 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysInOne: Visual Physics Learning and Reasoning in One Suite
Apr 10, 2026We present PhysInOne, a large-scale synthetic dataset addressing the critical scarcity of physically-grounded training data for AI systems. Unlike existing datasets limited to merely hundreds or thousands of examples, PhysInOne provides 2 million videos across 153,810 dynamic 3D scenes, covering 71 basic physical phenomena in mechanics, optics, fluid dynamics, and magnetism. Distinct from previous works, our scenes feature multiobject interactions against complex backgrounds, with comprehensive ground-truth annotations including 3D geometry, semantics, dynamic motion, physical properties, and text descriptions. We demonstrate PhysInOne's efficacy across four emerging applications: physics-aware video generation, long-/short-term future frame prediction, physical property estimation, and motion transfer. Experiments show that fine-tuning foundation models on PhysInOne significantly enhances physical plausibility, while also exposing critical gaps in modeling complex physical dynamics and estimating intrinsic properties. As the largest dataset of its kind, orders of magnitude beyond prior works, PhysInOne establishes a new benchmark for advancing physics-grounded world models in generation, simulation, and embodied AI.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
VL-SAT: Visual-Linguistic Semantics Assisted Training for 3D Semantic Scene Graph Prediction in Point Cloud
Mar 25, 2023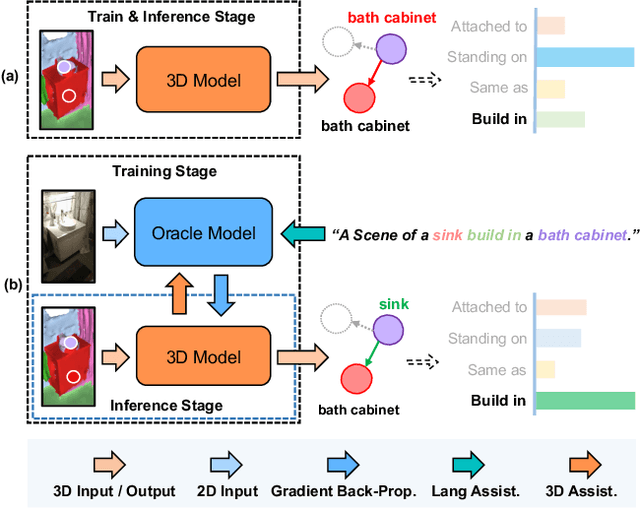

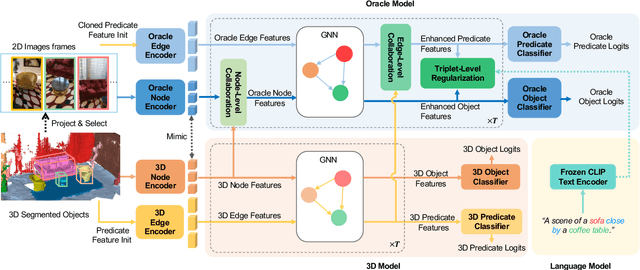
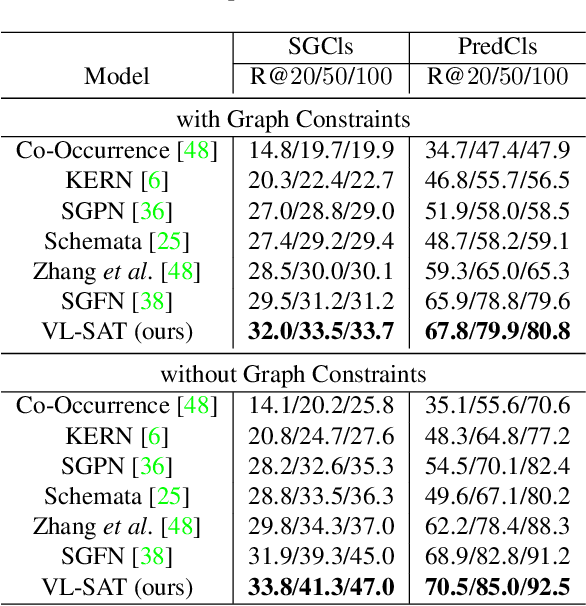
The task of 3D semantic scene graph (3DSSG) prediction in the point cloud is challenging since (1) the 3D point cloud only captures geometric structures with limited semantics compared to 2D images, and (2) long-tailed relation distribution inherently hinders the learning of unbiased prediction. Since 2D images provide rich semantics and scene graphs are in nature coped with languages, in this study, we propose Visual-Linguistic Semantics Assisted Training (VL-SAT) scheme that can significantly empower 3DSSG prediction models with discrimination about long-tailed and ambiguous semantic relations. The key idea is to train a powerful multi-modal oracle model to assist the 3D model. This oracle learns reliable structural representations based on semantics from vision, language, and 3D geometry, and its benefits can be heterogeneously passed to the 3D model during the training stage. By effectively utilizing visual-linguistic semantics in training, our VL-SAT can significantly boost common 3DSSG prediction models, such as SGFN and SGGpoint, only with 3D inputs in the inference stage, especially when dealing with tail relation triplets. Comprehensive evaluations and ablation studies on the 3DSSG dataset have validated the effectiveness of the proposed scheme. Code is available at https://github.com/wz7in/CVPR2023-VLSAT.
