 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
Variational Mode Decomposition and Linear Embeddings are What You Need For Time-Series Forecasting
Sep 04, 2024Time-series forecasting often faces challenges due to data volatility, which can lead to inaccurate predictions. Variational Mode Decomposition (VMD) has emerged as a promising technique to mitigate volatility by decomposing data into distinct modes, thereby enhancing forecast accuracy. In this study, we integrate VMD with linear models to develop a robust forecasting framework. Our approach is evaluated on 13 diverse datasets, including ETTm2, WindTurbine, M4, and 10 air quality datasets from various Southeast Asian cities. The effectiveness of the VMD strategy is assessed by comparing Root Mean Squared Error (RMSE) values from models utilizing VMD against those without it. Additionally, we benchmark linear-based models against well-known neural network architectures such as LSTM, Bidirectional LSTM, and RNN. The results demonstrate a significant reduction in RMSE across nearly all models following VMD application. Notably, the Linear + VMD model achieved the lowest average RMSE in univariate forecasting at 0.619. In multivariate forecasting, the DLinear + VMD model consistently outperformed others, attaining the lowest RMSE across all datasets with an average of 0.019. These findings underscore the effectiveness of combining VMD with linear models for superior time-series forecasting.
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Dec 20, 2022We present NusaCrowd, a collaborative initiative to collect and unite existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have has brought together 137 datasets and 117 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their effectiveness has been demonstrated in multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and its local languages. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and its local languages. Our work is intended to help advance natural language processing research in under-represented languages.
ParaCotta: Synthetic Multilingual Paraphrase Corpora from the Most Diverse Translation Sample Pair
May 10, 2022
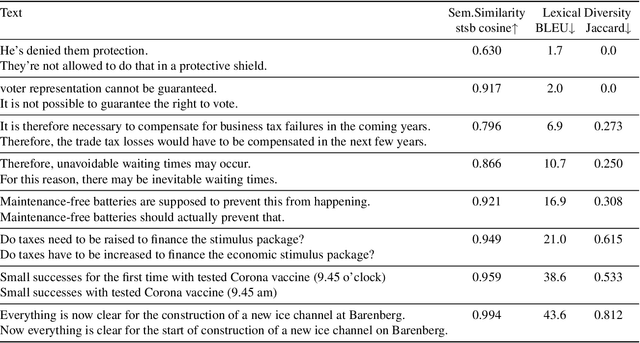
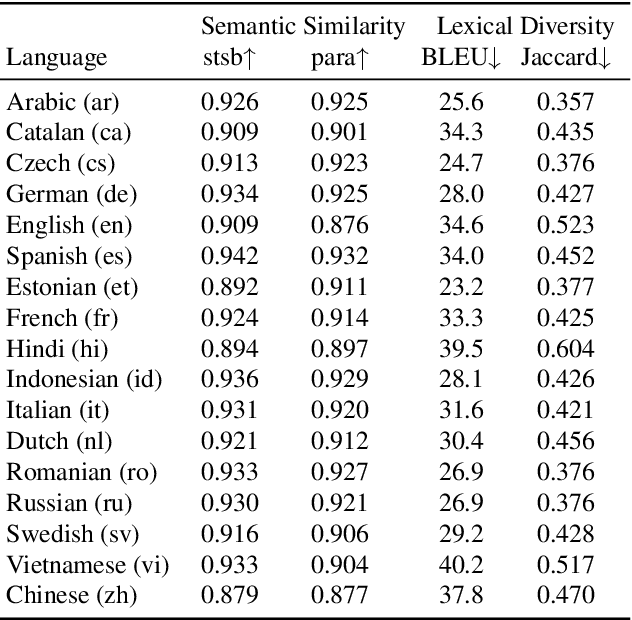
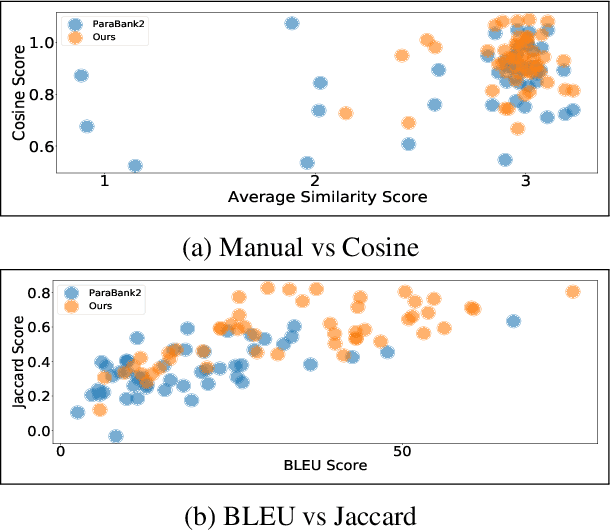
We release our synthetic parallel paraphrase corpus across 17 languages: Arabic, Catalan, Czech, German, English, Spanish, Estonian, French, Hindi, Indonesian, Italian, Dutch, Romanian, Russian, Swedish, Vietnamese, and Chinese. Our method relies only on monolingual data and a neural machine translation system to generate paraphrases, hence simple to apply. We generate multiple translation samples using beam search and choose the most lexically diverse pair according to their sentence BLEU. We compare our generated corpus with the \texttt{ParaBank2}. According to our evaluation, our synthetic paraphrase pairs are semantically similar and lexically diverse.