 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASVspoof 5: Design, Collection and Validation of Resources for Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Feb 13, 2025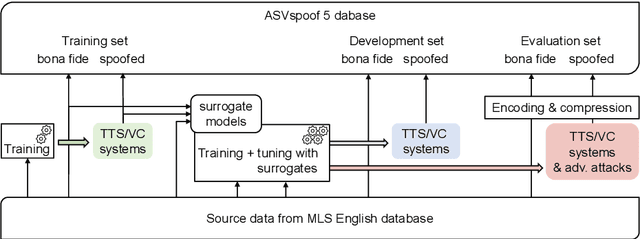

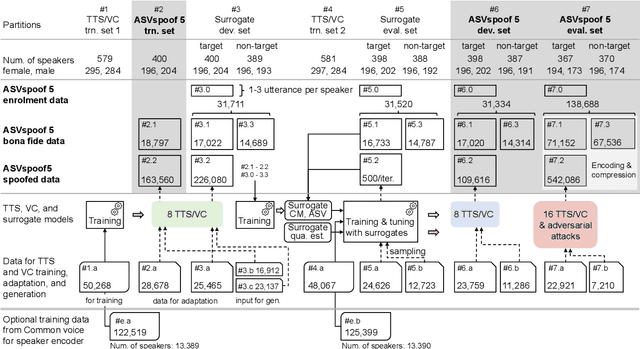
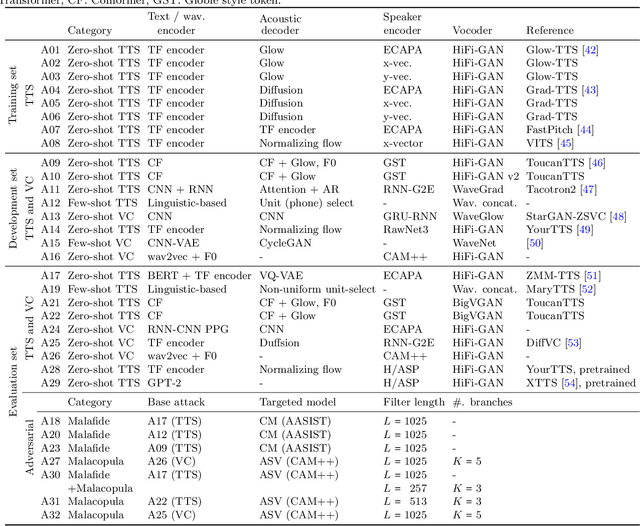
ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake attacks as well as the design of detection solutions. We introduce the ASVspoof 5 database which is generated in crowdsourced fashion from data collected in diverse acoustic conditions (cf. studio-quality data for earlier ASVspoof databases) and from ~2,000 speakers (cf. ~100 earlier). The database contains attacks generated with 32 different algorithms, also crowdsourced, and optimised to varying degrees using new surrogate detection models. Among them are attacks generated with a mix of legacy and contemporary text-to-speech synthesis and voice conversion models, in addition to adversarial attacks which are incorporated for the first time. ASVspoof 5 protocols comprise seven speaker-disjoint partitions. They include two distinct partitions for the training of different sets of attack models, two more for the development and evaluation of surrogate detection models, and then three additional partitions which comprise the ASVspoof 5 training, development and evaluation sets. An auxiliary set of data collected from an additional 30k speakers can also be used to train speaker encoders for the implementation of attack algorithms. Also described herein is an experimental validation of the new ASVspoof 5 database using a set of automatic speaker verification and spoof/deepfake baseline detectors. With the exception of protocols and tools for the generation of spoofed/deepfake speech, the resources described in this paper, already used by participants of the ASVspoof 5 challenge in 2024, are now all freely available to the community.
