 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection: A Data Perspective
Aug 26, 2018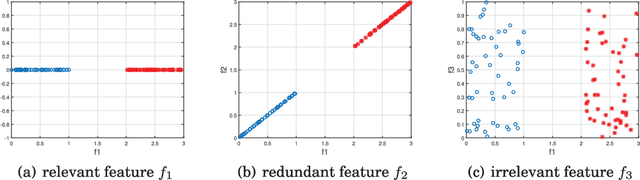
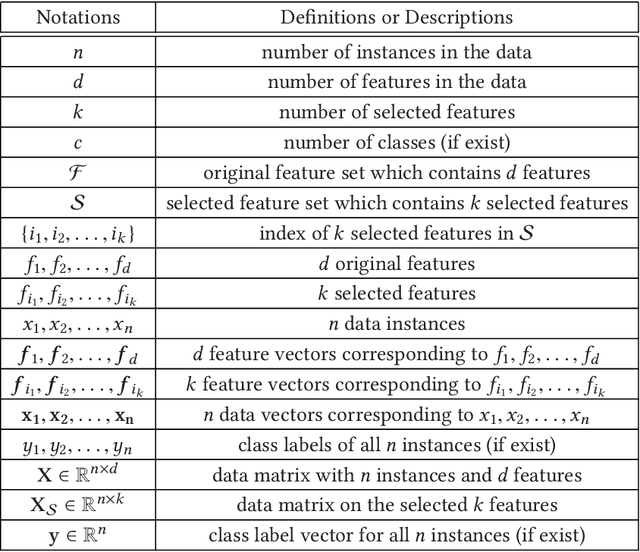
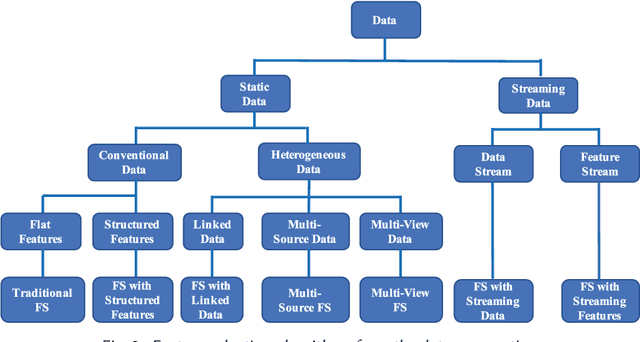
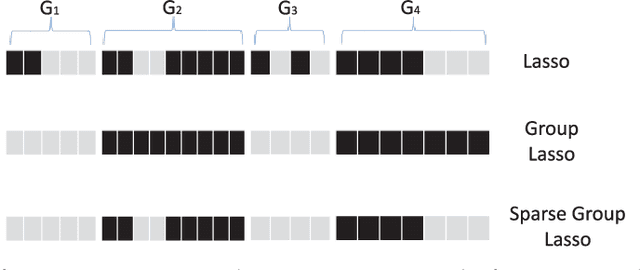
Feature selection, as a data preprocessing strategy, has been proven to be effective and efficient in preparing data (especially high-dimensional data) for various data mining and machine learning problems. The objectives of feature selection include: building simpler and more comprehensible models, improving data mining performance, and preparing clean, understandable data. The recent proliferation of big data has presented some substantial challenges and opportunities to feature selection. In this survey, we provide a comprehensive and structured overview of recent advances in feature selection research. Motivated by current challenges and opportunities in the era of big data, we revisit feature selection research from a data perspective and review representative feature selection algorithms for conventional data, structured data, heterogeneous data and streaming data. Methodologically, to emphasize the differences and similarities of most existing feature selection algorithms for conventional data, we categorize them into four main groups: similarity based, information theoretical based, sparse learning based and statistical based methods. To facilitate and promote the research in this community, we also present an open-source feature selection repository that consists of most of the popular feature selection algorithms (\url{http://featureselection.asu.edu/}). Also, we use it as an example to show how to evaluate feature selection algorithms. At the end of the survey, we present a discussion about some open problems and challenges that require more attention in future research.