 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI For Global Climate Cooperation 2023 Competition Proceedings
Jul 10, 2023The international community must collaborate to mitigate climate change and sustain economic growth. However, collaboration is hard to achieve, partly because no global authority can ensure compliance with international climate agreements. Combining AI with climate-economic simulations offers a promising solution to design international frameworks, including negotiation protocols and climate agreements, that promote and incentivize collaboration. In addition, these frameworks should also have policy goals fulfillment, and sustained commitment, taking into account climate-economic dynamics and strategic behaviors. These challenges require an interdisciplinary approach across machine learning, economics, climate science, law, policy, ethics, and other fields. Towards this objective, we organized AI for Global Climate Cooperation, a Mila competition in which teams submitted proposals and analyses of international frameworks, based on (modifications of) RICE-N, an AI-driven integrated assessment model (IAM). In particular, RICE-N supports modeling regional decision-making using AI agents. Furthermore, the IAM then models the climate-economic impact of those decisions into the future. Whereas the first track focused only on performance metrics, the proposals submitted to the second track were evaluated both quantitatively and qualitatively. The quantitative evaluation focused on a combination of (i) the degree of mitigation of global temperature rise and (ii) the increase in economic productivity. On the other hand, an interdisciplinary panel of human experts in law, policy, sociology, economics and environmental science, evaluated the solutions qualitatively. In particular, the panel considered the effectiveness, simplicity, feasibility, ethics, and notions of climate justice of the protocols. In the third track, the participants were asked to critique and improve RICE-N.
MERMAIDE: Learning to Align Learners using Model-Based Meta-Learning
Apr 10, 2023



We study how a principal can efficiently and effectively intervene on the rewards of a previously unseen learning agent in order to induce desirable outcomes. This is relevant to many real-world settings like auctions or taxation, where the principal may not know the learning behavior nor the rewards of real people. Moreover, the principal should be few-shot adaptable and minimize the number of interventions, because interventions are often costly. We introduce MERMAIDE, a model-based meta-learning framework to train a principal that can quickly adapt to out-of-distribution agents with different learning strategies and reward functions. We validate this approach step-by-step. First, in a Stackelberg