Mask2Former for Video Instance Segmentation
Dec 20, 2021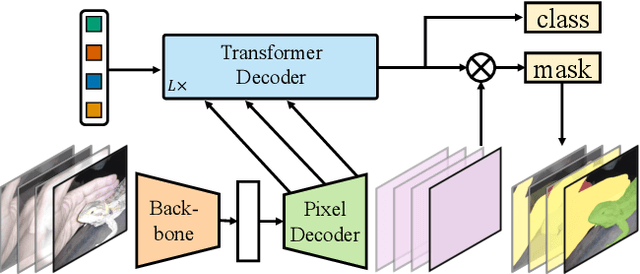
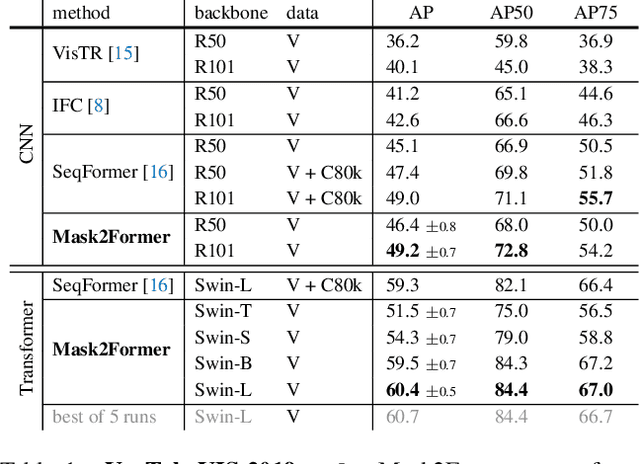
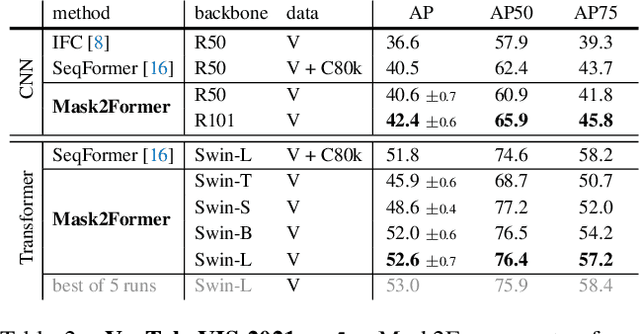
We find Mask2Former also achieves state-of-the-art performance on video instance segmentation without modifying the architecture, the loss or even the training pipeline. In this report, we show universal image segmentation architectures trivially generalize to video segmentation by directly predicting 3D segmentation volumes. Specifically, Mask2Former sets a new state-of-the-art of 60.4 AP on YouTubeVIS-2019 and 52.6 AP on YouTubeVIS-2021. We believe Mask2Former is also capable of handling video semantic and panoptic segmentation, given its versatility in image segmentation. We hope this will make state-of-the-art video segmentation research more accessible and bring more attention to designing universal image and video segmentation architectures.
