 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Persona Thinking for Bias Mitigation in Large Language Models
Jan 21, 2026Large Language Models (LLMs) exhibit significant social biases that can perpetuate harmful stereotypes and unfair outcomes. In this paper, we propose Multi-Persona Thinking (MPT), a novel inference-time framework that leverages dialectical reasoning from multiple perspectives to reduce bias. MPT guides models to adopt contrasting social identities (e.g., male and female) along with a neutral viewpoint, and then engages these personas iteratively to expose and correct biases. Through a dialectical reasoning process, the framework transforms the potential weakness of persona assignment into a strength for bias mitigation. We evaluate MPT on two widely used bias benchmarks across both open-source and closed-source models of varying scales. Our results demonstrate substantial improvements over existing prompting-based strategies: MPT achieves the lowest bias while maintaining core reasoning ability.
KETCHUP: K-Step Return Estimation for Sequential Knowledge Distillation
Apr 26, 2025We propose a novel k-step return estimation method (called KETCHUP) for Reinforcement Learning(RL)-based knowledge distillation (KD) in text generation tasks. Our idea is to induce a K-step return by using the Bellman Optimality Equation for multiple steps. Theoretical analysis shows that this K-step formulation reduces the variance of the gradient estimates, thus leading to improved RL optimization especially when the student model size is large. Empirical evaluation on three text generation tasks demonstrates that our approach yields superior performance in both standard task metrics and large language model (LLM)-based evaluation. These results suggest that our K-step return induction offers a promising direction for enhancing RL-based KD in LLM research.
Prompt-Based Editing for Text Style Transfer
Jan 27, 2023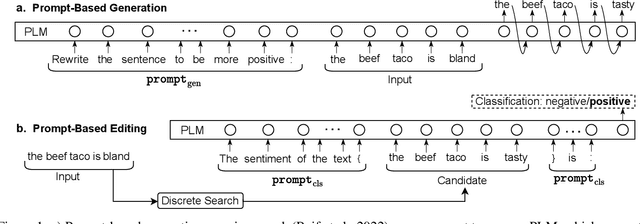
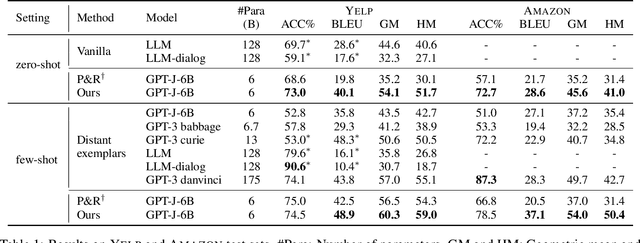

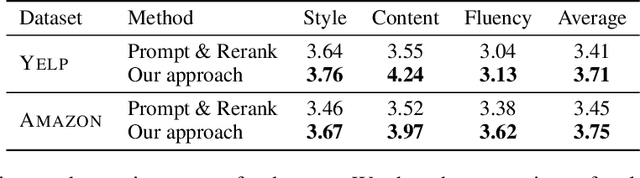
Prompting approaches have been recently explored in text style transfer, where a textual prompt is used to query a pretrained language model to generate style-transferred texts word by word in an autoregressive manner. However, such a generation process is less controllable and early prediction errors may affect future word predictions. In this paper, we present a prompt-based editing approach for text style transfer. Specifically, we prompt a pretrained language model for style classification and use the classification probability to compute a style score. Then, we perform discrete search with word-level editing to maximize a comprehensive scoring function for the style-transfer task. In this way, we transform a prompt-based generation problem into a classification one, which is a training-free process and more controllable than the autoregressive generation of sentences. In our experiments, we performed both automatic and human evaluation on three style-transfer benchmark datasets, and show that our approach largely outperforms the state-of-the-art systems that have 20 times more parameters. Additional empirical analyses further demonstrate the effectiveness of our approach.
An Empirical Study on the Overlapping Problem of Open-Domain Dialogue Datasets
Jan 17, 2022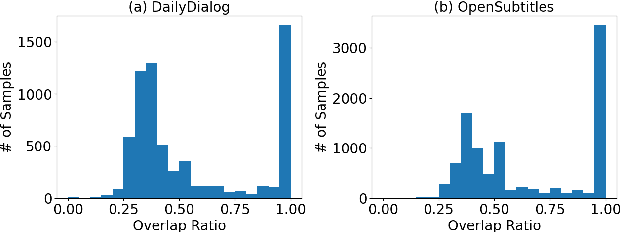

