 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOPAL-ID: Indonesian Language Reasoning with Local Culture and Nuances
Paper and Code
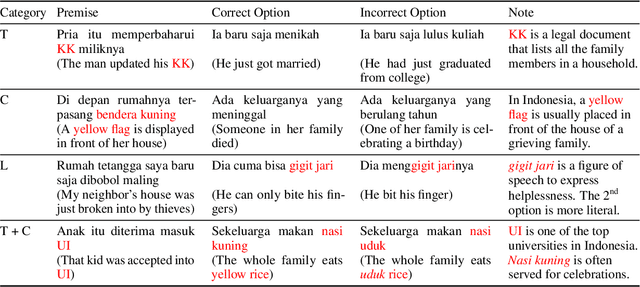

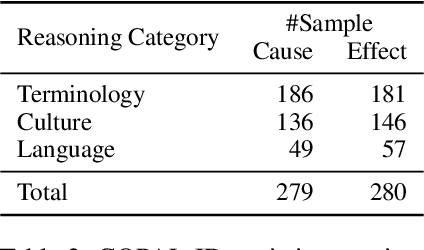
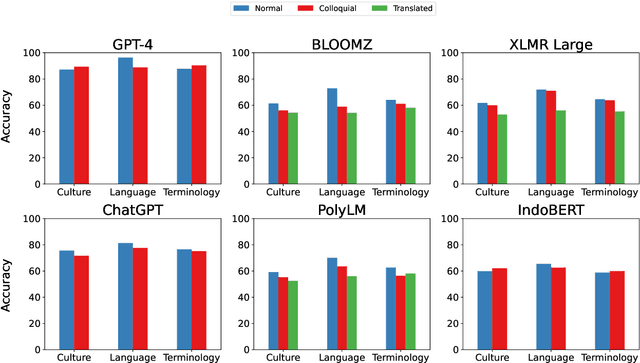
We present publicly available COPAL-ID, a novel Indonesian language common sense reasoning dataset. Unlike the previous Indonesian COPA dataset (XCOPA-ID), COPAL-ID incorporates Indonesian local and cultural nuances, and therefore, provides a more natural portrayal of day-to-day causal reasoning within the Indonesian cultural sphere. Professionally written by natives from scratch, COPAL-ID is more fluent and free from awkward phrases, unlike the translated XCOPA-ID. In addition, we present COPAL-ID in both standard Indonesian and in Jakartan Indonesian--a dialect commonly used in daily conversation. COPAL-ID poses a greater challenge for existing open-sourced and closed state-of-the-art multilingual language models, yet is trivially easy for humans. Our findings suggest that even the current best open-source, multilingual model struggles to perform well, achieving 65.47% accuracy on COPAL-ID, significantly lower than on the culturally-devoid XCOPA-ID (79.40%). Despite GPT-4's impressive score, it suffers the same performance degradation compared to its XCOPA-ID score, and it still falls short of human performance. This shows that these language models are still way behind in comprehending the local nuances of Indonesian.