 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFake-O-Meter v2.0: An Open Platform for DeepFake Detection
Apr 19, 2024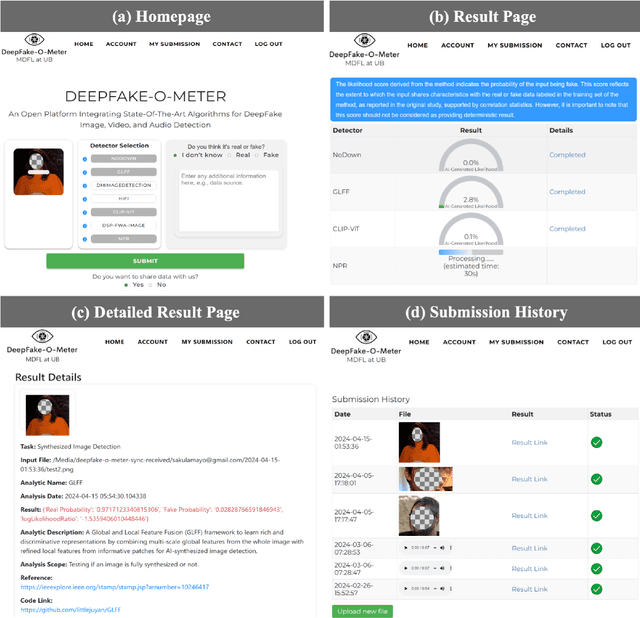
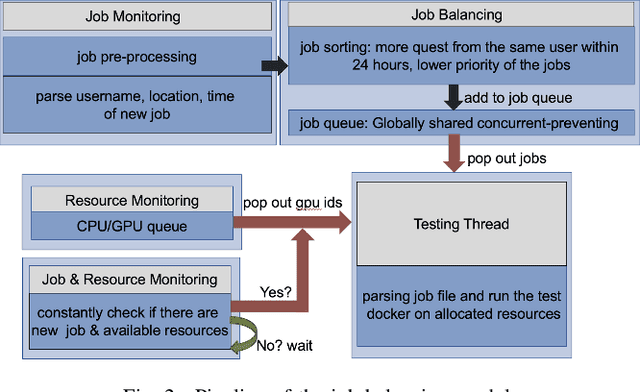
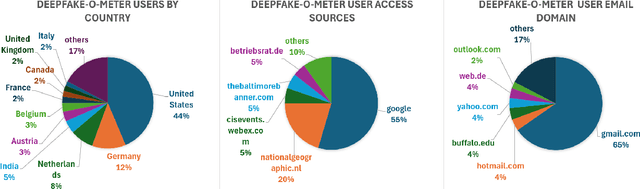
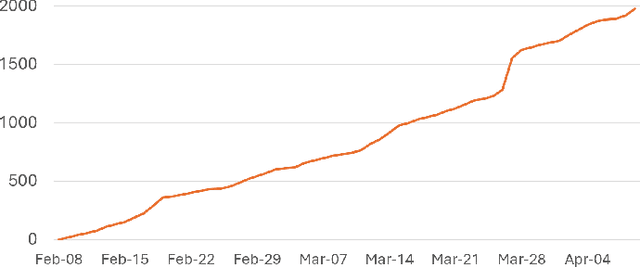
Deepfakes, as AI-generated media, have increasingly threatened media integrity and personal privacy with realistic yet fake digital content. In this work, we introduce an open-source and user-friendly online platform, DeepFake-O-Meter v2.0, that integrates state-of-the-art methods for detecting Deepfake images, videos, and audio. Built upon DeepFake-O-Meter v1.0, we have made significant upgrades and improvements in platform architecture design, including user interaction, detector integration, job balancing, and security management. The platform aims to offer everyday users a convenient service for analyzing DeepFake media using multiple state-of-the-art detection algorithms. It ensures secure and private delivery of the analysis results. Furthermore, it serves as an evaluation and benchmarking platform for researchers in digital media forensics to compare the performance of multiple algorithms on the same input. We have also conducted detailed usage analysis based on the collected data to gain deeper insights into our platform's statistics. This involves analyzing two-month trends in user activity and evaluating the processing efficiency of each detector.