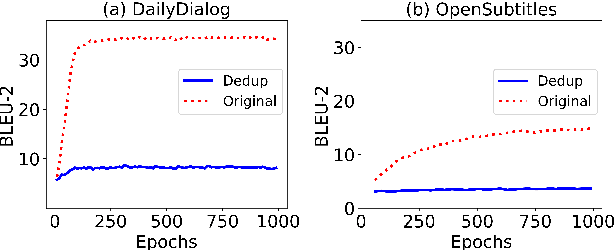

Open-domain dialogue systems aim to converse with humans through text, and its research has heavily relied on benchmark datasets. In this work, we first identify the overlapping problem in DailyDialog and OpenSubtitles, two popular open-domain dialogue benchmark datasets. Our systematic analysis then shows that such overlapping can be exploited to obtain fake state-of-the-art performance. Finally, we address this issue by cleaning these datasets and setting up a proper data processing procedure for future research.
Speaker-Oriented Latent Structures for Dialogue-Based Relation Extraction
Sep 11, 2021
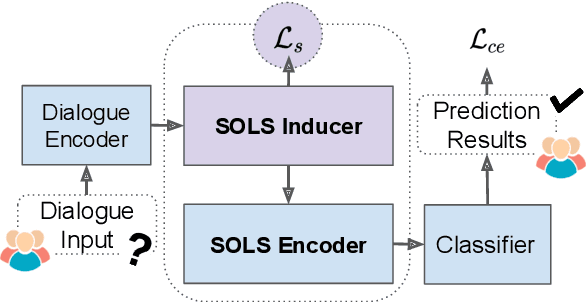
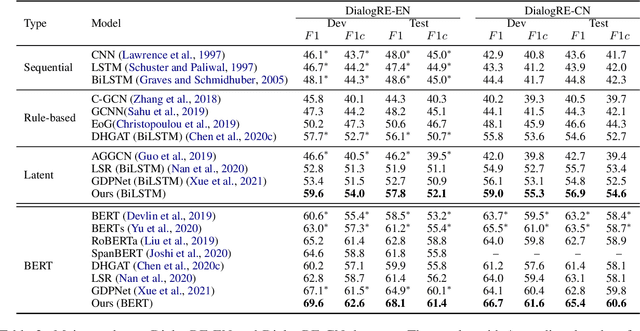
Dialogue-based relation extraction (DiaRE) aims to detect the structural information from unstructured utterances in dialogues. Existing relation extraction models may be unsatisfactory under such a conversational setting, due to the entangled logic and information sparsity issues in utterances involving multiple speakers. To this end, we introduce SOLS, a novel model which can explicitly induce speaker-oriented latent structures for better DiaRE. Specifically, we learn latent structures to capture the relationships among tokens beyond the utterance boundaries, alleviating the entangled logic issue. During the learning process, our speaker-specific regularization method progressively highlights speaker-related key clues and erases the irrelevant ones, alleviating the information sparsity issue. Experiments on three public datasets demonstrate the effectiveness of our proposed approach.
RDSGAN: Rank-based Distant Supervision Relation Extraction with Generative Adversarial Framework
Sep 30, 2020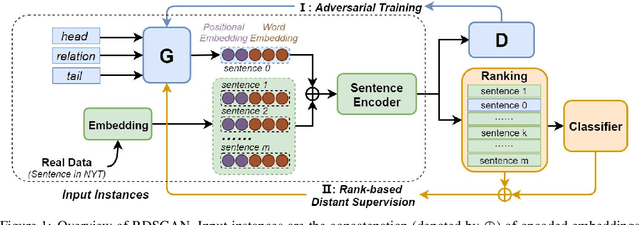
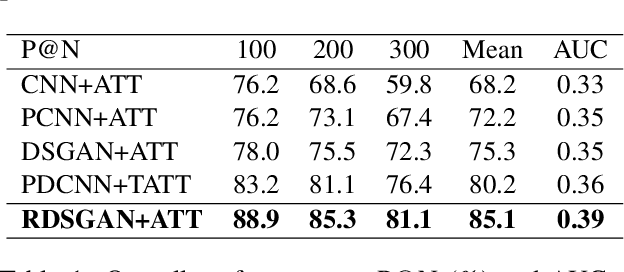
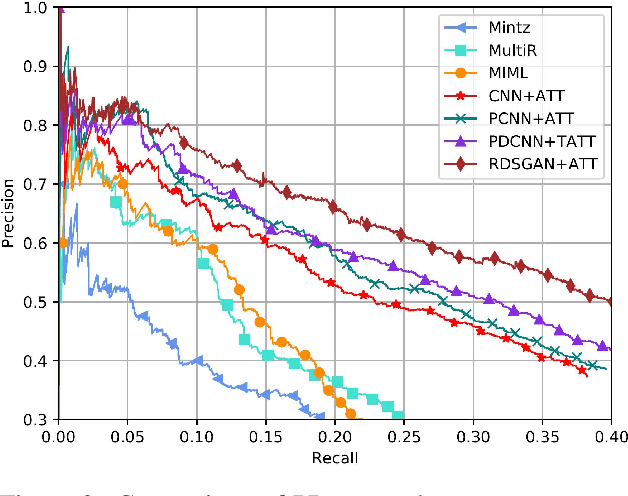
Distant supervision has been widely used for relation extraction but suffers from noise labeling problem. Neural network models are proposed to denoise with attention mechanism but cannot eliminate noisy data due to its non-zero weights. Hard decision is proposed to remove wrongly-labeled instances from the positive set though causes loss of useful information contained in removed instances. In this paper, we propose a novel generative neural framework named RDSGAN (Rank-based Distant Supervision GAN) which automatically generates valid instances for distant supervision relation extraction. Our framework combines soft attention and hard decision to learn the distribution of true positive instances via adversarial training and selects valid instances conforming to the distribution via rank-based distant supervision, which addresses the false positive problem. Experimental results show the superiority of our framework over strong baselines.