Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaCotta: Synthetic Multilingual Paraphrase Corpora from the Most Diverse Translation Sample Pair
May 10, 2022
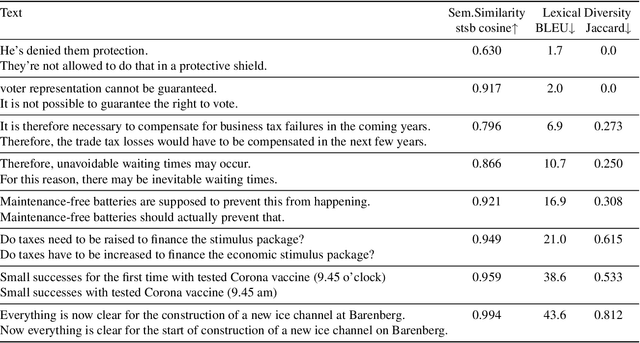
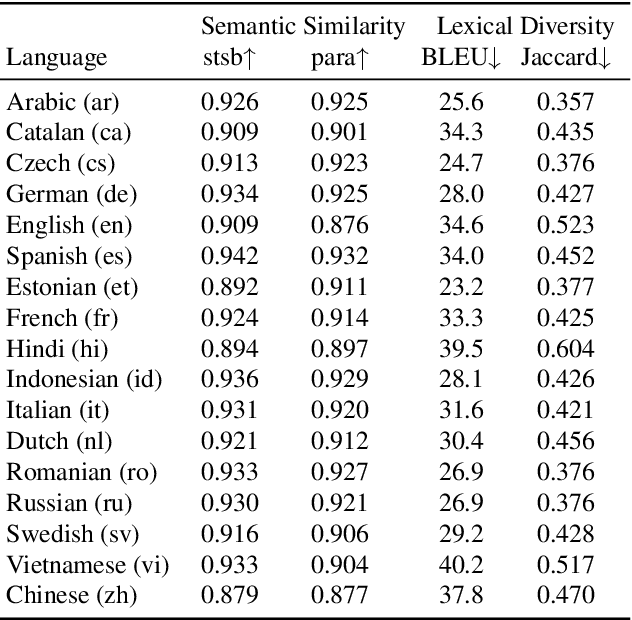
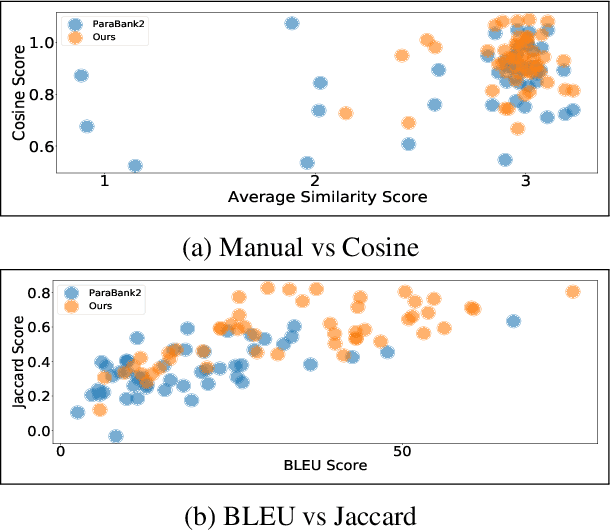
We release our synthetic parallel paraphrase corpus across 17 languages: Arabic, Catalan, Czech, German, English, Spanish, Estonian, French, Hindi, Indonesian, Italian, Dutch, Romanian, Russian, Swedish, Vietnamese, and Chinese. Our method relies only on monolingual data and a neural machine translation system to generate paraphrases, hence simple to apply. We generate multiple translation samples using beam search and choose the most lexically diverse pair according to their sentence BLEU. We compare our generated corpus with the \texttt{ParaBank2}. According to our evaluation, our synthetic paraphrase pairs are semantically similar and lexically diverse.
* 10 pages, 3 figures, 6 tables. Accepted at PACLIC 2021. (ACL
Anthology link: https://aclanthology.org/2021.paclic-1.56/)
Via