Fusing Global and Local Features for Generalized AI-Synthesized Image Detection
Mar 26, 2022
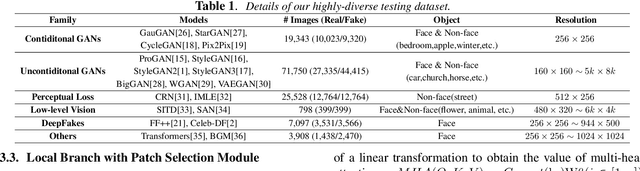
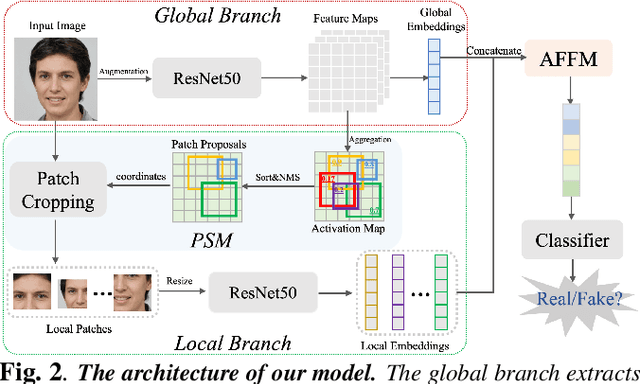
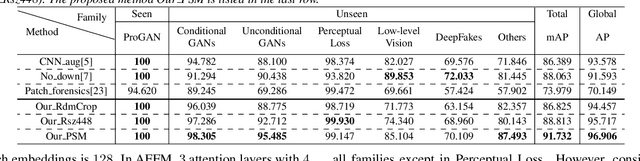
With the development of the Generative Adversarial Networks (GANs) and DeepFakes, AI-synthesized images are now of such high quality that humans can hardly distinguish them from real images. It is imperative for media forensics to develop detectors to expose them accurately. Existing detection methods have shown high performance in generated images detection, but they tend to generalize poorly in the real-world scenarios, where the synthetic images are usually generated with unseen models using unknown source data. In this work, we emphasize the importance of combining information from the whole image and informative patches in improving the generalization ability of AI-synthesized image detection. Specifically, we design a two-branch model to combine global spatial information from the whole image and local informative features from multiple patches selected by a novel patch selection module. Multi-head attention mechanism is further utilized to fuse the global and local features. We collect a highly diverse dataset synthesized by 19 models with various objects and resolutions to evaluate our model. Experimental results demonstrate the high accuracy and good generalization ability of our method in detecting generated images.
Towards To-a-T Spatio-Temporal Focus for Skeleton-Based Action Recognition
Feb 04, 2022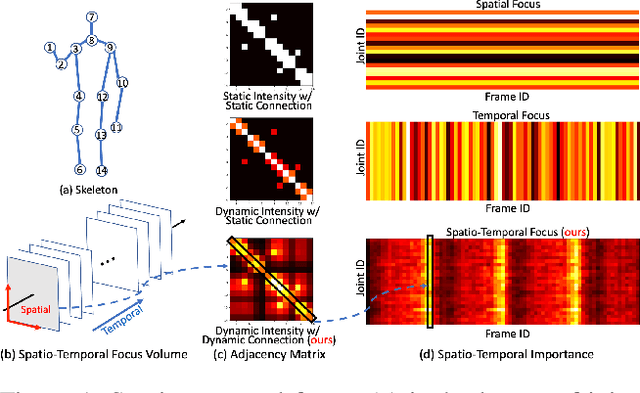

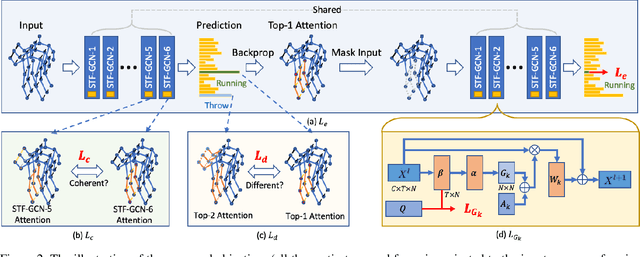
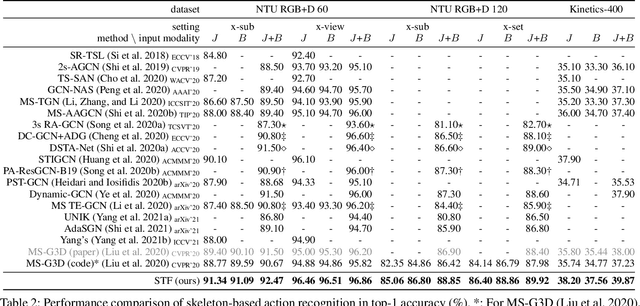
Graph Convolutional Networks (GCNs) have been widely used to model the high-order dynamic dependencies for skeleton-based action recognition. Most existing approaches do not explicitly embed the high-order spatio-temporal importance to joints' spatial connection topology and intensity, and they do not have direct objectives on their attention module to jointly learn when and where to focus on in the action sequence. To address these problems, we propose the To-a-T Spatio-Temporal Focus (STF), a skeleton-based action recognition framework that utilizes the spatio-temporal gradient to focus on relevant spatio-temporal features. We first propose the STF modules with learnable gradient-enforced and instance-dependent adjacency matrices to model the high-order spatio-temporal dynamics. Second, we propose three loss terms defined on the gradient-based spatio-temporal focus to explicitly guide the classifier when and where to look at, distinguish confusing classes, and optimize the stacked STF modules. STF outperforms the state-of-the-art methods on the NTU RGB+D 60, NTU RGB+D 120, and Kinetics Skeleton 400 datasets in all 15 settings over different views, subjects, setups, and input modalities, and STF also shows better accuracy on scarce data and dataset shifting settings.
