 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMART: Automatically Scaling Down Language Models with Accuracy Guarantees for Reduced Processing Fees
Mar 11, 2024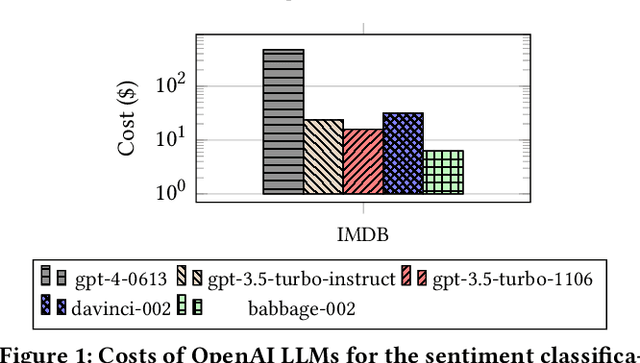


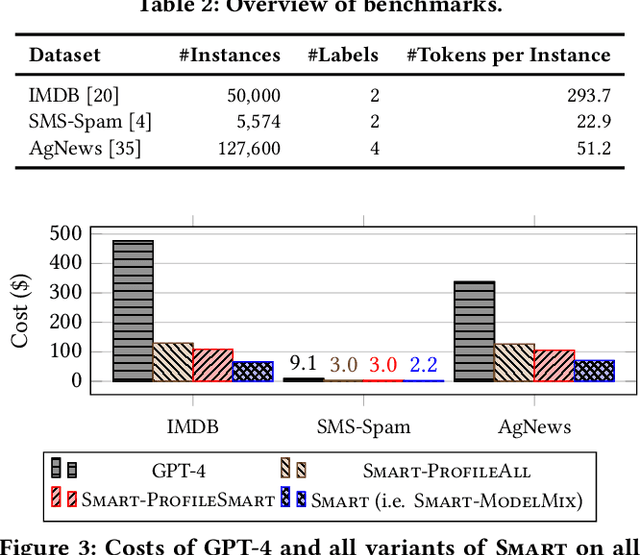
The advancement of Large Language Models (LLMs) has significantly boosted performance in natural language processing (NLP) tasks. However, the deployment of high-performance LLMs incurs substantial costs, primarily due to the increased number of parameters aimed at enhancing model performance. This has made the use of state-of-the-art LLMs more expensive for end-users. AI service providers, such as OpenAI and Anthropic, often offer multiple versions of LLMs with varying prices and performance. However, end-users still face challenges in choosing the appropriate LLM for their tasks that balance result quality with cost. We introduce SMART, Scaling Models Adaptively for Reduced Token Fees, a novel LLM framework designed to minimize the inference costs of NLP tasks while ensuring sufficient result quality. It enables users to specify an accuracy constraint in terms of the equivalence of outputs to those of the most powerful LLM. SMART then generates results that deviate from the outputs of this LLM only with a probability below a user-defined threshold. SMART employs a profiling phase that evaluates the performance of multiple LLMs to identify those that meet the user-defined accuracy level. SMART optimizes the tradeoff between profiling overheads and the anticipated cost savings resulting from profiling. Moreover, our approach significantly reduces inference costs by strategically leveraging a mix of LLMs. Our experiments on three real-world datasets show that, based on OpenAI models, SMART achieves significant cost savings, up to 25.6x in comparison to GPT-4.