 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the workflow, opportunities and challenges of developing foundation model in geophysics
Apr 24, 2025Foundation models, as a mainstream technology in artificial intelligence, have demonstrated immense potential across various domains in recent years, particularly in handling complex tasks and multimodal data. In the field of geophysics, although the application of foundation models is gradually expanding, there is currently a lack of comprehensive reviews discussing the full workflow of integrating foundation models with geophysical data. To address this gap, this paper presents a complete framework that systematically explores the entire process of developing foundation models in conjunction with geophysical data. From data collection and preprocessing to model architecture selection, pre-training strategies, and model deployment, we provide a detailed analysis of the key techniques and methodologies at each stage. In particular, considering the diversity, complexity, and physical consistency constraints of geophysical data, we discuss targeted solutions to address these challenges. Furthermore, we discuss how to leverage the transfer learning capabilities of foundation models to reduce reliance on labeled data, enhance computational efficiency, and incorporate physical constraints into model training, thereby improving physical consistency and interpretability. Through a comprehensive summary and analysis of the current technological landscape, this paper not only fills the gap in the geophysics domain regarding a full-process review of foundation models but also offers valuable practical guidance for their application in geophysical data analysis, driving innovation and advancement in the field.
A foundation model enpowered by a multi-modal prompt engine for universal seismic geobody interpretation across surveys
Sep 08, 2024



Seismic geobody interpretation is crucial for structural geology studies and various engineering applications. Existing deep learning methods show promise but lack support for multi-modal inputs and struggle to generalize to different geobody types or surveys. We introduce a promptable foundation model for interpreting any geobodies across seismic surveys. This model integrates a pre-trained vision foundation model (VFM) with a sophisticated multi-modal prompt engine. The VFM, pre-trained on massive natural images and fine-tuned on seismic data, provides robust feature extraction for cross-survey generalization. The prompt engine incorporates multi-modal prior information to iteratively refine geobody delineation. Extensive experiments demonstrate the model's superior accuracy, scalability from 2D to 3D, and generalizability to various geobody types, including those unseen during training. To our knowledge, this is the first highly scalable and versatile multi-modal foundation model capable of interpreting any geobodies across surveys while supporting real-time interactions. Our approach establishes a new paradigm for geoscientific data interpretation, with broad potential for transfer to other tasks.
Contextual Distillation Model for Diversified Recommendation
Jun 13, 2024



The diversity of recommendation is equally crucial as accuracy in improving user experience. Existing studies, e.g., Determinantal Point Process (DPP) and Maximal Marginal Relevance (MMR), employ a greedy paradigm to iteratively select items that optimize both accuracy and diversity. However, prior methods typically exhibit quadratic complexity, limiting their applications to the re-ranking stage and are not applicable to other recommendation stages with a larger pool of candidate items, such as the pre-ranking and ranking stages. In this paper, we propose Contextual Distillation Model (CDM), an efficient recommendation model that addresses diversification, suitable for the deployment in all stages of industrial recommendation pipelines. Specifically, CDM utilizes the candidate items in the same user request as context to enhance the diversification of the results. We propose a contrastive context encoder that employs attention mechanisms to model both positive and negative contexts. For the training of CDM, we compare each target item with its context embedding and utilize the knowledge distillation framework to learn the win probability of each target item under the MMR algorithm, where the teacher is derived from MMR outputs. During inference, ranking is performed through a linear combination of the recommendation and student model scores, ensuring both diversity and efficiency. We perform offline evaluations on two industrial datasets and conduct online A/B test of CDM on the short-video platform KuaiShou. The considerable enhancements observed in both recommendation quality and diversity, as shown by metrics, provide strong superiority for the effectiveness of CDM.
TACO: Benchmarking Generalizable Bimanual Tool-ACtion-Object Understanding
Jan 16, 2024Humans commonly work with multiple objects in daily life and can intuitively transfer manipulation skills to novel objects by understanding object functional regularities. However, existing technical approaches for analyzing and synthesizing hand-object manipulation are mostly limited to handling a single hand and object due to the lack of data support. To address this, we construct TACO, an extensive bimanual hand-object-interaction dataset spanning a large variety of tool-action-object compositions for daily human activities. TACO contains 2.5K motion sequences paired with third-person and egocentric views, precise hand-object 3D meshes, and action labels. To rapidly expand the data scale, we present a fully-automatic data acquisition pipeline combining multi-view sensing with an optical motion capture system. With the vast research fields provided by TACO, we benchmark three generalizable hand-object-interaction tasks: compositional action recognition, generalizable hand-object motion forecasting, and cooperative grasp synthesis. Extensive experiments reveal new insights, challenges, and opportunities for advancing the studies of generalizable hand-object motion analysis and synthesis. Our data and code are available at https://taco2024.github.io.
SeisCLIP: A seismology foundation model pre-trained by multi-modal data for multi-purpose seismic feature extraction
Sep 05, 2023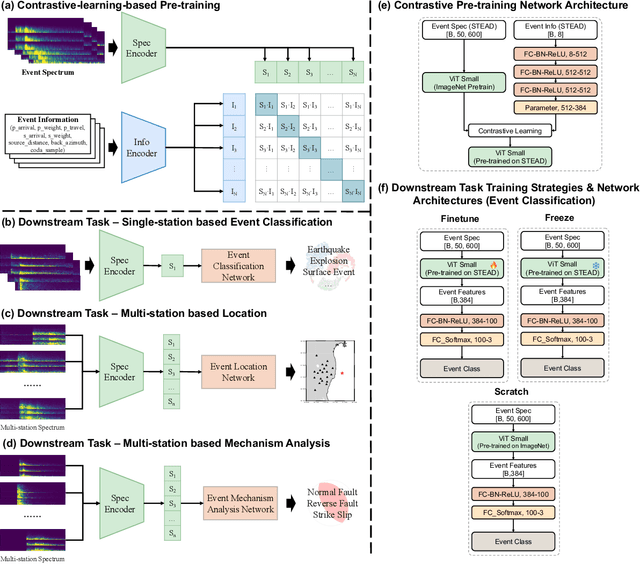