Learnable Discrete Wavelet Pooling (LDW-Pooling) For Convolutional Networks
Sep 15, 2021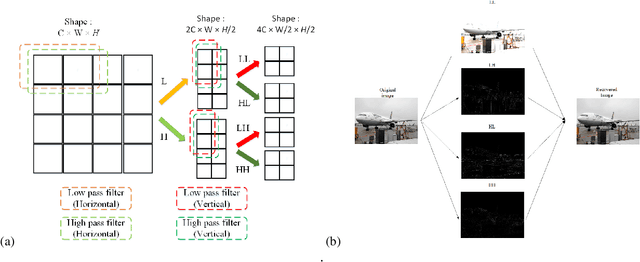

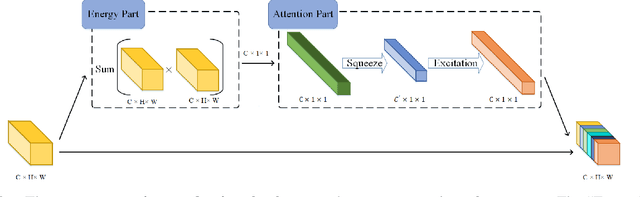
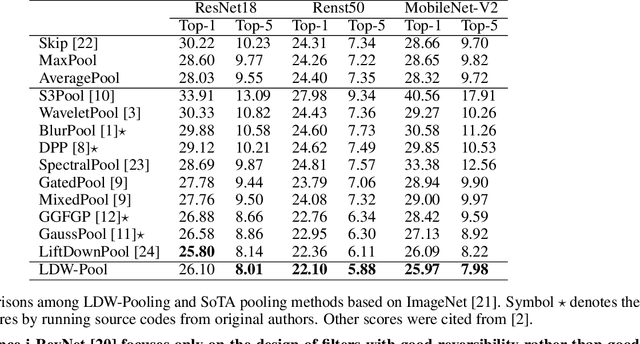
Pooling is a simple but essential layer in modern deep CNN architectures for feature aggregation and extraction. Typical CNN design focuses on the conv layers and activation functions, while leaving the pooling layers with fewer options. We introduce the Learning Discrete Wavelet Pooling (LDW-Pooling) that can be applied universally to replace standard pooling operations to better extract features with improved accuracy and efficiency. Motivated from the wavelet theory, we adopt the low-pass (L) and high-pass (H) filters horizontally and vertically for pooling on a 2D feature map. Feature signals are decomposed into four (LL, LH, HL, HH) subbands to retain features better and avoid information dropping. The wavelet transform ensures features after pooling can be fully preserved and recovered. We next adopt an energy-based attention learning to fine-select crucial and representative features. LDW-Pooling is effective and efficient when compared with other state-of-the-art pooling techniques such as WaveletPooling and LiftPooling. Extensive experimental validation shows that LDW-Pooling can be applied to a wide range of standard CNN architectures and consistently outperform standard (max, mean, mixed, and stochastic) pooling operations.
