 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Dynamic Pruning for Non-IID Federated Learning
Paper and Code
Jun 13, 2021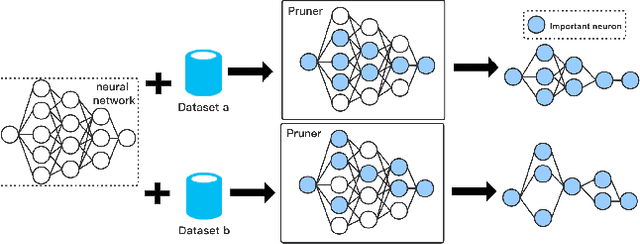
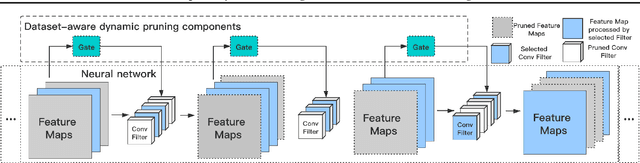
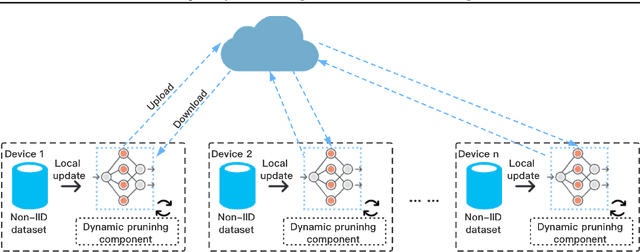
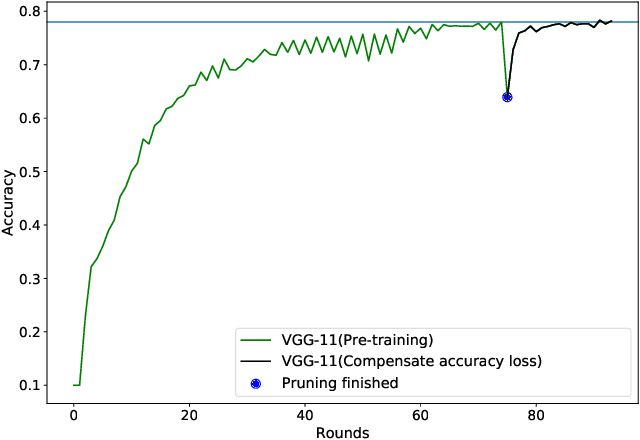
Federated Learning~(FL) has emerged as a new paradigm of training machine learning models without sacrificing data security and privacy. Learning models at edge devices such as cell phones is one of the most common use case of FL. However, the limited computing power and energy constraints of edge devices hinder the adoption of FL for both model training and deployment, especially for the resource-hungry Deep Neural Networks~(DNNs). To this end, many model compression methods have been proposed and network pruning is among the most well-known. However, a pruning policy for a given model is highly dataset-dependent, which is not suitable for non-Independent and Identically Distributed~(Non-IID) FL edge devices. In this paper, we present an adaptive pruning scheme for edge devices in an FL system, which applies dataset-aware dynamic pruning for inference acceleration on Non-IID datasets. Our evaluation shows that the proposed method accelerates inference by $2\times$~($50\%$ FLOPs reduction) while maintaining the model's quality on edge devices.