 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Prediction Length for Time Series with Sequence to Sequence Networks
Jul 02, 2018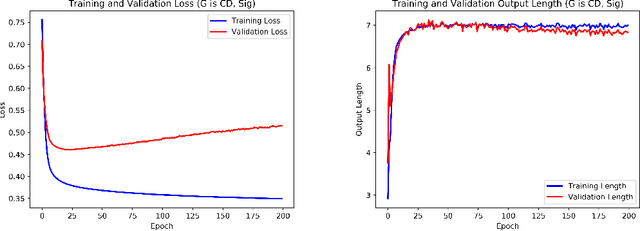
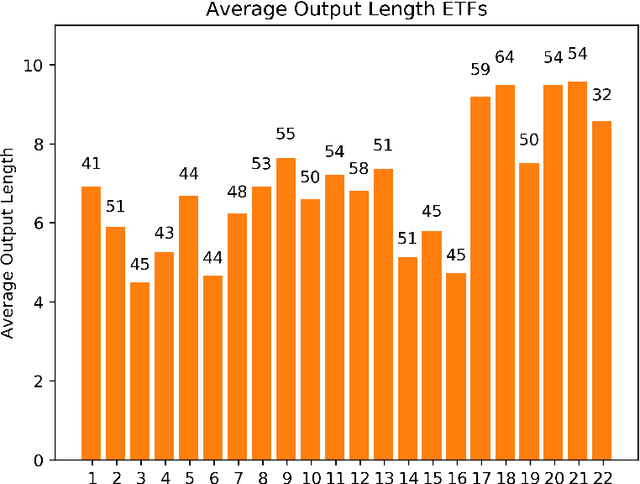
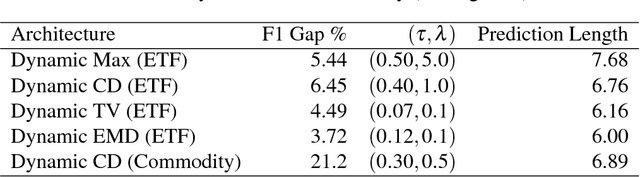
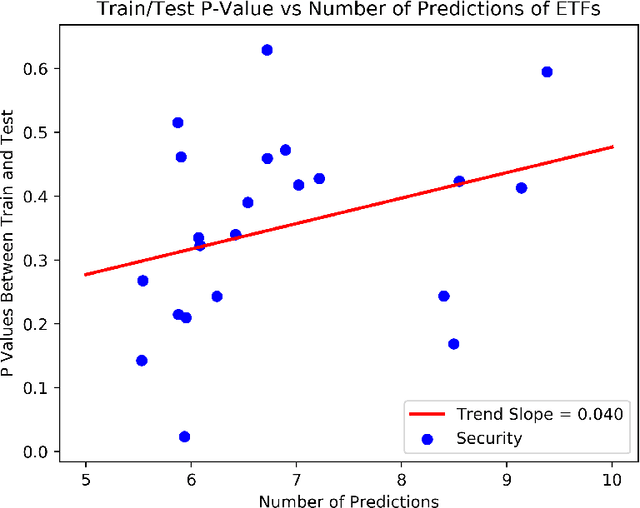
Recurrent neural networks and sequence to sequence models require a predetermined length for prediction output length. Our model addresses this by allowing the network to predict a variable length output in inference. A new loss function with a tailored gradient computation is developed that trades off prediction accuracy and output length. The model utilizes a function to determine whether a particular output at a time should be evaluated or not given a predetermined threshold. We evaluate the model on the problem of predicting the prices of securities. We find that the model makes longer predictions for more stable securities and it naturally balances prediction accuracy and length.
