 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP3-LLM: An Integrated NPU-PIM Accelerator for LLM Inference Using Hybrid Numerical Formats
Nov 16, 2025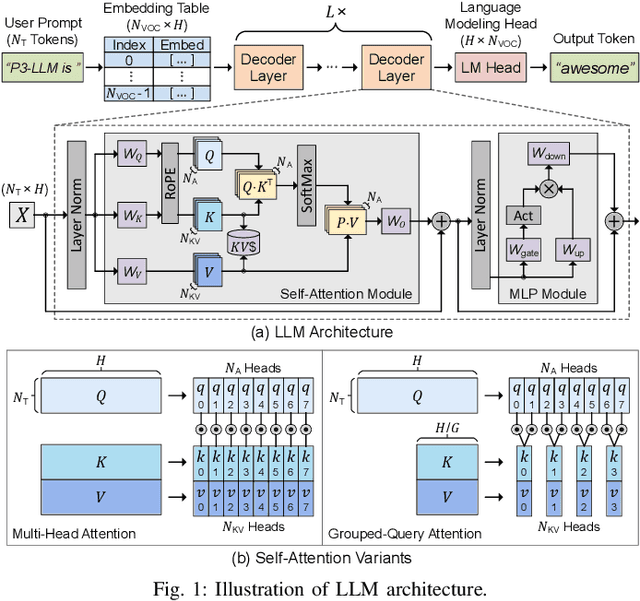
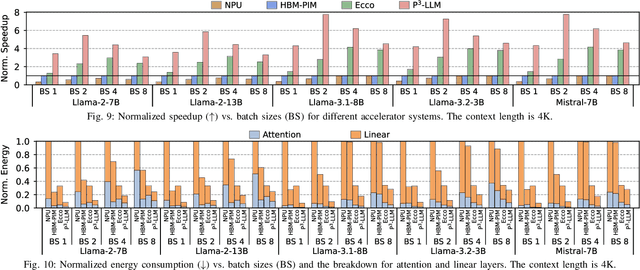
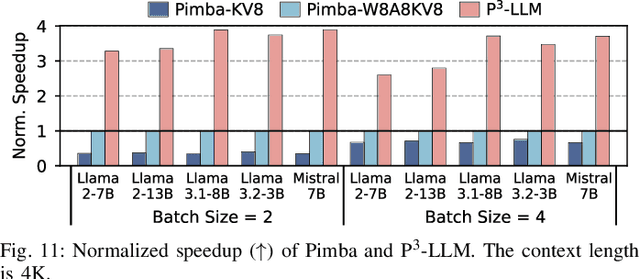
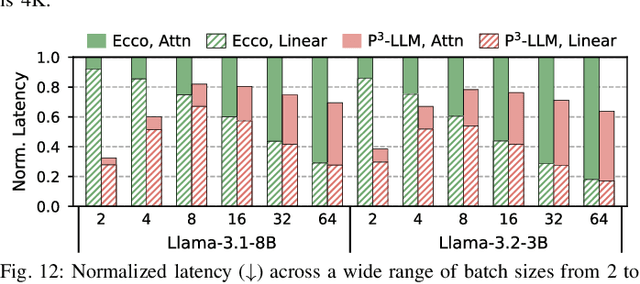
The substantial memory bandwidth and computational demands of large language models (LLMs) present critical challenges for efficient inference. To tackle this, the literature has explored heterogeneous systems that combine neural processing units (NPUs) with DRAM-based processing-in-memory (PIM) for LLM acceleration. However, existing high-precision (e.g., FP16) PIM compute units incur significant area and power overhead in DRAM technology, limiting the effective computation throughput. In this paper, we introduce P3-LLM, a novel NPU-PIM integrated accelerator for LLM inference using hybrid numerical formats. Our approach is threefold: First, we propose a flexible mixed-precision quantization scheme, which leverages hybrid numerical formats to quantize different LLM operands with high compression efficiency and minimal accuracy loss. Second, we architect an efficient PIM accelerator for P3-LLM, featuring enhanced compute units to support hybrid numerical formats. Our careful choice of numerical formats allows to co-design low-precision PIM compute units that significantly boost the computation throughput under iso-area constraints. Third, we optimize the low-precision dataflow of different LLM modules by applying operator fusion to minimize the overhead of runtime dequantization. Evaluation on a diverse set of representative LLMs and tasks demonstrates that P3-LLM achieves state-of-the-art accuracy in terms of both KV-cache quantization and weight-activation quantization. Combining the proposed quantization scheme with PIM architecture co-design, P3-LLM yields an average of $4.9\times$, $2.0\times$, and $3.4\times$ speedups over the state-of-the-art LLM accelerators HBM-PIM, Ecco, and Pimba, respectively. Our quantization code is available at https://github.com/yc2367/P3-LLM.git
The Power of Negative Zero: Datatype Customization for Quantized Large Language Models
Jan 06, 2025