Masked-attention Mask Transformer for Universal Image Segmentation
Dec 10, 2021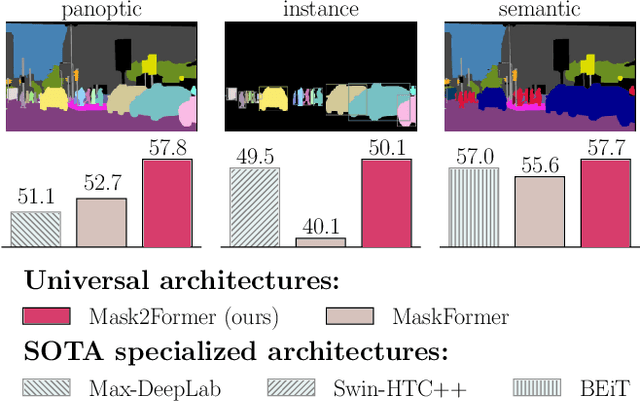
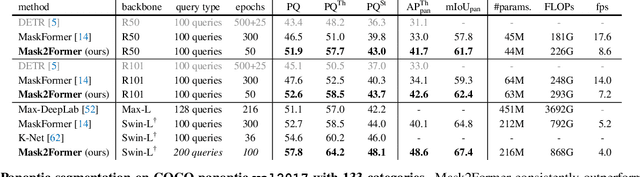
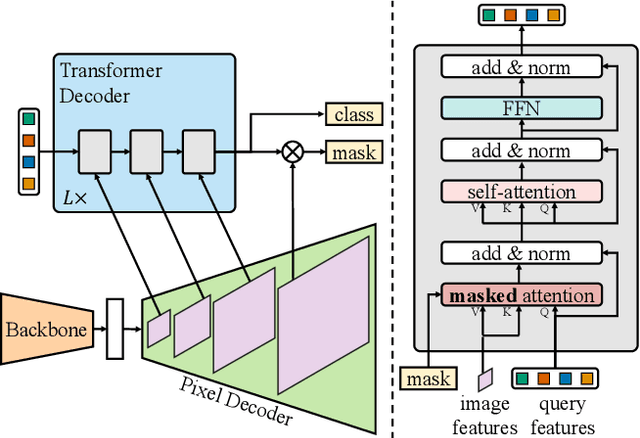
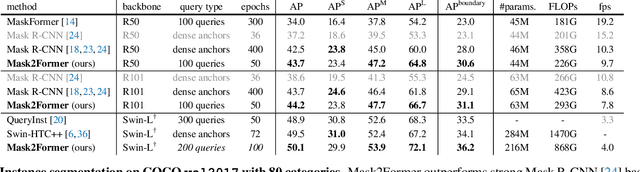
Image segmentation is about grouping pixels with different semantics, e.g., category or instance membership, where each choice of semantics defines a task. While only the semantics of each task differ, current research focuses on designing specialized architectures for each task. We present Masked-attention Mask Transformer (Mask2Former), a new architecture capable of addressing any image segmentation task (panoptic, instance or semantic). Its key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. In addition to reducing the research effort by at least three times, it outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).
Per-Pixel Classification is Not All You Need for Semantic Segmentation
Jul 13, 2021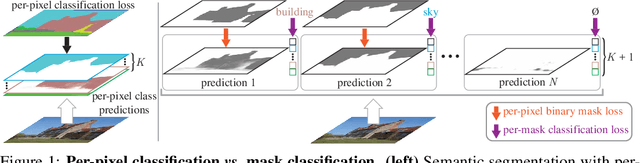
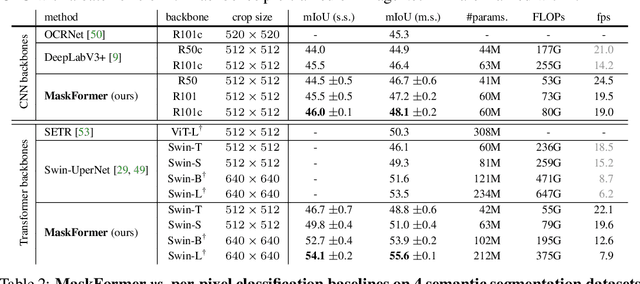
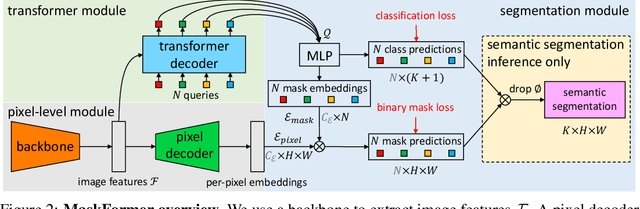

Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.
