 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance Regularization for Accelerating Stochastic Optimization
Paper and Code
Aug 13, 2020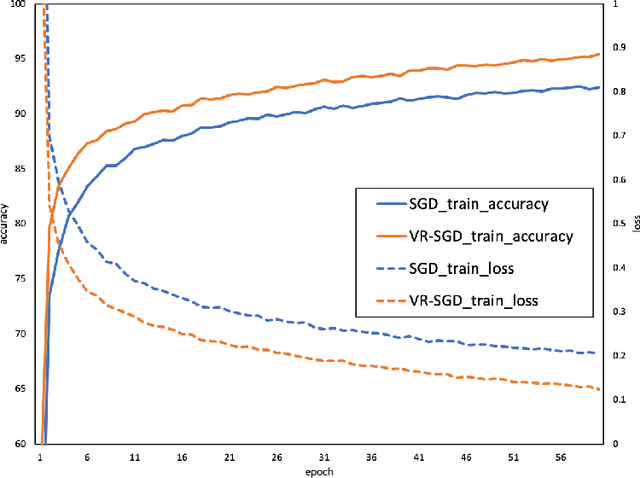

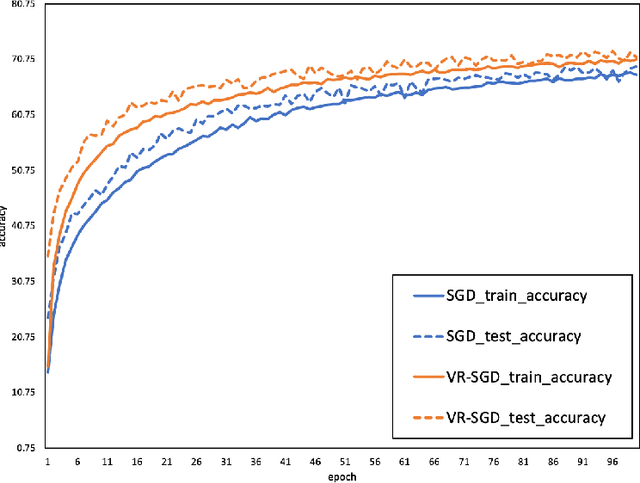
While nowadays most gradient-based optimization methods focus on exploring the high-dimensional geometric features, the random error accumulated in a stochastic version of any algorithm implementation has not been stressed yet. In this work, we propose a universal principle which reduces the random error accumulation by exploiting statistic information hidden in mini-batch gradients. This is achieved by regularizing the learning-rate according to mini-batch variances. Due to the complementarity of our perspective, this regularization could provide a further improvement for stochastic implementation of generic 1st order approaches. With empirical results, we demonstrated the variance regularization could speed up the convergence as well as stabilize the stochastic optimization.