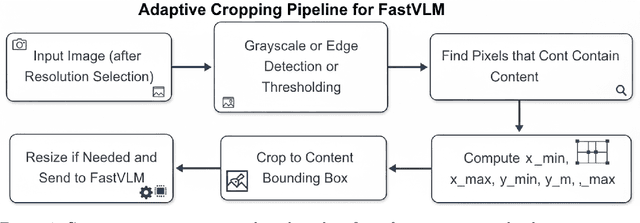
Vision-Language Models (VLMs) have demonstrated strong performance on multimodal reasoning tasks, but their deployment remains challenging due to high inference latency and computational cost, particularly when processing high-resolution visual inputs. While recent architectures such as FastVLM improve efficiency through optimized vision encoders, existing pipelines still rely on static visual preprocessing, leading to redundant computation for visually simple inputs. In this work, we propose an adaptive visual preprocessing method that dynamically adjusts input resolution and spatial coverage based on image content characteristics. The proposed approach combines content-aware image analysis, adaptive resolution selection, and content-aware cropping to reduce visual redundancy prior to vision encoding. Importantly, the method is integrated with FastVLM without modifying its architecture or requiring retraining. We evaluate the proposed method on a subset of the DocVQA dataset in an inference-only setting, focusing on efficiency-oriented metrics. Experimental results show that adaptive preprocessing reduces per-image inference time by over 50\%, lowers mean full generation time, and achieves a consistent reduction of more than 55\% in visual token count compared to the baseline pipeline. These findings demonstrate that input-aware preprocessing is an effective and lightweight strategy for improving deployment-oriented efficiency of vision-language models. To facilitate reproducibility, our implementation is provided as a fork of the FastVLM repository, incorporating the files for the proposed method, and is available at https://github.com/kmdavidds/mlfastlm.
ASVRI-Legal: Fine-Tuning LLMs with Retrieval Augmented Generation for Enhanced Legal Regulation
Nov 05, 2025In this study, we explore the fine-tuning of Large Language Models (LLMs) to better support policymakers in their crucial work of understanding, analyzing, and crafting legal regulations. To equip the model with a deep understanding of legal texts, we curated a supervised dataset tailored to the specific needs of the legal domain. Additionally, we integrated the Retrieval-Augmented Generation (RAG) method, enabling the LLM to access and incorporate up-to-date legal knowledge from external sources. This combination of fine-tuning and RAG-based augmentation results in a tool that not only processes legal information but actively assists policymakers in interpreting regulations and drafting new ones that align with current needs. The results demonstrate that this approach can significantly enhance the effectiveness of legal research and regulation development, offering a valuable resource in the ever-evolving field of law.
Efficient Object Detection of Marine Debris using Pruned YOLO Model
Jan 27, 2025
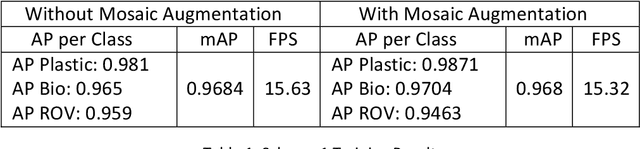
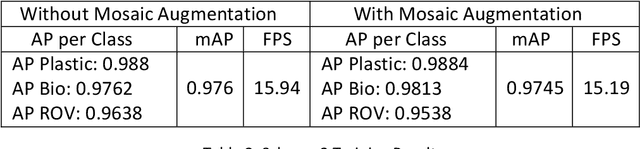
Marine debris poses significant harm to marine life due to substances like microplastics, polychlorinated biphenyls, and pesticides, which damage habitats and poison organisms. Human-based solutions, such as diving, are increasingly ineffective in addressing this issue. Autonomous underwater vehicles (AUVs) are being developed for efficient sea garbage collection, with the choice of object detection architecture being critical. This research employs the YOLOv4 model for real-time detection of marine debris using the Trash-ICRA 19 dataset, consisting of 7683 images at 480x320 pixels. Various modifications-pretrained models, training from scratch, mosaic augmentation, layer freezing, YOLOv4-tiny, and channel pruning-are compared to enhance architecture efficiency. Channel pruning significantly improves detection speed, increasing the base YOLOv4 frame rate from 15.19 FPS to 19.4 FPS, with only a 1.2% drop in mean Average Precision, from 97.6% to 96.4%.
