 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMAR: Efficient Hierarchical Masked Auto-Regressive Image Generation
Jun 04, 2025Visual Auto-Regressive modeling (VAR) has shown promise in bridging the speed and quality gap between autoregressive image models and diffusion models. VAR reformulates autoregressive modeling by decomposing an image into successive resolution scales. During inference, an image is generated by predicting all the tokens in the next (higher-resolution) scale, conditioned on all tokens in all previous (lower-resolution) scales. However, this formulation suffers from reduced image quality due to the parallel generation of all tokens in a resolution scale; has sequence lengths scaling superlinearly in image resolution; and requires retraining to change the sampling schedule. We introduce Hierarchical Masked Auto-Regressive modeling (HMAR), a new image generation algorithm that alleviates these issues using next-scale prediction and masked prediction to generate high-quality images with fast sampling. HMAR reformulates next-scale prediction as a Markovian process, wherein the prediction of each resolution scale is conditioned only on tokens in its immediate predecessor instead of the tokens in all predecessor resolutions. When predicting a resolution scale, HMAR uses a controllable multi-step masked generation procedure to generate a subset of the tokens in each step. On ImageNet 256x256 and 512x512 benchmarks, HMAR models match or outperform parameter-matched VAR, diffusion, and autoregressive baselines. We develop efficient IO-aware block-sparse attention kernels that allow HMAR to achieve faster training and inference times over VAR by over 2.5x and 1.75x respectively, as well as over 3x lower inference memory footprint. Finally, HMAR yields additional flexibility over VAR; its sampling schedule can be changed without further training, and it can be applied to image editing tasks in a zero-shot manner.
LowRA: Accurate and Efficient LoRA Fine-Tuning of LLMs under 2 Bits
Feb 12, 2025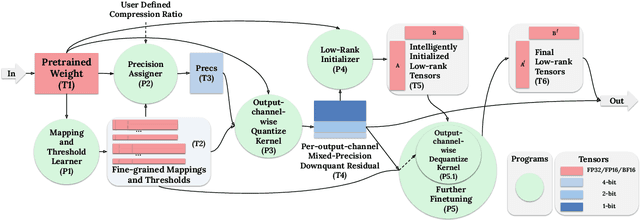

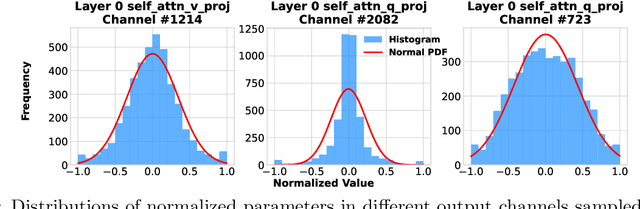
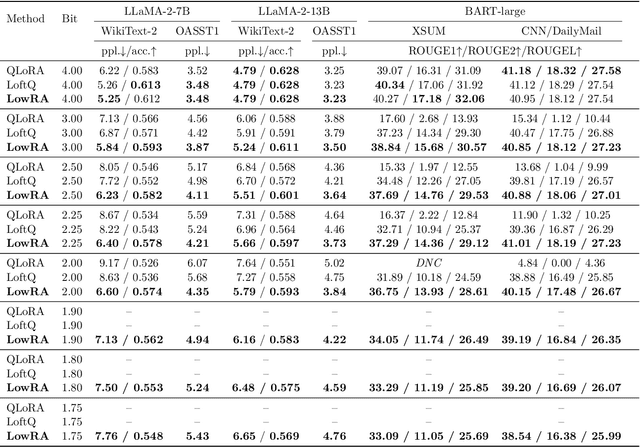
Fine-tuning large language models (LLMs) is increasingly costly as models scale to hundreds of billions of parameters, and even parameter-efficient fine-tuning (PEFT) methods like LoRA remain resource-intensive. We introduce LowRA, the first framework to enable LoRA fine-tuning below 2 bits per parameter with minimal performance loss. LowRA optimizes fine-grained quantization - mapping, threshold selection, and precision assignment - while leveraging efficient CUDA kernels for scalable deployment. Extensive evaluations across 4 LLMs and 4 datasets show that LowRA achieves a superior performance-precision trade-off above 2 bits and remains accurate down to 1.15 bits, reducing memory usage by up to 50%. Our results highlight the potential of ultra-low-bit LoRA fine-tuning for resource-constrained environments.