Pseudo-IoU: Improving Label Assignment in Anchor-Free Object Detection
Apr 29, 2021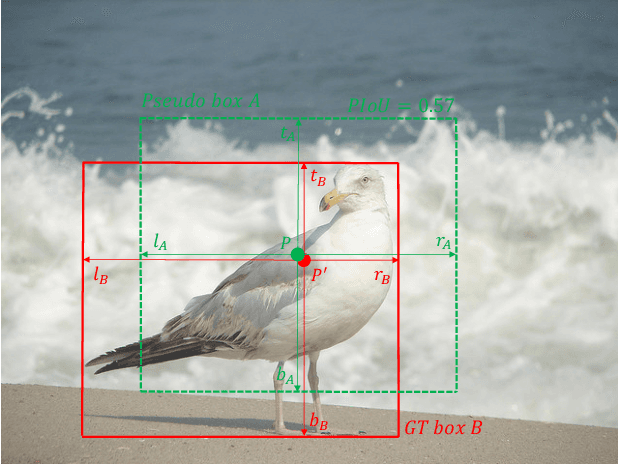
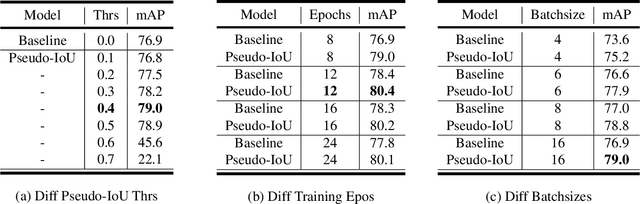
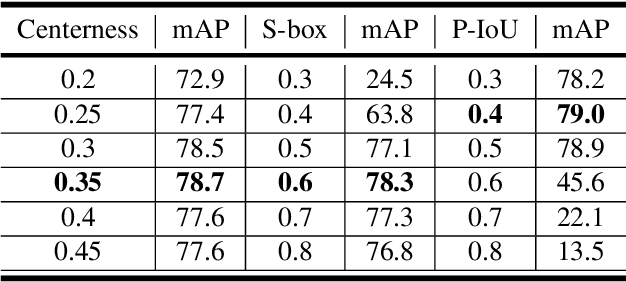
Current anchor-free object detectors are quite simple and effective yet lack accurate label assignment methods, which limits their potential in competing with classic anchor-based models that are supported by well-designed assignment methods based on the Intersection-over-Union~(IoU) metric. In this paper, we present \textbf{Pseudo-Intersection-over-Union~(Pseudo-IoU)}: a simple metric that brings more standardized and accurate assignment rule into anchor-free object detection frameworks without any additional computational cost or extra parameters for training and testing, making it possible to further improve anchor-free object detection by utilizing training samples of good quality under effective assignment rules that have been previously applied in anchor-based methods. By incorporating Pseudo-IoU metric into an end-to-end single-stage anchor-free object detection framework, we observe consistent improvements in their performance on general object detection benchmarks such as PASCAL VOC and MSCOCO. Our method (single-model and single-scale) also achieves comparable performance to other recent state-of-the-art anchor-free methods without bells and whistles. Our code is based on mmdetection toolbox and will be made publicly available at https://github.com/SHI-Labs/Pseudo-IoU-for-Anchor-Free-Object-Detection.
