Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on the Overlapping Problem of Open-Domain Dialogue Datasets
Paper and Code
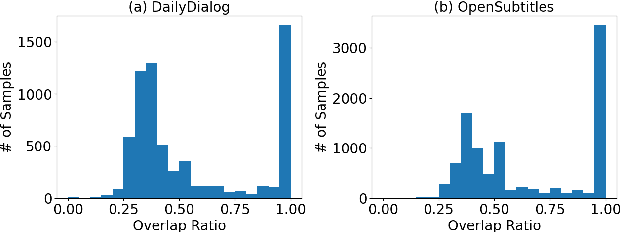

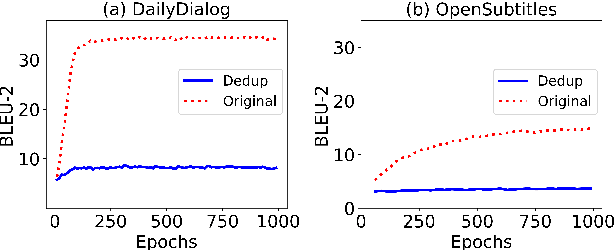

Open-domain dialogue systems aim to converse with humans through text, and its research has heavily relied on benchmark datasets. In this work, we first identify the overlapping problem in DailyDialog and OpenSubtitles, two popular open-domain dialogue benchmark datasets. Our systematic analysis then shows that such overlapping can be exploited to obtain fake state-of-the-art performance. Finally, we address this issue by cleaning these datasets and setting up a proper data processing procedure for future research.
View paper on