 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Prompting for Conversational Tasks: A Comparative Analysis of Large Language Models Across Diverse Conversational Tasks
Nov 26, 2024



Given the advancements in conversational artificial intelligence, the evaluation and assessment of Large Language Models (LLMs) play a crucial role in ensuring optimal performance across various conversational tasks. In this paper, we present a comprehensive study that thoroughly evaluates the capabilities and limitations of five prevalent LLMs: Llama, OPT, Falcon, Alpaca, and MPT. The study encompasses various conversational tasks, including reservation, empathetic response generation, mental health and legal counseling, persuasion, and negotiation. To conduct the evaluation, an extensive test setup is employed, utilizing multiple evaluation criteria that span from automatic to human evaluation. This includes using generic and task-specific metrics to gauge the LMs' performance accurately. From our evaluation, no single model emerges as universally optimal for all tasks. Instead, their performance varies significantly depending on the specific requirements of each task. While some models excel in certain tasks, they may demonstrate comparatively poorer performance in others. These findings emphasize the importance of considering task-specific requirements and characteristics when selecting the most suitable LM for conversational applications.
EmoInHindi: A Multi-label Emotion and Intensity Annotated Dataset in Hindi for Emotion Recognition in Dialogues
May 27, 2022
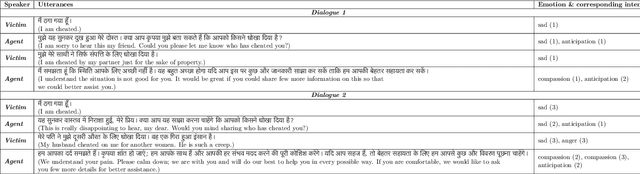
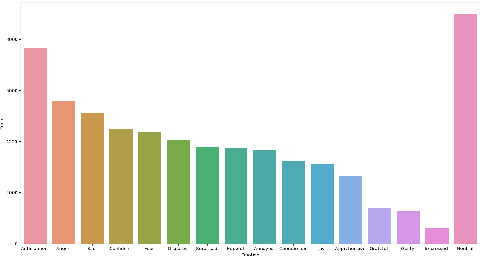
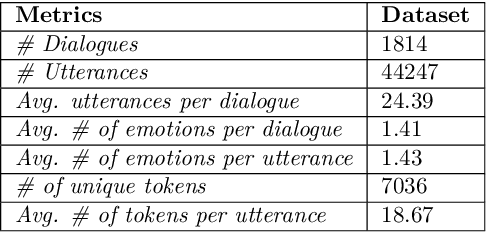
The long-standing goal of Artificial Intelligence (AI) has been to create human-like conversational systems. Such systems should have the ability to develop an emotional connection with the users, hence emotion recognition in dialogues is an important task. Emotion detection in dialogues is a challenging task because humans usually convey multiple emotions with varying degrees of intensities in a single utterance. Moreover, emotion in an utterance of a dialogue may be dependent on previous utterances making the task more complex. Emotion recognition has always been in great demand. However, most of the existing datasets for multi-label emotion and intensity detection in conversations are in English. To this end, we create a large conversational dataset in Hindi named EmoInHindi for multi-label emotion and intensity recognition in conversations containing 1,814 dialogues with a total of 44,247 utterances. We prepare our dataset in a Wizard-of-Oz manner for mental health and legal counselling of crime victims. Each utterance of the dialogue is annotated with one or more emotion categories from the 16 emotion classes including neutral, and their corresponding intensity values. We further propose strong contextual baselines that can detect emotion(s) and the corresponding intensity of an utterance given the conversational context.