The Hedgehog & the Porcupine: Expressive Linear Attentions with Softmax Mimicry
Feb 06, 2024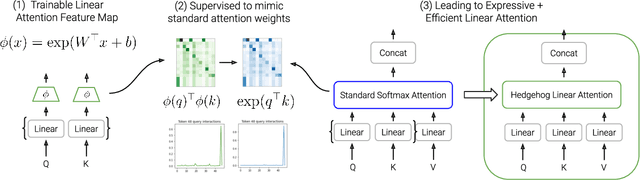

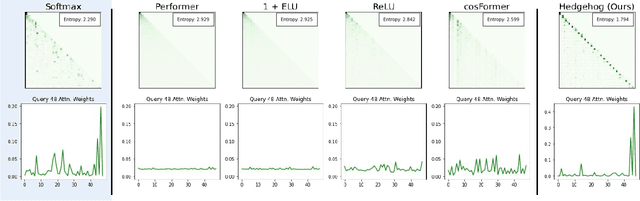
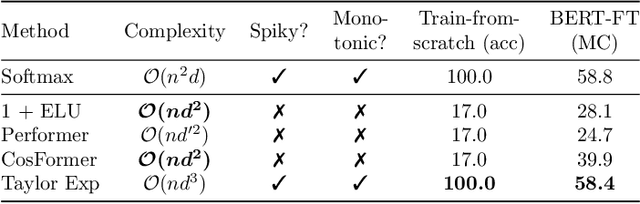
Linear attentions have shown potential for improving Transformer efficiency, reducing attention's quadratic complexity to linear in sequence length. This holds exciting promise for (1) training linear Transformers from scratch, (2) "finetuned-conversion" of task-specific Transformers into linear versions that recover task performance, and (3) "pretrained-conversion" of Transformers such as large language models into linear versions finetunable on downstream tasks. However, linear attentions often underperform standard softmax attention in quality. To close this performance gap, we find prior linear attentions lack key properties of softmax attention tied to good performance: low-entropy (or "spiky") weights and dot-product monotonicity. We further observe surprisingly simple feature maps that retain these properties and match softmax performance, but are inefficient to compute in linear attention. We thus propose Hedgehog, a learnable linear attention that retains the spiky and monotonic properties of softmax attention while maintaining linear complexity. Hedgehog uses simple trainable MLPs to produce attention weights mimicking softmax attention. Experiments show Hedgehog recovers over 99% of standard Transformer quality in train-from-scratch and finetuned-conversion settings, outperforming prior linear attentions up to 6 perplexity points on WikiText-103 with causal GPTs, and up to 8.7 GLUE score points on finetuned bidirectional BERTs. Hedgehog also enables pretrained-conversion. Converting a pretrained GPT-2 into a linear attention variant achieves state-of-the-art 16.7 perplexity on WikiText-103 for 125M subquadratic decoder models. We finally turn a pretrained Llama-2 7B into a viable linear attention Llama. With low-rank adaptation, Hedgehog-Llama2 7B achieves 28.1 higher ROUGE-1 points over the base standard attention model, where prior linear attentions lead to 16.5 point drops.
