 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating the Enterprise with Foundation Models
May 03, 2024



Automating enterprise workflows could unlock $4 trillion/year in productivity gains. Despite being of interest to the data management community for decades, the ultimate vision of end-to-end workflow automation has remained elusive. Current solutions rely on process mining and robotic process automation (RPA), in which a bot is hard-coded to follow a set of predefined rules for completing a workflow. Through case studies of a hospital and large B2B enterprise, we find that the adoption of RPA has been inhibited by high set-up costs (12-18 months), unreliable execution (60% initial accuracy), and burdensome maintenance (requiring multiple FTEs). Multimodal foundation models (FMs) such as GPT-4 offer a promising new approach for end-to-end workflow automation given their generalized reasoning and planning abilities. To study these capabilities we propose ECLAIR, a system to automate enterprise workflows with minimal human supervision. We conduct initial experiments showing that multimodal FMs can address the limitations of traditional RPA with (1) near-human-level understanding of workflows (93% accuracy on a workflow understanding task) and (2) instant set-up with minimal technical barrier (based solely on a natural language description of a workflow, ECLAIR achieves end-to-end completion rates of 40%). We identify human-AI collaboration, validation, and self-improvement as open challenges, and suggest ways they can be solved with data management techniques. Code is available at: https://github.com/HazyResearch/eclair-agents
Laughing Hyena Distillery: Extracting Compact Recurrences From Convolutions
Oct 28, 2023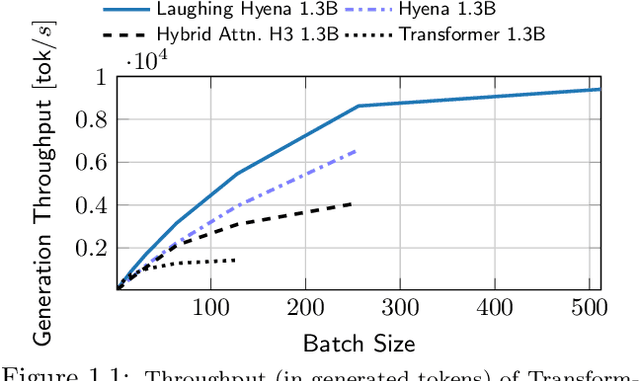
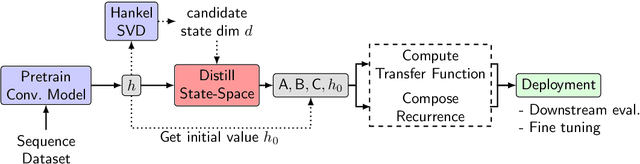
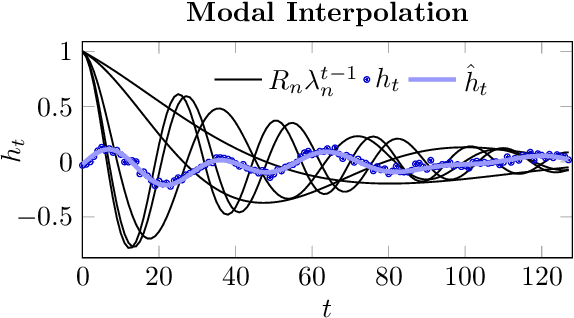
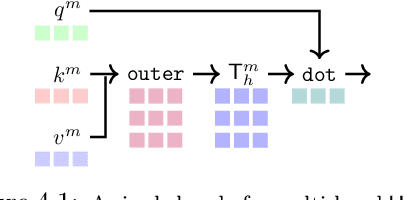
Recent advances in attention-free sequence models rely on convolutions as alternatives to the attention operator at the core of Transformers. In particular, long convolution sequence models have achieved state-of-the-art performance in many domains, but incur a significant cost during auto-regressive inference workloads -- naively requiring a full pass (or caching of activations) over the input sequence for each generated token -- similarly to attention-based models. In this paper, we seek to enable $\mathcal O(1)$ compute and memory cost per token in any pre-trained long convolution architecture to reduce memory footprint and increase throughput during generation. Concretely, our methods consist in extracting low-dimensional linear state-space models from each convolution layer, building upon rational interpolation and model-order reduction techniques. We further introduce architectural improvements to convolution-based layers such as Hyena: by weight-tying the filters across channels into heads, we achieve higher pre-training quality and reduce the number of filters to be distilled. The resulting model achieves 10x higher throughput than Transformers and 1.5x higher than Hyena at 1.3B parameters, without any loss in quality after distillation.