 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Compress Prompt in Natural Language Formats
Paper and Code
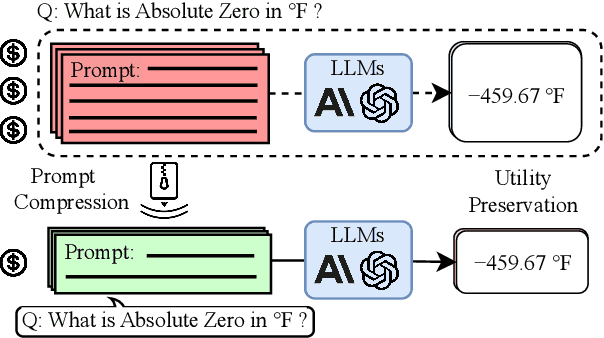

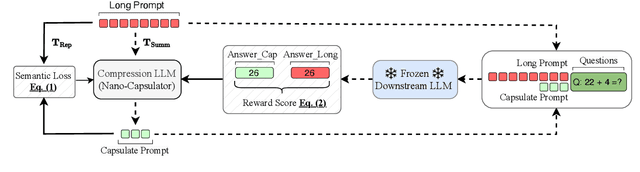
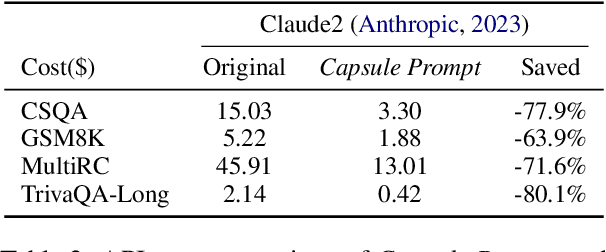
Large language models (LLMs) are great at processing multiple natural language processing tasks, but their abilities are constrained by inferior performance with long context, slow inference speed, and the high cost of computing the results. Deploying LLMs with precise and informative context helps users process large-scale datasets more effectively and cost-efficiently. Existing works rely on compressing long prompt contexts into soft prompts. However, soft prompt compression encounters limitations in transferability across different LLMs, especially API-based LLMs. To this end, this work aims to compress lengthy prompts in the form of natural language with LLM transferability. This poses two challenges: (i) Natural Language (NL) prompts are incompatible with back-propagation, and (ii) NL prompts lack flexibility in imposing length constraints. In this work, we propose a Natural Language Prompt Encapsulation (Nano-Capsulator) framework compressing original prompts into NL formatted Capsule Prompt while maintaining the prompt utility and transferability. Specifically, to tackle the first challenge, the Nano-Capsulator is optimized by a reward function that interacts with the proposed semantics preserving loss. To address the second question, the Nano-Capsulator is optimized by a reward function featuring length constraints. Experimental results demonstrate that the Capsule Prompt can reduce 81.4% of the original length, decrease inference latency up to 4.5x, and save 80.1% of budget overheads while providing transferability across diverse LLMs and different datasets.