Variational Mode Decomposition and Linear Embeddings are What You Need For Time-Series Forecasting
Sep 04, 2024Time-series forecasting often faces challenges due to data volatility, which can lead to inaccurate predictions. Variational Mode Decomposition (VMD) has emerged as a promising technique to mitigate volatility by decomposing data into distinct modes, thereby enhancing forecast accuracy. In this study, we integrate VMD with linear models to develop a robust forecasting framework. Our approach is evaluated on 13 diverse datasets, including ETTm2, WindTurbine, M4, and 10 air quality datasets from various Southeast Asian cities. The effectiveness of the VMD strategy is assessed by comparing Root Mean Squared Error (RMSE) values from models utilizing VMD against those without it. Additionally, we benchmark linear-based models against well-known neural network architectures such as LSTM, Bidirectional LSTM, and RNN. The results demonstrate a significant reduction in RMSE across nearly all models following VMD application. Notably, the Linear + VMD model achieved the lowest average RMSE in univariate forecasting at 0.619. In multivariate forecasting, the DLinear + VMD model consistently outperformed others, attaining the lowest RMSE across all datasets with an average of 0.019. These findings underscore the effectiveness of combining VMD with linear models for superior time-series forecasting.
Hybrid of DiffStride and Spectral Pooling in Convolutional Neural Networks
Jan 17, 2024Stride determines the distance between adjacent filter positions as the filter moves across the input. A fixed stride causes important information contained in the image can not be captured, so that important information is not classified. Therefore, in previous research, the DiffStride Method was applied, namely the Strided Convolution Method with which it can learn its own stride value. Severe Quantization and a constraining lower bound on preserved information are arises with Max Pooling Downsampling Method. Spectral Pooling reduce the constraint lower bound on preserved information by cutting off the representation in the frequency domain. In this research a CNN Model is proposed with the Downsampling Learnable Stride Technique performed by Backpropagation combined with the Spectral Pooling Technique. Diffstride and Spectral Pooling techniques are expected to maintain most of the information contained in the image. In this study, we compare the Hybrid Method, which is a combined implementation of Spectral Pooling and DiffStride against the Baseline Method, which is the DiffStride implementation on ResNet 18. The accuracy result of the DiffStride combination with Spectral Pooling improves over DiffStride which is baseline method by 0.0094. This shows that the Hybrid Method can maintain most of the information by cutting of the representation in the frequency domain and determine the stride of the learning result through Backpropagation.
Learning-Augmented K-Means Clustering Using Dimensional Reduction
Jan 06, 2024



Learning augmented is a machine learning concept built to improve the performance of a method or model, such as enhancing its ability to predict and generalize data or features, or testing the reliability of the method by introducing noise and other factors. On the other hand, clustering is a fundamental aspect of data analysis and has long been used to understand the structure of large datasets. Despite its long history, the k-means algorithm still faces challenges. One approach, as suggested by Ergun et al,is to use a predictor to minimize the sum of squared distances between each data point and a specified centroid. However, it is known that the computational cost of this algorithm increases with the value of k, and it often gets stuck in local minima. In response to these challenges, we propose a solution to reduce the dimensionality of the dataset using Principal Component Analysis (PCA). It is worth noting that when using k values of 10 and 25, the proposed algorithm yields lower cost results compared to running it without PCA. "Principal component analysis (PCA) is the problem of fitting a low-dimensional affine subspace to a set of data points in a high-dimensional space. PCA is well-established in the literature and has become one of the most useful tools for data modeling, compression, and visualization."