T$_k$ML-AP: Adversarial Attacks to Top-$k$ Multi-Label Learning
Jul 31, 2021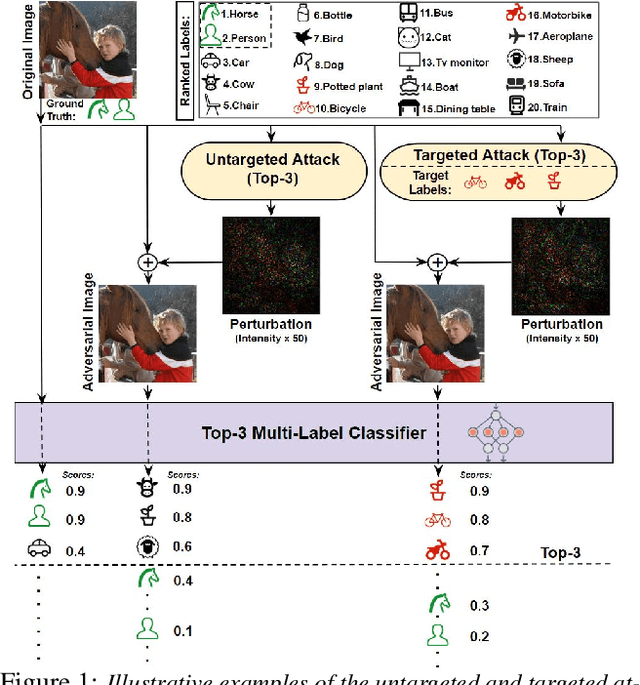
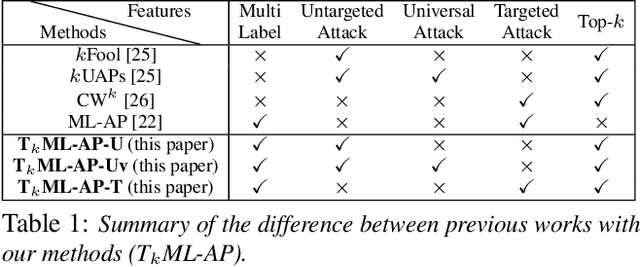

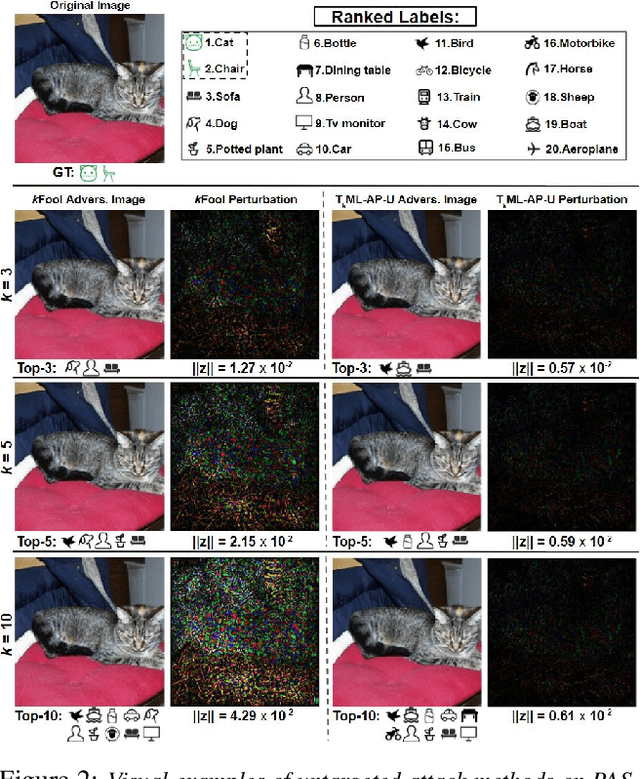
Top-$k$ multi-label learning, which returns the top-$k$ predicted labels from an input, has many practical applications such as image annotation, document analysis, and web search engine. However, the vulnerabilities of such algorithms with regards to dedicated adversarial perturbation attacks have not been extensively studied previously. In this work, we develop methods to create adversarial perturbations that can be used to attack top-$k$ multi-label learning-based image annotation systems (TkML-AP). Our methods explicitly consider the top-$k$ ranking relation and are based on novel loss functions. Experimental evaluations on large-scale benchmark datasets including PASCAL VOC and MS COCO demonstrate the effectiveness of our methods in reducing the performance of state-of-the-art top-$k$ multi-label learning methods, under both untargeted and targeted attacks.