Large language models (LLMs) have demonstrated remarkable performance across various machine learning tasks, quickly becoming one of the most prevalent AI workloads. Yet the substantial memory requirement of LLMs significantly hinders their deployment for end users. Post-training quantization (PTQ) serves as one of the most hardware-efficient methods to mitigate the memory and computational demands of LLMs. Although the traditional integer (INT) datatype has received widespread adoption in PTQ methods, floating-point (FP) quantization has emerged as a viable alternative thanks to its effectiveness in fitting LLM numerical distributions. However, the FP datatype in sign-magnitude binary representation contains both positive and negative zero, which constrains its representation capability, particularly under low precision (3 and 4 bits). In this paper, we extend the basic FP datatype to perform Redundant Zero Remapping (RaZeR), which remaps the negative zero FP encoding to a set of pre-defined special values to maximally utilize FP quantization encodings and to better fit LLM numerical distributions. Through careful selection of special values, RaZeR outperforms conventional asymmetric INT quantization while achieving high computational efficiency. We demonstrate that RaZeR can be seamlessly integrated with quantization algorithms for both weights and KV-cache, including advanced methods with clipping and transformations, and consistently achieve better model accuracy. Additionally, we implement a fast GEMV kernel with fused dequantization that efficiently converts the 4-bit RaZeR value to FP16 through novel bit-level manipulation. On modern GPUs, our evaluation shows that RaZeR improves the GEMV speed by up to 7.56$\times$ compared to the FP16 implementation, while achieving up to 2.72$\times$ speedup in the LLM decoding throughput.
BitMoD: Bit-serial Mixture-of-Datatype LLM Acceleration
Nov 18, 2024



Large language models (LLMs) have demonstrated remarkable performance across various machine learning tasks. Yet the substantial memory footprint of LLMs significantly hinders their deployment. In this paper, we improve the accessibility of LLMs through BitMoD, an algorithm-hardware co-design solution that enables efficient LLM acceleration at low weight precision. On the algorithm side, BitMoD introduces fine-grained data type adaptation that uses a different numerical data type to quantize a group of (e.g., 128) weights. Through the careful design of these new data types, BitMoD is able to quantize LLM weights to very low precision (e.g., 4 bits and 3 bits) while maintaining high accuracy. On the hardware side, BitMoD employs a bit-serial processing element to easily support multiple numerical precisions and data types; our hardware design includes two key innovations: First, it employs a unified representation to process different weight data types, thus reducing the hardware cost. Second, it adopts a bit-serial dequantization unit to rescale the per-group partial sum with minimal hardware overhead. Our evaluation on six representative LLMs demonstrates that BitMoD significantly outperforms state-of-the-art LLM quantization and acceleration methods. For discriminative tasks, BitMoD can quantize LLM weights to 4-bit with $<\!0.5\%$ accuracy loss on average. For generative tasks, BitMoD is able to quantize LLM weights to 3-bit while achieving better perplexity than prior LLM quantization scheme. Combining the superior model performance with an efficient accelerator design, BitMoD achieves an average of $1.69\times$ and $1.48\times$ speedups compared to prior LLM accelerators ANT and OliVe, respectively.
An Adaptable, Safe, and Portable Robot-Assisted Feeding System
Mar 07, 2024


We demonstrate a robot-assisted feeding system that enables people with mobility impairments to feed themselves. Our system design embodies Safety, Portability, and User Control, with comprehensive full-stack safety checks, the ability to be mounted on and powered by any powered wheelchair, and a custom web-app allowing care-recipients to leverage their own assistive devices for robot control. For bite acquisition, we leverage multi-modal online learning to tractably adapt to unseen food types. For bite transfer, we leverage real-time mouth perception and interaction-aware control. Co-designed with community researchers, our system has been validated through multiple end-user studies.