Back-tracing Representative Points for Voting-based 3D Object Detection in Point Clouds
Apr 14, 2021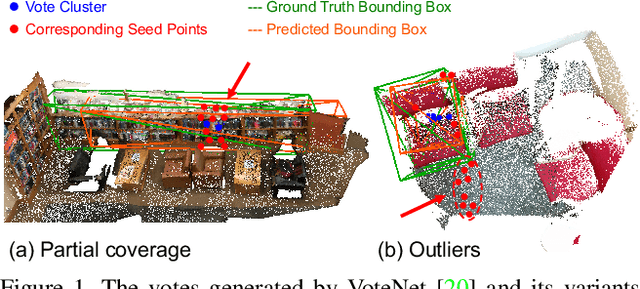
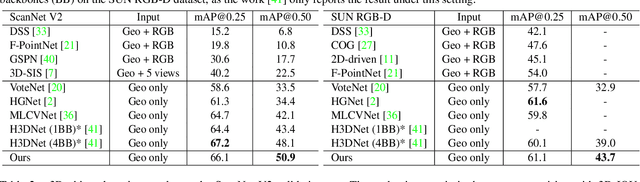
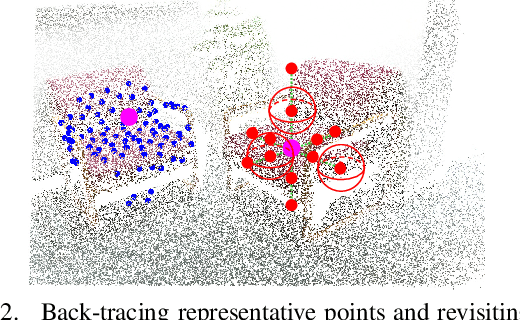

3D object detection in point clouds is a challenging vision task that benefits various applications for understanding the 3D visual world. Lots of recent research focuses on how to exploit end-to-end trainable Hough voting for generating object proposals. However, the current voting strategy can only receive partial votes from the surfaces of potential objects together with severe outlier votes from the cluttered backgrounds, which hampers full utilization of the information from the input point clouds. Inspired by the back-tracing strategy in the conventional Hough voting methods, in this work, we introduce a new 3D object detection method, named as Back-tracing Representative Points Network (BRNet), which generatively back-traces the representative points from the vote centers and also revisits complementary seed points around these generated points, so as to better capture the fine local structural features surrounding the potential objects from the raw point clouds. Therefore, this bottom-up and then top-down strategy in our BRNet enforces mutual consistency between the predicted vote centers and the raw surface points and thus achieves more reliable and flexible object localization and class prediction results. Our BRNet is simple but effective, which significantly outperforms the state-of-the-art methods on two large-scale point cloud datasets, ScanNet V2 (+7.5% in terms of mAP@0.50) and SUN RGB-D (+4.7% in terms of mAP@0.50), while it is still lightweight and efficient. Code will be available at https://github.com/cheng052/BRNet.
Pointly-Supervised Instance Segmentation
Apr 13, 2021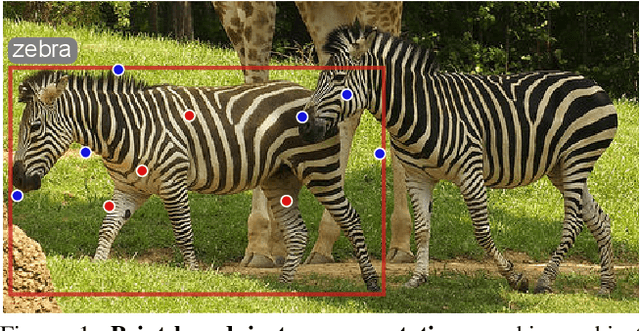

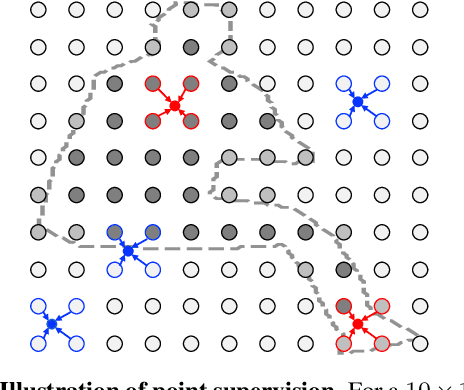

We propose point-based instance-level annotation, a new form of weak supervision for instance segmentation. It combines the standard bounding box annotation with labeled points that are uniformly sampled inside each bounding box. We show that the existing instance segmentation models developed for full mask supervision, like Mask R-CNN, can be seamlessly trained with the point-based annotation without any major modifications. In our experiments, Mask R-CNN models trained on COCO, PASCAL VOC, Cityscapes, and LVIS with only 10 annotated points per object achieve 94%--98% of their fully-supervised performance. The new point-based annotation is approximately 5 times faster to collect than object masks, making high-quality instance segmentation more accessible for new data. Inspired by the new annotation form, we propose a modification to PointRend instance segmentation module. For each object, the new architecture, called Implicit PointRend, generates parameters for a function that makes the final point-level mask prediction. Implicit PointRend is more straightforward and uses a single point-level mask loss. Our experiments show that the new module is more suitable for the proposed point-based supervision.