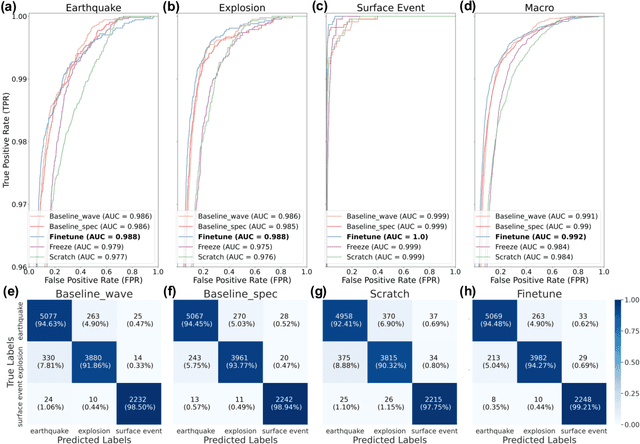
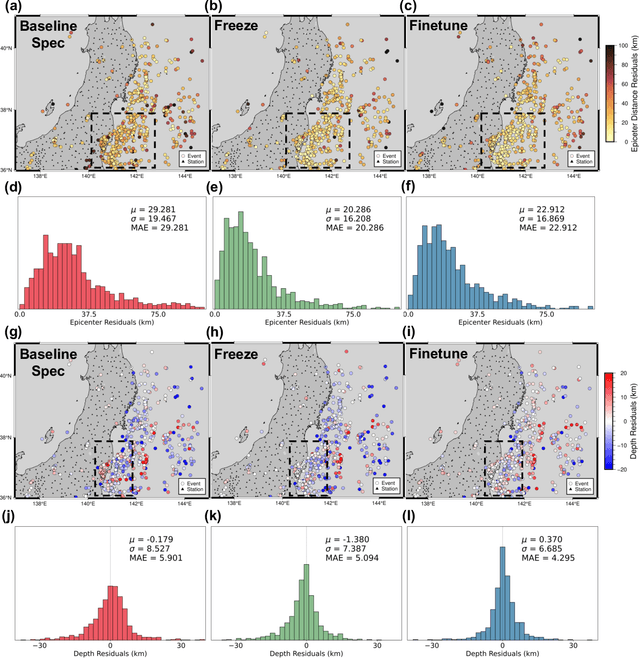
Training specific deep learning models for particular tasks is common across various domains within seismology. However, this approach encounters two limitations: inadequate labeled data for certain tasks and limited generalization across regions. To address these challenges, we develop SeisCLIP, a seismology foundation model trained through contrastive learning from multi-modal data. It consists of a transformer encoder for extracting crucial features from time-frequency seismic spectrum and an MLP encoder for integrating the phase and source information of the same event. These encoders are jointly pre-trained on a vast dataset and the spectrum encoder is subsequently fine-tuned on smaller datasets for various downstream tasks. Notably, SeisCLIP's performance surpasses that of baseline methods in event classification, localization, and focal mechanism analysis tasks, employing distinct datasets from different regions. In conclusion, SeisCLIP holds significant potential as a foundational model in the field of seismology, paving the way for innovative directions in foundation-model-based seismology research.
Multi-task multi-station earthquake monitoring: An all-in-one seismic Phase picking, Location, and Association Network (PLAN)
Jun 24, 2023



Earthquake monitoring is vital for understanding the physics of earthquakes and assessing seismic hazards. A standard monitoring workflow includes the interrelated and interdependent tasks of phase picking, association, and location. Although deep learning methods have been successfully applied to earthquake monitoring, they mostly address the tasks separately and ignore the geographic relationships among stations. Here, we propose a graph neural network that operates directly on multi-station seismic data and achieves simultaneous phase picking, association, and location. Particularly, the inter-station and inter-task physical relationships are informed in the network architecture to promote accuracy, interpretability, and physical consistency among cross-station and cross-task predictions. When applied to data from the Ridgecrest region and Japan regions, this method showed superior performance over previous deep learning-based phase-picking and localization methods. Overall, our study provides for the first time a prototype self-consistent all-in-one system of simultaneous seismic phase picking, association, and location, which has the potential for next-generation autonomous earthquake monitoring.