setting with a best-response agent, we show that meta-learning enables quick convergence to the theoretically known Stackelberg equilibrium at test time, although noisy observations severely increase the sample complexity. We then show that our model-based meta-learning approach is cost-effective in intervening on bandit agents with unseen explore-exploit strategies. Finally, we outperform baselines that use either meta-learning or agent behavior modeling, in both $0$-shot and $K=1$-shot settings with partial agent information.
Interactive Learning with Pricing for Optimal and Stable Allocations in Markets
Dec 13, 2022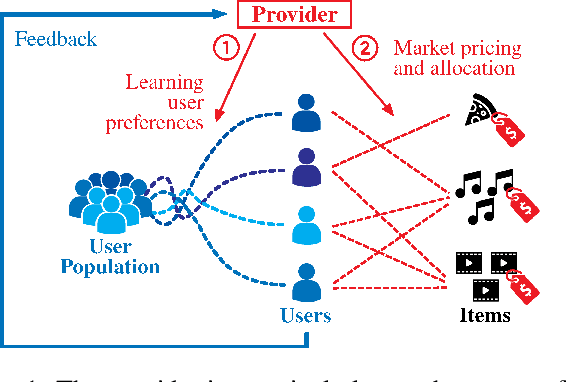
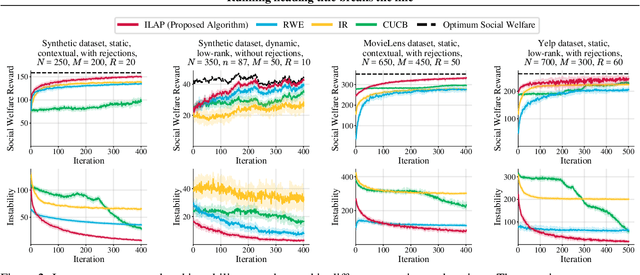
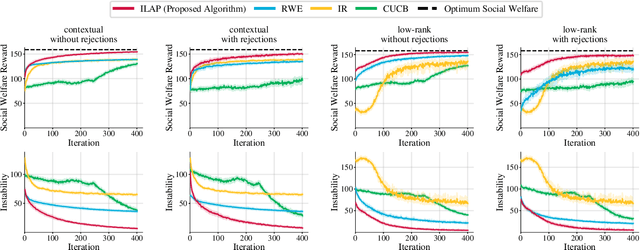
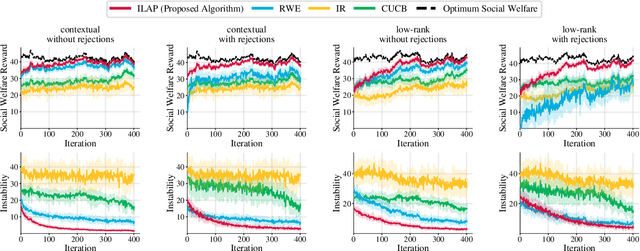
Large-scale online recommendation systems must facilitate the allocation of a limited number of items among competing users while learning their preferences from user feedback. As a principled way of incorporating market constraints and user incentives in the design, we consider our objectives to be two-fold: maximal social welfare with minimal instability. To maximize social welfare, our proposed framework enhances the quality of recommendations by exploring allocations that optimistically maximize the rewards. To minimize instability, a measure of users' incentives to deviate from recommended allocations, the algorithm prices the items based on a scheme derived from the Walrasian equilibria. Though it is known that these equilibria yield stable prices for markets with known user preferences, our approach accounts for the inherent uncertainty in the preferences and further ensures that the users accept their recommendations under offered prices. To the best of our knowledge, our approach is the first to integrate techniques from combinatorial bandits, optimal resource allocation, and collaborative filtering to obtain an algorithm that achieves sub-linear social welfare regret as well as sub-linear instability. Empirical studies on synthetic and real-world data also demonstrate the efficacy of our strategy compared to approaches that do not fully incorporate all these aspects.
AI for Global Climate Cooperation: Modeling Global Climate Negotiations, Agreements, and Long-Term Cooperation in RICE-N
Aug 15, 2022
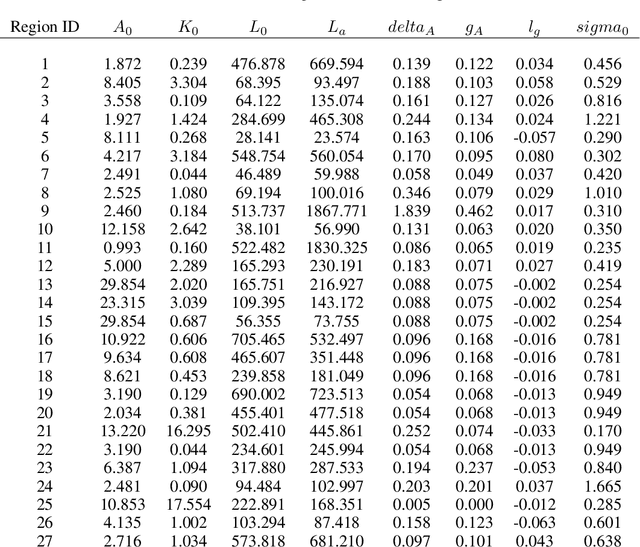
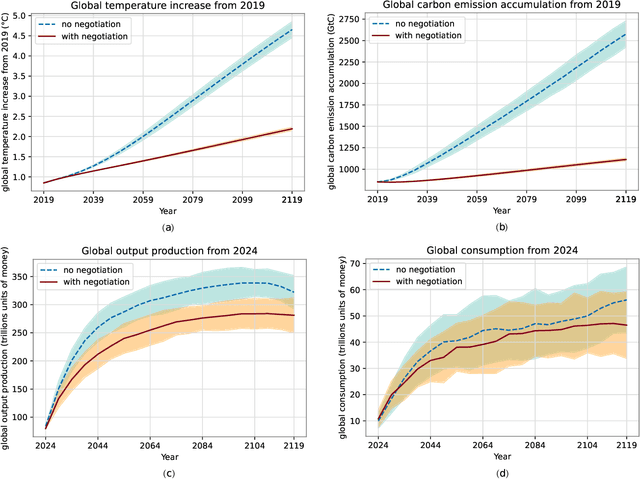

