 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCPNet: An Interpretable Classifier via Multi-Level Concept Prototypes
Apr 13, 2024Recent advancements in post-hoc and inherently interpretable methods have markedly enhanced the explanations of black box classifier models. These methods operate either through post-analysis or by integrating concept learning during model training. Although being effective in bridging the semantic gap between a model's latent space and human interpretation, these explanation methods only partially reveal the model's decision-making process. The outcome is typically limited to high-level semantics derived from the last feature map. We argue that the explanations lacking insights into the decision processes at low and mid-level features are neither fully faithful nor useful. Addressing this gap, we introduce the Multi-Level Concept Prototypes Classifier (MCPNet), an inherently interpretable model. MCPNet autonomously learns meaningful concept prototypes across multiple feature map levels using Centered Kernel Alignment (CKA) loss and an energy-based weighted PCA mechanism, and it does so without reliance on predefined concept labels. Further, we propose a novel classifier paradigm that learns and aligns multi-level concept prototype distributions for classification purposes via Class-aware Concept Distribution (CCD) loss. Our experiments reveal that our proposed MCPNet while being adaptable to various model architectures, offers comprehensive multi-level explanations while maintaining classification accuracy. Additionally, its concept distribution-based classification approach shows improved generalization capabilities in few-shot classification scenarios.
SARAS-Net: Scale and Relation Aware Siamese Network for Change Detection
Dec 02, 2022


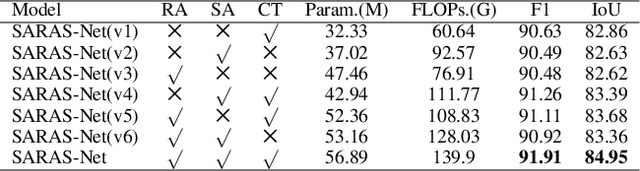
Change detection (CD) aims to find the difference between two images at different times and outputs a change map to represent whether the region has changed or not. To achieve a better result in generating the change map, many State-of-The-Art (SoTA) methods design a deep learning model that has a powerful discriminative ability. However, these methods still get lower performance because they ignore spatial information and scaling changes between objects, giving rise to blurry or wrong boundaries. In addition to these, they also neglect the interactive information of two different images. To alleviate these problems, we propose our network, the Scale and Relation-Aware Siamese Network (SARAS-Net) to deal with this issue. In this paper, three modules are proposed that include relation-aware, scale-aware, and cross-transformer to tackle the problem of scene change detection more effectively. To verify our model, we tested three public datasets, including LEVIR-CD, WHU-CD, and DSFIN, and obtained SoTA accuracy. Our code is available at https://github.com/f64051041/SARAS-Net.
Scale-Aware Crowd Counting Using a Joint Likelihood Density Map and Synthetic Fusion Pyramid Network
Nov 13, 2022We develop a Synthetic Fusion Pyramid Network (SPF-Net) with a scale-aware loss function design for accurate crowd counting. Existing crowd-counting methods assume that the training annotation points were accurate and thus ignore the fact that noisy annotations can lead to large model-learning bias and counting error, especially for counting highly dense crowds that appear far away. To the best of our knowledge, this work is the first to properly handle such noise at multiple scales in end-to-end loss design and thus push the crowd counting state-of-the-art. We model the noise of crowd annotation points as a Gaussian and derive the crowd probability density map from the input image. We then approximate the joint distribution of crowd density maps with the full covariance of multiple scales and derive a low-rank approximation for tractability and efficient implementation. The derived scale-aware loss function is used to train the SPF-Net. We show that it outperforms various loss functions on four public datasets: UCF-QNRF, UCF CC 50, NWPU and ShanghaiTech A-B datasets. The proposed SPF-Net can accurately predict the locations of people in the crowd, despite training on noisy training annotations.
Cooperative Reinforcement Learning on Traffic Signal Control
May 23, 2022

