 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-aware Federated Learning using Knowledge Extraction and Multi-model Fusion
Paper and Code
Aug 16, 2022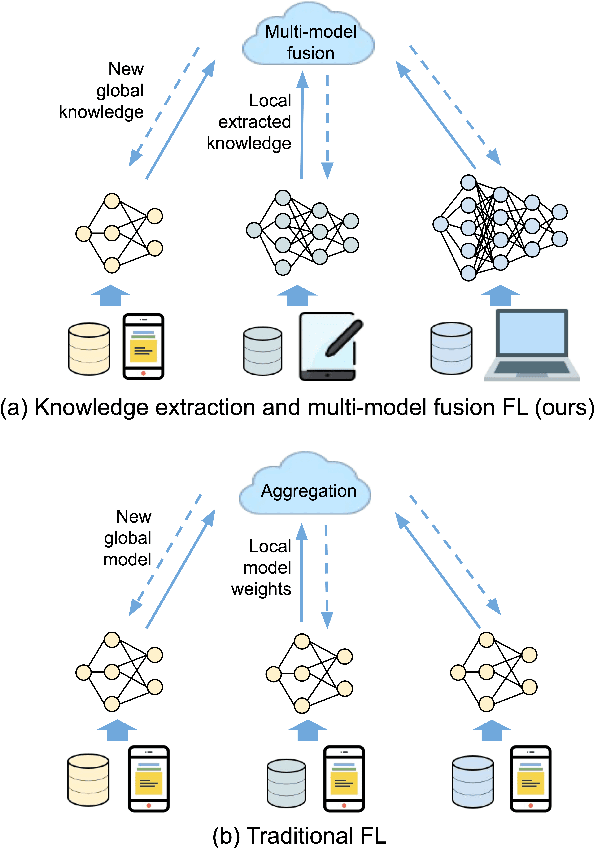
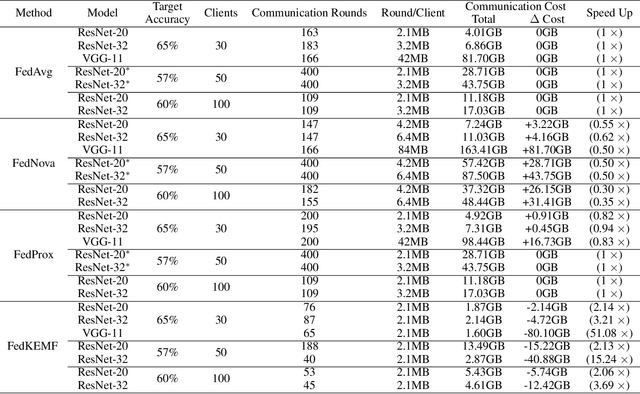
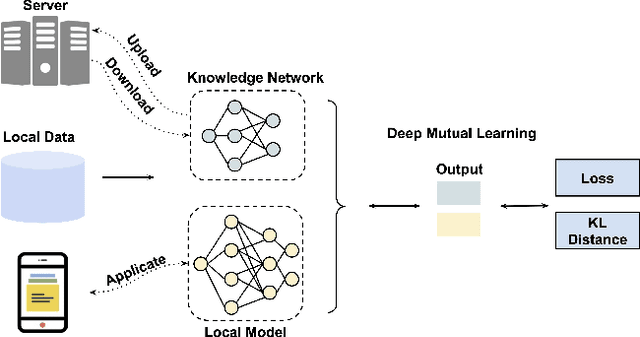
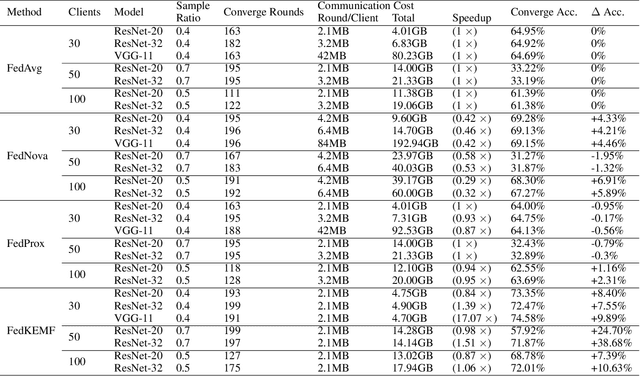
With increasing concern about user data privacy, federated learning (FL) has been developed as a unique training paradigm for training machine learning models on edge devices without access to sensitive data. Traditional FL and existing methods directly employ aggregation methods on all edges of the same models and training devices for a cloud server. Although these methods protect data privacy, they are not capable of model heterogeneity, even ignore the heterogeneous computing power, and incur steep communication costs. In this paper, we purpose a resource-aware FL to aggregate an ensemble of local knowledge extracted from edge models, instead of aggregating the weights of each local model, which is then distilled into a robust global knowledge as the server model through knowledge distillation. The local model and the global knowledge are extracted into a tiny size knowledge network by deep mutual learning. Such knowledge extraction allows the edge client to deploy a resource-aware model and perform multi-model knowledge fusion while maintaining communication efficiency and model heterogeneity. Empirical results show that our approach has significantly improved over existing FL algorithms in terms of communication cost and generalization performance in heterogeneous data and models. Our approach reduces the communication cost of VGG-11 by up to 102$\times$ and ResNet-32 by up to 30$\times$ when training ResNet-20 as the knowledge network.