* acmart-LaTeX2e v1.84 17 pages with 12 figures
MAMI: Multi-Attentional Mutual-Information for Long Sequence Neuron Captioning
Jan 05, 2024



Neuron labeling is an approach to visualize the behaviour and respond of a certain neuron to a certain pattern that activates the neuron. Neuron labeling extract information about the features captured by certain neurons in a deep neural network, one of which uses the encoder-decoder image captioning approach. The encoder used can be a pretrained CNN-based model and the decoder is an RNN-based model for text generation. Previous work, namely MILAN (Mutual Information-guided Linguistic Annotation of Neuron), has tried to visualize the neuron behaviour using modified Show, Attend, and Tell (SAT) model in the encoder, and LSTM added with Bahdanau attention in the decoder. MILAN can show great result on short sequence neuron captioning, but it does not show great result on long sequence neuron captioning, so in this work, we would like to improve the performance of MILAN even more by utilizing different kind of attention mechanism and additionally adding several attention result into one, in order to combine all the advantages from several attention mechanism. Using our compound dataset, we obtained higher BLEU and F1-Score on our proposed model, achieving 17.742 and 0.4811 respectively. At some point where the model converges at the peak, our model obtained BLEU of 21.2262 and BERTScore F1-Score of 0.4870.
SparseSwin: Swin Transformer with Sparse Transformer Block
Sep 11, 2023Advancements in computer vision research have put transformer architecture as the state of the art in computer vision tasks. One of the known drawbacks of the transformer architecture is the high number of parameters, this can lead to a more complex and inefficient algorithm. This paper aims to reduce the number of parameters and in turn, made the transformer more efficient. We present Sparse Transformer (SparTa) Block, a modified transformer block with an addition of a sparse token converter that reduces the number of tokens used. We use the SparTa Block inside the Swin T architecture (SparseSwin) to leverage Swin capability to downsample its input and reduce the number of initial tokens to be calculated. The proposed SparseSwin model outperforms other state of the art models in image classification with an accuracy of 86.96%, 97.43%, and 85.35% on the ImageNet100, CIFAR10, and CIFAR100 datasets respectively. Despite its fewer parameters, the result highlights the potential of a transformer architecture using a sparse token converter with a limited number of tokens to optimize the use of the transformer and improve its performance.
IndoHerb: Indonesia Medicinal Plants Recognition using Transfer Learning and Deep Learning
Aug 03, 2023



Herbal plants are nutritious plants that can be used as an alternative to traditional disease healing. In Indonesia there are various types of herbal plants. But with the development of the times, the existence of herbal plants as traditional medicines began to be forgotten so that not everyone could recognize them. Having the ability to identify herbal plants can have many positive impacts. However, there is a problem where identifying plants can take a long time because it requires in-depth knowledge and careful examination of plant criteria. So that the application of computer vision can help identify herbal plants. Previously, research had been conducted on the introduction of herbal plants from Vietnam using several algorithms, but from these research the accuracy was not high enough. Therefore, this study intends to implement transfer learning from the Convolutional Neural Network (CNN) algorithm to classify types of herbal plants from Indonesia. This research was conducted by collecting image data of herbal plants from Indonesia independently through the Google Images search engine. After that, it will go through the data preprocessing, classification using the transfer learning method from CNN, and analysis will be carried out. The CNN transfer learning models used are ResNet34, DenseNet121, and VGG11_bn. Based on the test results of the three models, it was found that DenseNet121 was the model with the highest accuracy, which was 87.4%. In addition, testing was also carried out using the scratch model and obtained an accuracy of 43.53%. The Hyperparameter configuration used in this test is the ExponentialLR scheduler with a gamma value of 0.9; learning rate 0.001; Cross Entropy Loss function; Adam optimizer; and the number of epochs is 50. Indonesia Medicinal Plant Dataset can be accessed at the following link https://github.com/Salmanim20/indo_medicinal_plant