 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Slot based Response Generation in a Multimodal Dialogue System
May 27, 2023



Natural Language Understanding (NLU) and Natural Language Generation (NLG) are the two critical components of every conversational system that handles the task of understanding the user by capturing the necessary information in the form of slots and generating an appropriate response in accordance with the extracted information. Recently, dialogue systems integrated with complementary information such as images, audio, or video have gained immense popularity. In this work, we propose an end-to-end framework with the capability to extract necessary slot values from the utterance and generate a coherent response, thereby assisting the user to achieve their desired goals in a multimodal dialogue system having both textual and visual information. The task of extracting the necessary information is dependent not only on the text but also on the visual cues present in the dialogue. Similarly, for the generation, the previous dialog context comprising multimodal information is significant for providing coherent and informative responses. We employ a multimodal hierarchical encoder using pre-trained DialoGPT and also exploit the knowledge base (Kb) to provide a stronger context for both the tasks. Finally, we design a slot attention mechanism to focus on the necessary information in a given utterance. Lastly, a decoder generates the corresponding response for the given dialogue context and the extracted slot values. Experimental results on the Multimodal Dialogue Dataset (MMD) show that the proposed framework outperforms the baselines approaches in both the tasks. The code is available at https://github.com/avinashsai/slot-gpt.
Prompt-Based Editing for Text Style Transfer
Jan 27, 2023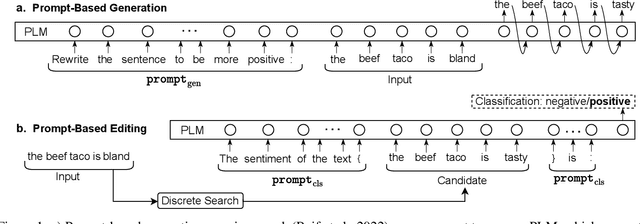
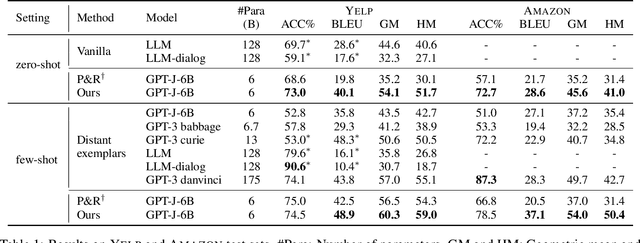

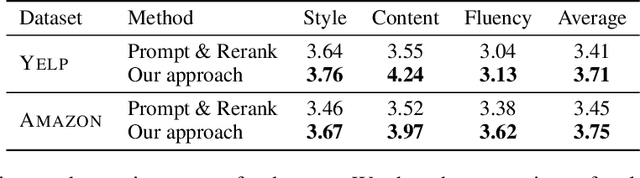
Prompting approaches have been recently explored in text style transfer, where a textual prompt is used to query a pretrained language model to generate style-transferred texts word by word in an autoregressive manner. However, such a generation process is less controllable and early prediction errors may affect future word predictions. In this paper, we present a prompt-based editing approach for text style transfer. Specifically, we prompt a pretrained language model for style classification and use the classification probability to compute a style score. Then, we perform discrete search with word-level editing to maximize a comprehensive scoring function for the style-transfer task. In this way, we transform a prompt-based generation problem into a classification one, which is a training-free process and more controllable than the autoregressive generation of sentences. In our experiments, we performed both automatic and human evaluation on three style-transfer benchmark datasets, and show that our approach largely outperforms the state-of-the-art systems that have 20 times more parameters. Additional empirical analyses further demonstrate the effectiveness of our approach.