DeepFake-O-Meter v2.0: An Open Platform for DeepFake Detection
Apr 19, 2024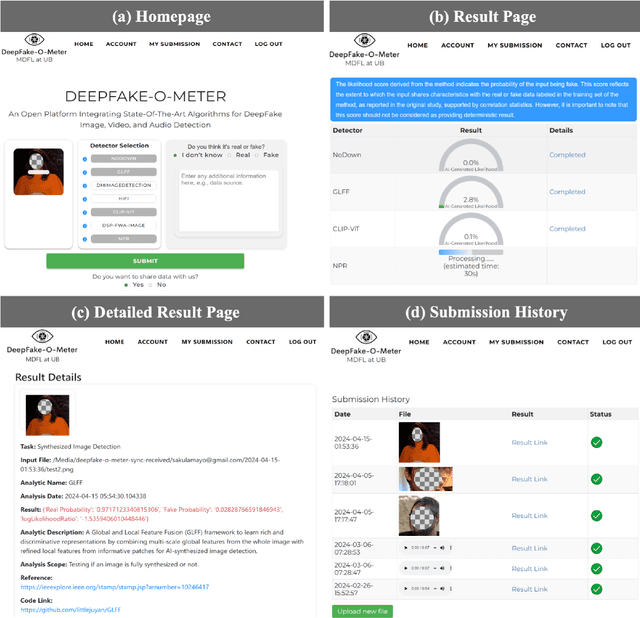
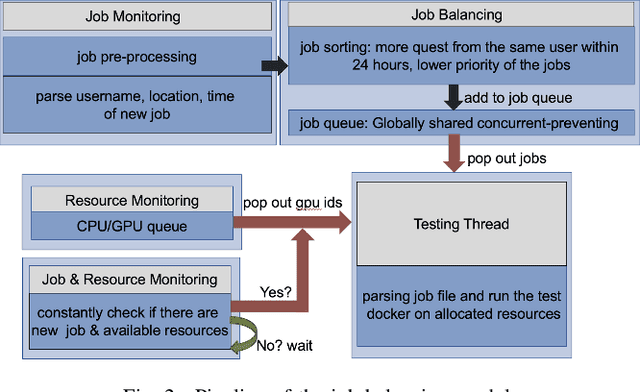
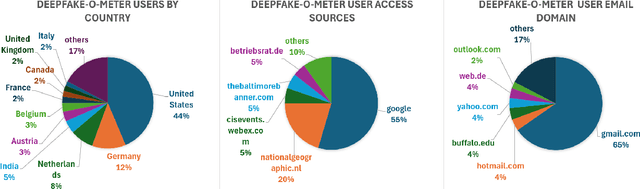
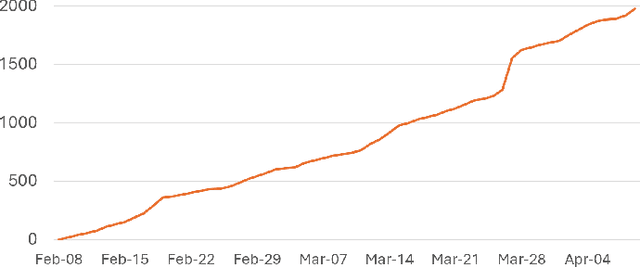
Deepfakes, as AI-generated media, have increasingly threatened media integrity and personal privacy with realistic yet fake digital content. In this work, we introduce an open-source and user-friendly online platform, DeepFake-O-Meter v2.0, that integrates state-of-the-art methods for detecting Deepfake images, videos, and audio. Built upon DeepFake-O-Meter v1.0, we have made significant upgrades and improvements in platform architecture design, including user interaction, detector integration, job balancing, and security management. The platform aims to offer everyday users a convenient service for analyzing DeepFake media using multiple state-of-the-art detection algorithms. It ensures secure and private delivery of the analysis results. Furthermore, it serves as an evaluation and benchmarking platform for researchers in digital media forensics to compare the performance of multiple algorithms on the same input. We have also conducted detailed usage analysis based on the collected data to gain deeper insights into our platform's statistics. This involves analyzing two-month trends in user activity and evaluating the processing efficiency of each detector.
AI-Synthesized Voice Detection Using Neural Vocoder Artifacts
Apr 27, 2023



Advancements in AI-synthesized human voices have created a growing threat of impersonation and disinformation, making it crucial to develop methods to detect synthetic human voices. This study proposes a new approach to identifying synthetic human voices by detecting artifacts of vocoders in audio signals. Most DeepFake audio synthesis models use a neural vocoder, a neural network that generates waveforms from temporal-frequency representations like mel-spectrograms. By identifying neural vocoder processing in audio, we can determine if a sample is synthesized. To detect synthetic human voices, we introduce a multi-task learning framework for a binary-class RawNet2 model that shares the feature extractor with a vocoder identification module. By treating vocoder identification as a pretext task, we constrain the feature extractor to focus on vocoder artifacts and provide discriminative features for the final binary classifier. Our experiments show that the improved RawNet2 model based on vocoder identification achieves high classification performance on the binary task overall.
Exposing AI-Synthesized Human Voices Using Neural Vocoder Artifacts
Feb 18, 2023The advancements of AI-synthesized human voices have introduced a growing threat of impersonation and disinformation. It is therefore of practical importance to developdetection methods for synthetic human voices. This work proposes a new approach to detect synthetic human voices based on identifying artifacts of neural vocoders in audio signals. A neural vocoder is a specially designed neural network that synthesizes waveforms from temporal-frequency representations, e.g., mel-spectrograms. The neural vocoder is a core component in most DeepFake audio synthesis models. Hence the identification of neural vocoder processing implies that an audio sample may have been synthesized. To take advantage of the vocoder artifacts for synthetic human voice detection, we introduce a multi-task learning framework for a binary-class RawNet2 model that shares the front-end feature extractor with a vocoder identification module. We treat the vocoder identification as a pretext task to constrain the front-end feature extractor to focus on vocoder artifacts and provide discriminative features for the final binary classifier. Our experiments show that the improved RawNet2 model based on vocoder identification achieves an overall high classification performance on the binary task.