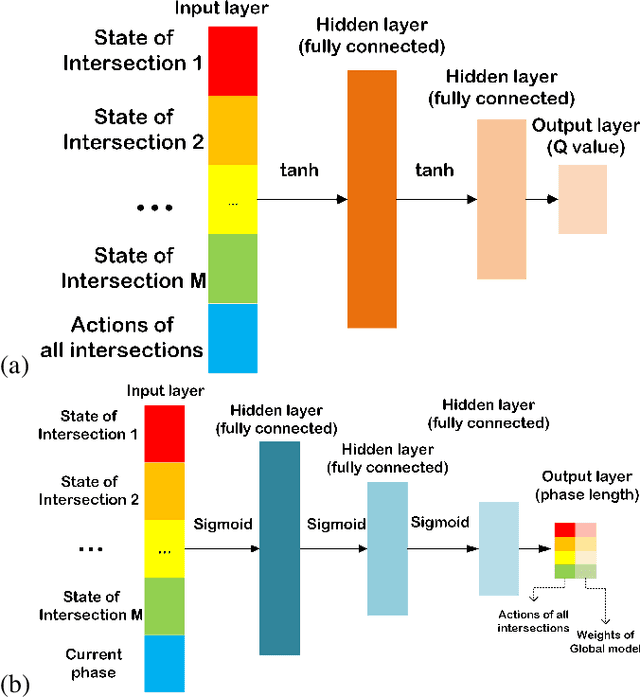

Traffic signal control is a challenging real-world problem aiming to minimize overall travel time by coordinating vehicle movements at road intersections. Existing traffic signal control systems in use still rely heavily on oversimplified information and rule-based methods. Specifically, the periodicity of green/red light alternations can be considered as a prior for better planning of each agent in policy optimization. To better learn such adaptive and predictive priors, traditional RL-based methods can only return a fixed length from predefined action pool with only local agents. If there is no cooperation between these agents, some agents often make conflicts to other agents and thus decrease the whole throughput. This paper proposes a cooperative, multi-objective architecture with age-decaying weights to better estimate multiple reward terms for traffic signal control optimization, which termed COoperative Multi-Objective Multi-Agent Deep Deterministic Policy Gradient (COMMA-DDPG). Two types of agents running to maximize rewards of different goals - one for local traffic optimization at each intersection and the other for global traffic waiting time optimization. The global agent is used to guide the local agents as a means for aiding faster learning but not used in the inference phase. We also provide an analysis of solution existence together with convergence proof for the proposed RL optimization. Evaluation is performed using real-world traffic data collected using traffic cameras from an Asian country. Our method can effectively reduce the total delayed time by 60\%. Results demonstrate its superiority when compared to SoTA methods.
Learnable Discrete Wavelet Pooling (LDW-Pooling) For Convolutional Networks
Sep 15, 2021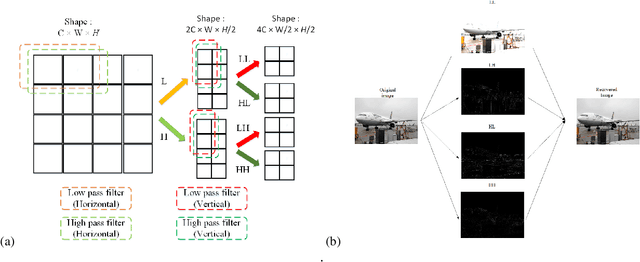

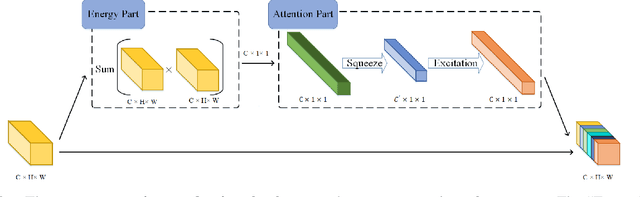
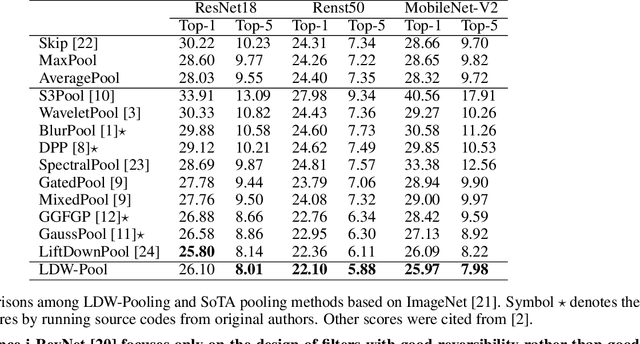
Pooling is a simple but essential layer in modern deep CNN architectures for feature aggregation and extraction. Typical CNN design focuses on the conv layers and activation functions, while leaving the pooling layers with fewer options. We introduce the Learning Discrete Wavelet Pooling (LDW-Pooling) that can be applied universally to replace standard pooling operations to better extract features with improved accuracy and efficiency. Motivated from the wavelet theory, we adopt the low-pass (L) and high-pass (H) filters horizontally and vertically for pooling on a 2D feature map. Feature signals are decomposed into four (LL, LH, HL, HH) subbands to retain features better and avoid information dropping. The wavelet transform ensures features after pooling can be fully preserved and recovered. We next adopt an energy-based attention learning to fine-select crucial and representative features. LDW-Pooling is effective and efficient when compared with other state-of-the-art pooling techniques such as WaveletPooling and LiftPooling. Extensive experimental validation shows that LDW-Pooling can be applied to a wide range of standard CNN architectures and consistently outperform standard (max, mean, mixed, and stochastic) pooling operations.