Boundary IoU: Improving Object-Centric Image Segmentation Evaluation
Mar 30, 2021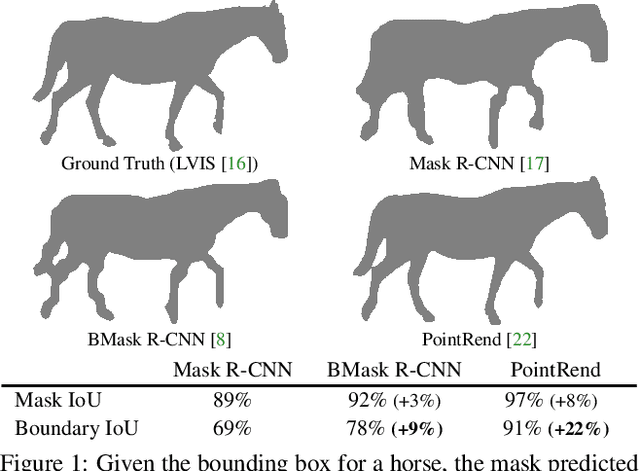
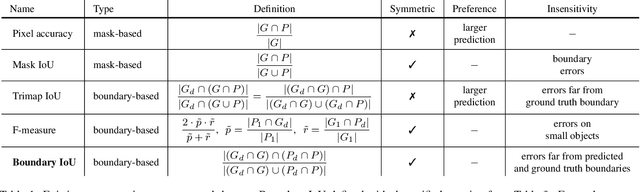

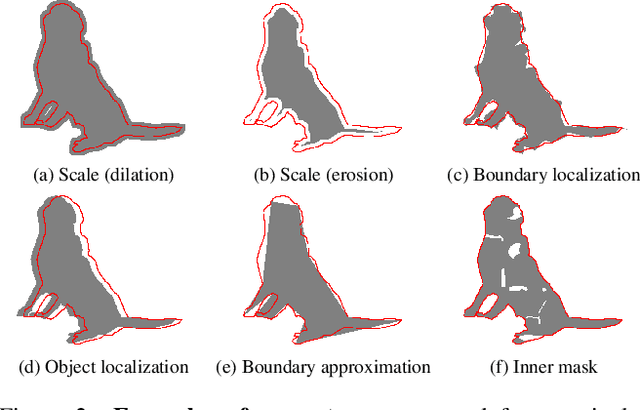
We present Boundary IoU (Intersection-over-Union), a new segmentation evaluation measure focused on boundary quality. We perform an extensive analysis across different error types and object sizes and show that Boundary IoU is significantly more sensitive than the standard Mask IoU measure to boundary errors for large objects and does not over-penalize errors on smaller objects. The new quality measure displays several desirable characteristics like symmetry w.r.t. prediction/ground truth pairs and balanced responsiveness across scales, which makes it more suitable for segmentation evaluation than other boundary-focused measures like Trimap IoU and F-measure. Based on Boundary IoU, we update the standard evaluation protocols for instance and panoptic segmentation tasks by proposing the Boundary AP (Average Precision) and Boundary PQ (Panoptic Quality) metrics, respectively. Our experiments show that the new evaluation metrics track boundary quality improvements that are generally overlooked by current Mask IoU-based evaluation metrics. We hope that the adoption of the new boundary-sensitive evaluation metrics will lead to rapid progress in segmentation methods that improve boundary quality.