Multi-Scale Structure-Aware Network for Human Pose Estimation
Sep 16, 2018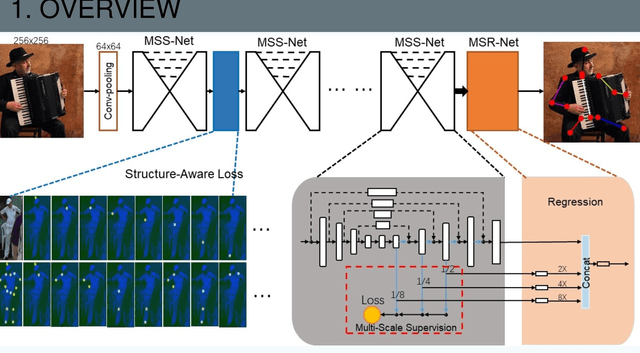

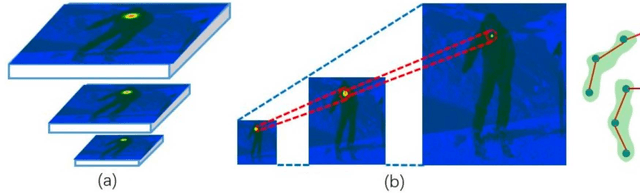

We develop a robust multi-scale structure-aware neural network for human pose estimation. This method improves the recent deep conv-deconv hourglass models with four key improvements: (1) multi-scale supervision to strengthen contextual feature learning in matching body keypoints by combining feature heatmaps across scales, (2) multi-scale regression network at the end to globally optimize the structural matching of the multi-scale features, (3) structure-aware loss used in the intermediate supervision and at the regression to improve the matching of keypoints and respective neighbors to infer a higher-order matching configurations, and (4) a keypoint masking training scheme that can effectively fine-tune our network to robustly localize occluded keypoints via adjacent matches. Our method can effectively improve state-of-the-art pose estimation methods that suffer from difficulties in scale varieties, occlusions, and complex multi-person scenarios. This multi-scale supervision tightly integrates with the regression network to effectively (i) localize keypoints using the ensemble of multi-scale features, and (ii) infer global pose configuration by maximizing structural consistencies across multiple keypoints and scales. The keypoint masking training enhances these advantages to focus learning on hard occlusion samples. Our method achieves the leading position in the MPII challenge leaderboard among the state-of-the-art methods.
Multi-Scale Supervised Network for Human Pose Estimation
Aug 05, 2018
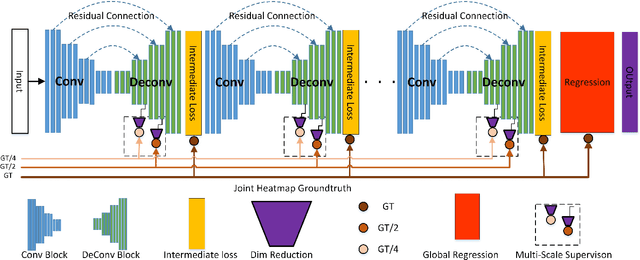
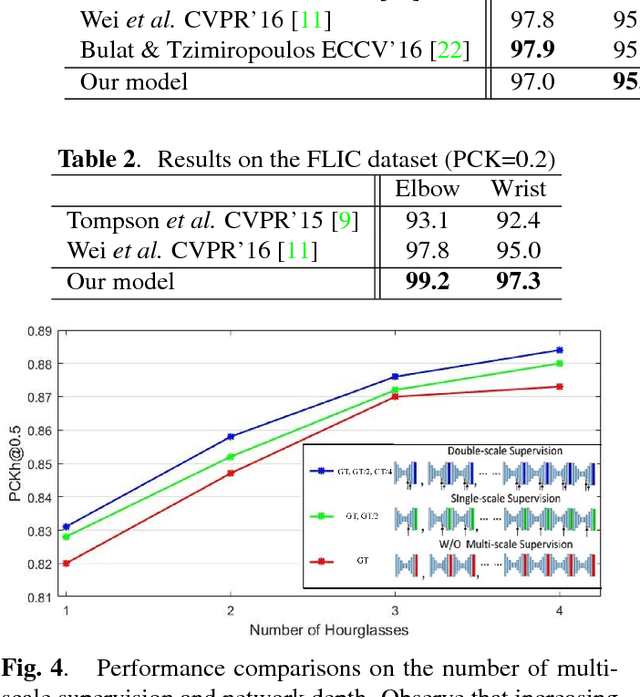

Human pose estimation is an important topic in computer vision with many applications including gesture and activity recognition. However, pose estimation from image is challenging due to appearance variations, occlusions, clutter background, and complex activities. To alleviate these problems, we develop a robust pose estimation method based on the recent deep conv-deconv modules with two improvements: (1) multi-scale supervision of body keypoints, and (2) a global regression to improve structural consistency of keypoints. We refine keypoint detection heatmaps using layer-wise multi-scale supervision to better capture local contexts. Pose inference via keypoint association is optimized globally using a regression network at the end. Our method can effectively disambiguate keypoint matches in close proximity including the mismatch of left-right body parts, and better infer occluded parts. Experimental results show that our method achieves competitive performance among state-of-the-art methods on the MPII and FLIC datasets.