Predicting Shot Making in Basketball Learnt from Adversarial Multiagent Trajectories
Dec 28, 2017

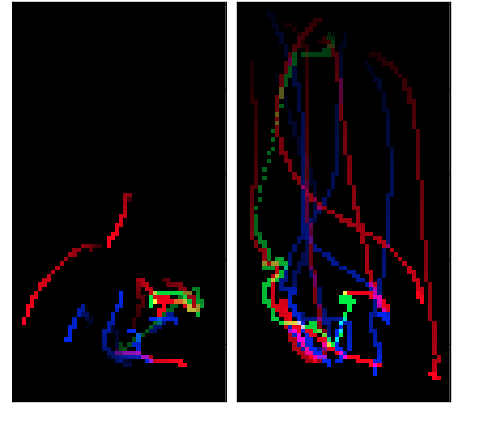
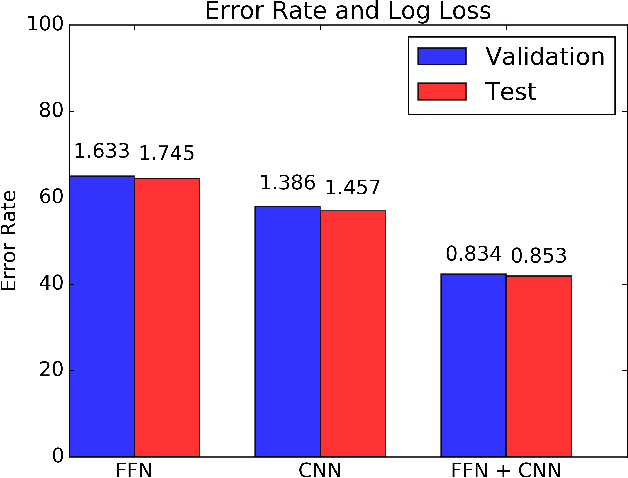
In this paper, we predict the likelihood of a player making a shot in basketball from multiagent trajectories. Previous approaches to similar problems center on hand-crafting features to capture domain specific knowledge. Although intuitive, recent work in deep learning has shown this approach is prone to missing important predictive features. To circumvent this issue, we present a convolutional neural network (CNN) approach where we initially represent the multiagent behavior as an image. To encode the adversarial nature of basketball, we use a multi-channel image which we then feed into a CNN. Additionally, to capture the temporal aspect of the trajectories we "fade" the player trajectories. We find that this approach is superior to a traditional FFN model. By using gradient ascent to create images using an already trained CNN, we discover what features the CNN filters learn. Last, we find that a combined CNN+FFN is the best performing network with an error rate of 39%.
Activation Ensembles for Deep Neural Networks
Feb 24, 2017
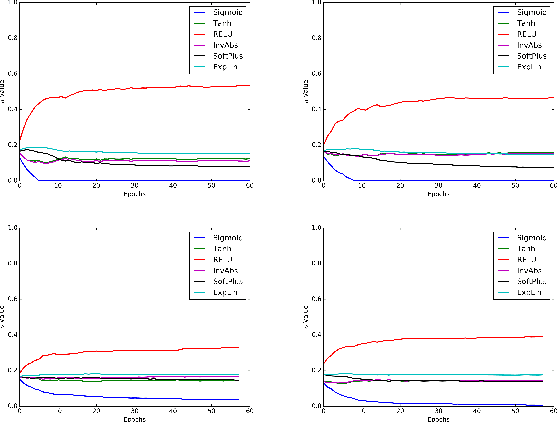

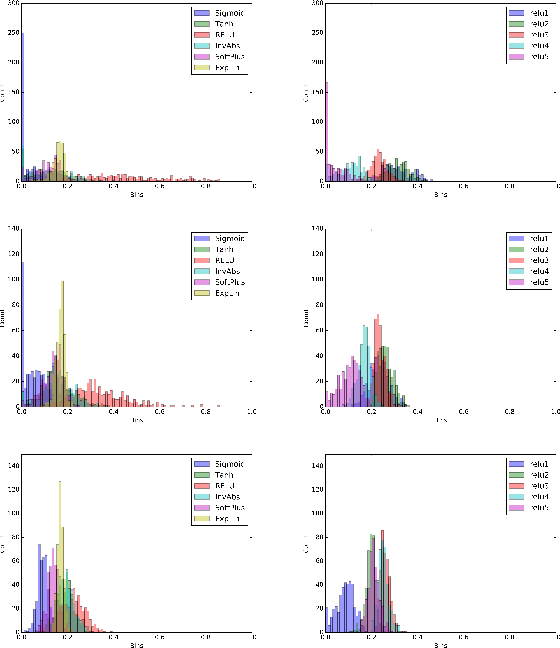
Many activation functions have been proposed in the past, but selecting an adequate one requires trial and error. We propose a new methodology of designing activation functions within a neural network at each layer. We call this technique an "activation ensemble" because it allows the use of multiple activation functions at each layer. This is done by introducing additional variables, $\alpha$, at each activation layer of a network to allow for multiple activation functions to be active at each neuron. By design, activations with larger $\alpha$ values at a neuron is equivalent to having the largest magnitude. Hence, those higher magnitude activations are "chosen" by the network. We implement the activation ensembles on a variety of datasets using an array of Feed Forward and Convolutional Neural Networks. By using the activation ensemble, we achieve superior results compared to traditional techniques. In addition, because of the flexibility of this methodology, we more deeply explore activation functions and the features that they capture.