FlashFFTConv: Efficient Convolutions for Long Sequences with Tensor Cores
Nov 10, 2023



Convolution models with long filters have demonstrated state-of-the-art reasoning abilities in many long-sequence tasks but lag behind the most optimized Transformers in wall-clock time. A major bottleneck is the Fast Fourier Transform (FFT)--which allows long convolutions to run in $O(N logN)$ time in sequence length $N$ but has poor hardware utilization. In this paper, we study how to optimize the FFT convolution. We find two key bottlenecks: the FFT does not effectively use specialized matrix multiply units, and it incurs expensive I/O between layers of the memory hierarchy. In response, we propose FlashFFTConv. FlashFFTConv uses a matrix decomposition that computes the FFT using matrix multiply units and enables kernel fusion for long sequences, reducing I/O. We also present two sparse convolution algorithms--1) partial convolutions and 2) frequency-sparse convolutions--which can be implemented simply by skipping blocks in the matrix decomposition, enabling further opportunities for memory and compute savings. FlashFFTConv speeds up exact FFT convolutions by up to 7.93$\times$ over PyTorch and achieves up to 4.4$\times$ speedup end-to-end. Given the same compute budget, FlashFFTConv allows Hyena-GPT-s to achieve 2.3 points better perplexity on the PILE and M2-BERT-base to achieve 3.3 points higher GLUE score--matching models with twice the parameter count. FlashFFTConv also achieves 96.1% accuracy on Path-512, a high-resolution vision task where no model had previously achieved better than 50%. Furthermore, partial convolutions enable longer-sequence models--yielding the first DNA model that can process the longest human genes (2.3M base pairs)--and frequency-sparse convolutions speed up pretrained models while maintaining or improving model quality.
Laughing Hyena Distillery: Extracting Compact Recurrences From Convolutions
Oct 28, 2023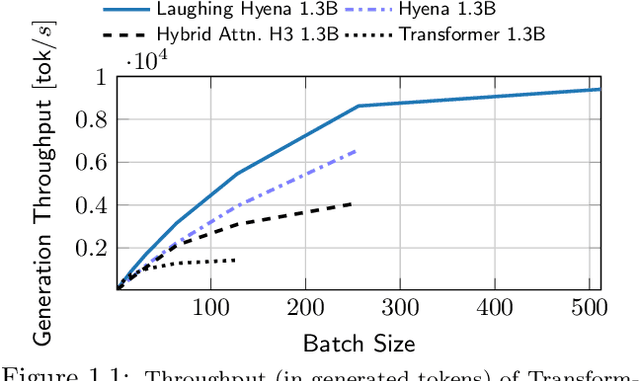
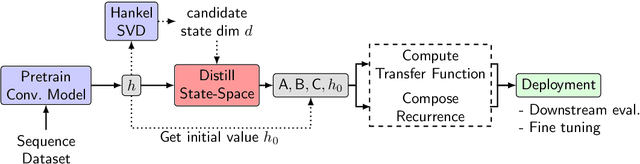
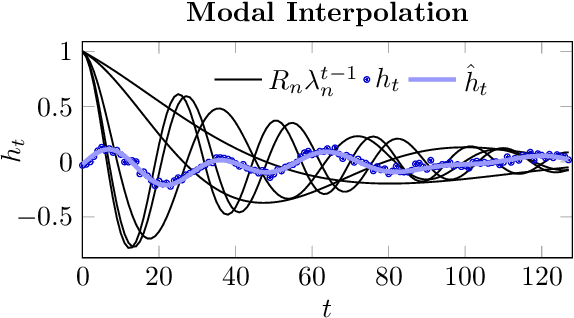
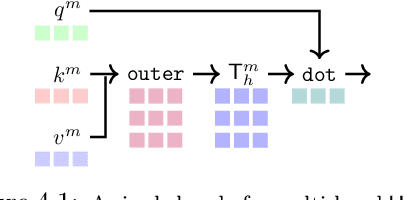
Recent advances in attention-free sequence models rely on convolutions as alternatives to the attention operator at the core of Transformers. In particular, long convolution sequence models have achieved state-of-the-art performance in many domains, but incur a significant cost during auto-regressive inference workloads -- naively requiring a full pass (or caching of activations) over the input sequence for each generated token -- similarly to attention-based models. In this paper, we seek to enable $\mathcal O(1)$ compute and memory cost per token in any pre-trained long convolution architecture to reduce memory footprint and increase throughput during generation. Concretely, our methods consist in extracting low-dimensional linear state-space models from each convolution layer, building upon rational interpolation and model-order reduction techniques. We further introduce architectural improvements to convolution-based layers such as Hyena: by weight-tying the filters across channels into heads, we achieve higher pre-training quality and reduce the number of filters to be distilled. The resulting model achieves 10x higher throughput than Transformers and 1.5x higher than Hyena at 1.3B parameters, without any loss in quality after distillation.