Comprehensive global cooperation is essential to limit global temperature increases while continuing economic development, e.g., reducing severe inequality or achieving long-term economic growth. Achieving long-term cooperation on climate change mitigation with n strategic agents poses a complex game-theoretic problem. For example, agents may negotiate and reach climate agreements, but there is no central authority to enforce adherence to those agreements. Hence, it is critical to design negotiation and agreement frameworks that foster cooperation, allow all agents to meet their individual policy objectives, and incentivize long-term adherence. This is an interdisciplinary challenge that calls for collaboration between researchers in machine learning, economics, climate science, law, policy, ethics, and other fields. In particular, we argue that machine learning is a critical tool to address the complexity of this domain. To facilitate this research, here we introduce RICE-N, a multi-region integrated assessment model that simulates the global climate and economy, and which can be used to design and evaluate the strategic outcomes for different negotiation and agreement frameworks. We also describe how to use multi-agent reinforcement learning to train rational agents using RICE-N. This framework underpinsAI for Global Climate Cooperation, a working group collaboration and competition on climate negotiation and agreement design. Here, we invite the scientific community to design and evaluate their solutions using RICE-N, machine learning, economic intuition, and other domain knowledge. More information can be found on www.ai4climatecoop.org.
Interactive Recommendations for Optimal Allocations in Markets with Constraints
Jul 08, 2022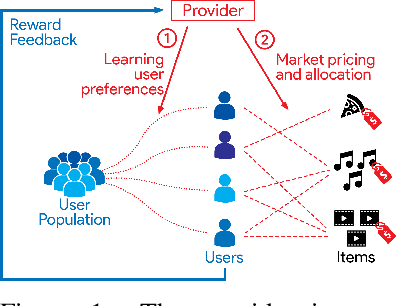
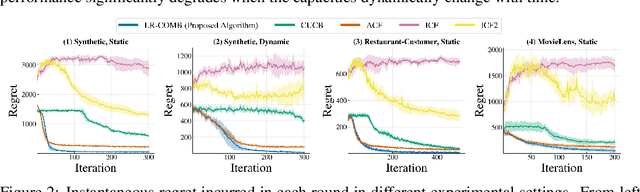
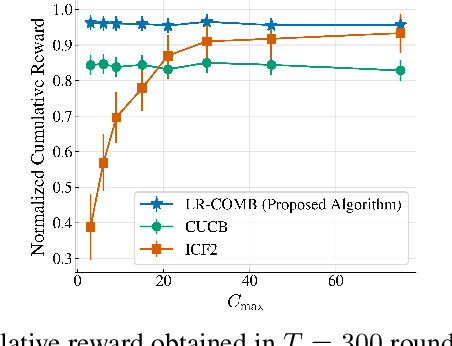
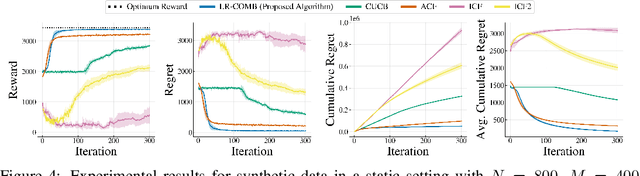
Recommendation systems when employed in markets play a dual role: they assist users in selecting their most desired items from a large pool and they help in allocating a limited number of items to the users who desire them the most. Despite the prevalence of capacity constraints on allocations in many real-world recommendation settings, a principled way of incorporating them in the design of these systems has been lacking. Motivated by this, we propose an interactive framework where the system provider can enhance the quality of recommendations to the users by opportunistically exploring allocations that maximize user rewards and respect the capacity constraints using appropriate pricing mechanisms. We model the problem as an instance of a low-rank combinatorial multi-armed bandit problem with selection constraints on the arms. We employ an integrated approach using techniques from collaborative filtering, combinatorial bandits, and optimal resource allocation to provide an algorithm that provably achieves sub-linear regret, namely $\tilde{\mathcal{O}} ( \sqrt{N M (N+M) RT} )$ in $T$ rounds for a problem with $N$ users, $M$ items and rank $R$ mean reward matrix. Empirical studies on synthetic and real-world data also demonstrate the effectiveness and performance of our approach.