A Unified Framework for Emotion Identification and Generation in Dialogues
May 31, 2022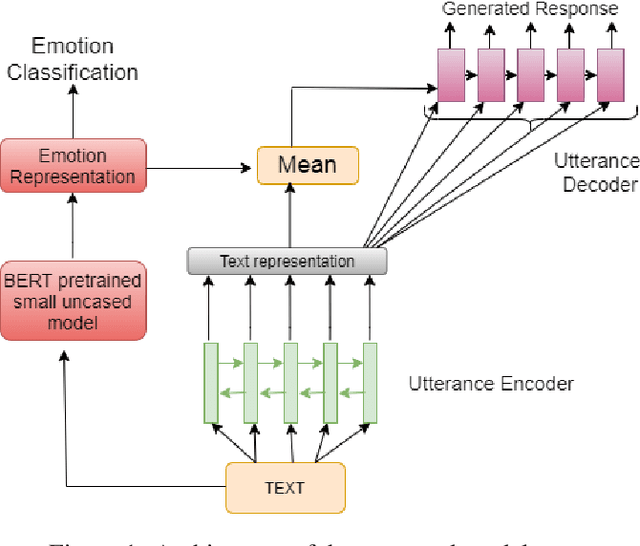
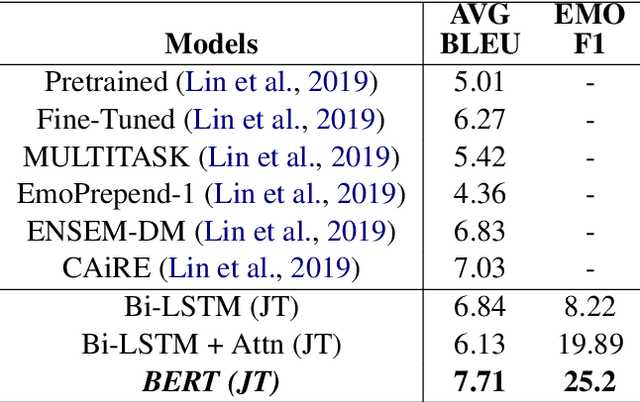
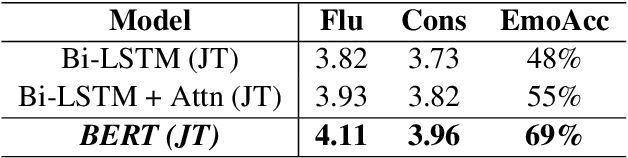
Social chatbots have gained immense popularity, and their appeal lies not just in their capacity to respond to the diverse requests from users, but also in the ability to develop an emotional connection with users. To further develop and promote social chatbots, we need to concentrate on increasing user interaction and take into account both the intellectual and emotional quotient in the conversational agents. In this paper, we propose a multi-task framework that jointly identifies the emotion of a given dialogue and generates response in accordance to the identified emotion. We employ a BERT based network for creating an empathetic system and use a mixed objective function that trains the end-to-end network with both the classification and generation loss. Experimental results show that our proposed framework outperforms current state-of-the-art models
EmoInHindi: A Multi-label Emotion and Intensity Annotated Dataset in Hindi for Emotion Recognition in Dialogues
May 27, 2022
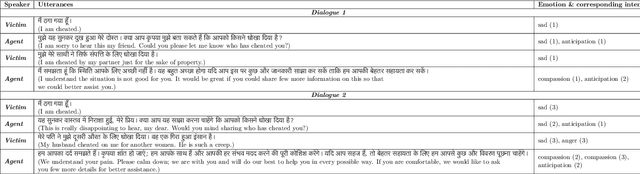
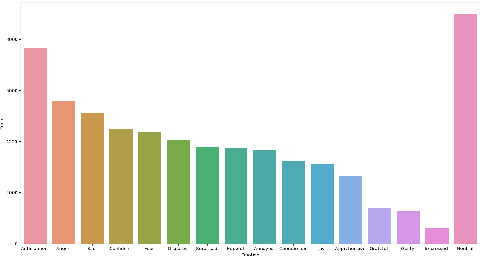
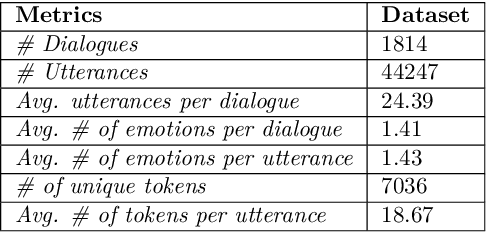
The long-standing goal of Artificial Intelligence (AI) has been to create human-like conversational systems. Such systems should have the ability to develop an emotional connection with the users, hence emotion recognition in dialogues is an important task. Emotion detection in dialogues is a challenging task because humans usually convey multiple emotions with varying degrees of intensities in a single utterance. Moreover, emotion in an utterance of a dialogue may be dependent on previous utterances making the task more complex. Emotion recognition has always been in great demand. However, most of the existing datasets for multi-label emotion and intensity detection in conversations are in English. To this end, we create a large conversational dataset in Hindi named EmoInHindi for multi-label emotion and intensity recognition in conversations containing 1,814 dialogues with a total of 44,247 utterances. We prepare our dataset in a Wizard-of-Oz manner for mental health and legal counselling of crime victims. Each utterance of the dialogue is annotated with one or more emotion categories from the 16 emotion classes including neutral, and their corresponding intensity values. We further propose strong contextual baselines that can detect emotion(s) and the corresponding intensity of an utterance given the conversational context.