Finding General Equilibria in Many-Agent Economic Simulations Using Deep Reinforcement Learning
Jan 03, 2022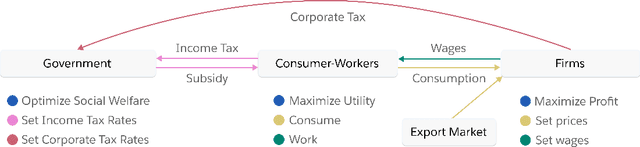

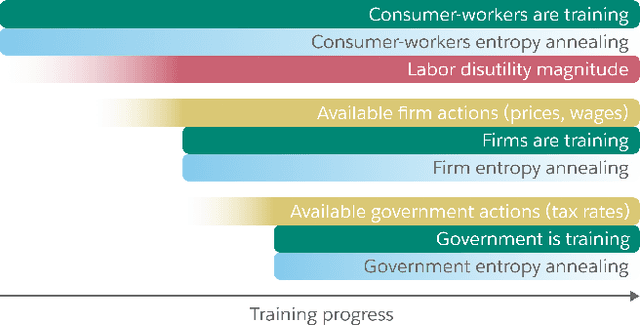
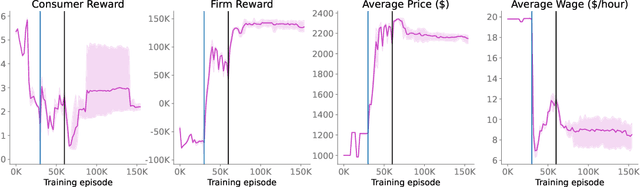
Real economies can be seen as a sequential imperfect-information game with many heterogeneous, interacting strategic agents of various agent types, such as consumers, firms, and governments. Dynamic general equilibrium models are common economic tools to model the economic activity, interactions, and outcomes in such systems. However, existing analytical and computational methods struggle to find explicit equilibria when all agents are strategic and interact, while joint learning is unstable and challenging. Amongst others, a key reason is that the actions of one economic agent may change the reward function of another agent, e.g., a consumer's expendable income changes when firms change prices or governments change taxes. We show that multi-agent deep reinforcement learning (RL) can discover stable solutions that are epsilon-Nash equilibria for a meta-game over agent types, in economic simulations with many agents, through the use of structured learning curricula and efficient GPU-only simulation and training. Conceptually, our approach is more flexible and does not need unrealistic assumptions, e.g., market clearing, that are commonly used for analytical tractability. Our GPU implementation enables training and analyzing economies with a large number of agents within reasonable time frames, e.g., training completes within a day. We demonstrate our approach in real-business-cycle models, a representative family of DGE models, with 100 worker-consumers, 10 firms, and a government who taxes and redistributes. We validate the learned meta-game epsilon-Nash equilibria through approximate best-response analyses, show that RL policies align with economic intuitions, and that our approach is constructive, e.g., by explicitly learning a spectrum of meta-game epsilon-Nash equilibria in open RBC models.
On the Impossibility of Convergence of Mixed Strategies with No Regret Learning
Dec 03, 2020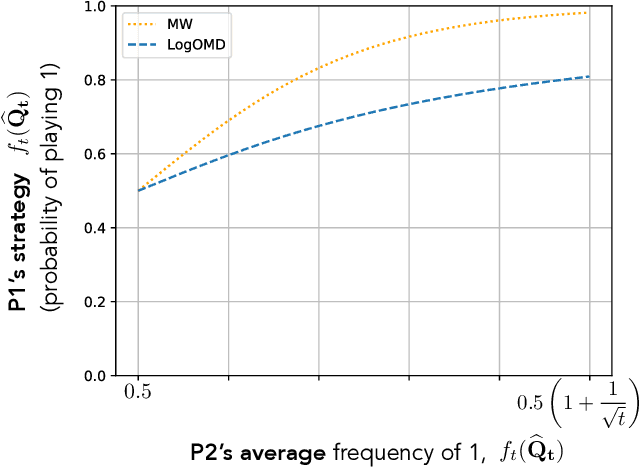
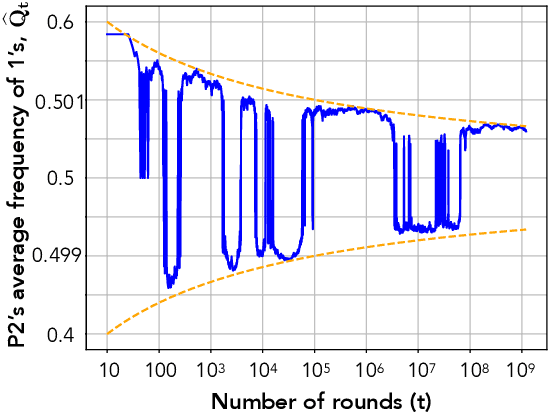
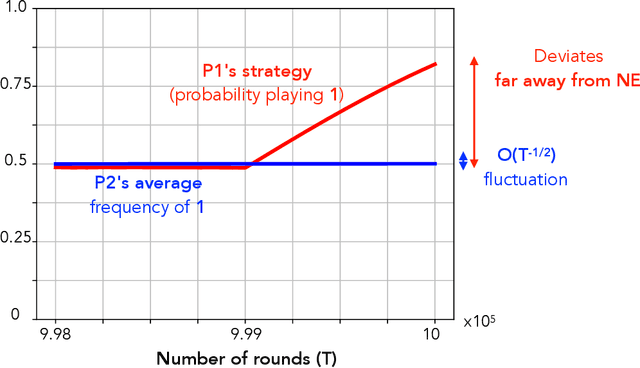
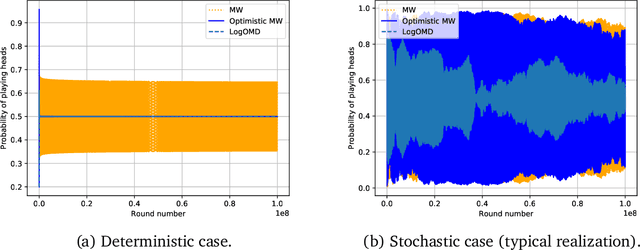
We study convergence properties of the mixed strategies that result from a general class of optimal no regret learning strategies in a repeated game setting where the stage game is any 2 by 2 competitive game (i.e. game for which all the Nash equilibria (NE) of the game are completely mixed). We consider the class of strategies whose information set at each step is the empirical average of the opponent's realized play (and the step number), that we call mean based strategies. We first show that there does not exist any optimal no regret, mean based strategy for player 1 that would result in the convergence of her mixed strategies (in probability) against an opponent that plays his Nash equilibrium mixed strategy at each step. Next, we show that this last iterate divergence necessarily occurs if player 2 uses any adaptive strategy with a minimal randomness property. This property is satisfied, for example, by any fixed sequence of mixed strategies for player 2 that converges to NE. We conjecture that this property holds when both players use optimal no regret learning strategies against each other, leading to the divergence of the mixed strategies with a positive probability. Finally, we show that variants of mean based strategies using recency bias, which have yielded last iterate convergence in deterministic min max optimization, continue to lead to this last iterate divergence. This demonstrates a crucial difference in outcomes between using the opponent's mixtures and realizations to make strategy updates.