 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust a Scratch: Enhancing LLM Capabilities for Self-harm Detection through Intent Differentiation and Emoji Interpretation
Jun 05, 2025Self-harm detection on social media is critical for early intervention and mental health support, yet remains challenging due to the subtle, context-dependent nature of such expressions. Identifying self-harm intent aids suicide prevention by enabling timely responses, but current large language models (LLMs) struggle to interpret implicit cues in casual language and emojis. This work enhances LLMs' comprehension of self-harm by distinguishing intent through nuanced language-emoji interplay. We present the Centennial Emoji Sensitivity Matrix (CESM-100), a curated set of 100 emojis with contextual self-harm interpretations and the Self-Harm Identification aNd intent Extraction with Supportive emoji sensitivity (SHINES) dataset, offering detailed annotations for self-harm labels, casual mentions (CMs), and serious intents (SIs). Our unified framework: a) enriches inputs using CESM-100; b) fine-tunes LLMs for multi-task learning: self-harm detection (primary) and CM/SI span detection (auxiliary); c) generates explainable rationales for self-harm predictions. We evaluate the framework on three state-of-the-art LLMs-Llama 3, Mental-Alpaca, and MentalLlama, across zero-shot, few-shot, and fine-tuned scenarios. By coupling intent differentiation with contextual cues, our approach commendably enhances LLM performance in both detection and explanation tasks, effectively addressing the inherent ambiguity in self-harm signals. The SHINES dataset, CESM-100 and codebase are publicly available at: https://www.iitp.ac.in/~ai-nlp-ml/resources.html#SHINES .
EmoInHindi: A Multi-label Emotion and Intensity Annotated Dataset in Hindi for Emotion Recognition in Dialogues
May 27, 2022
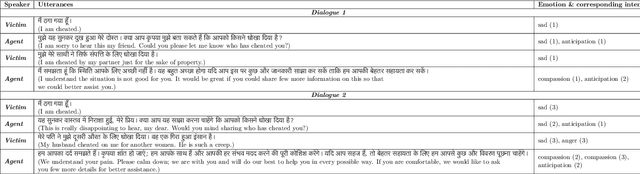
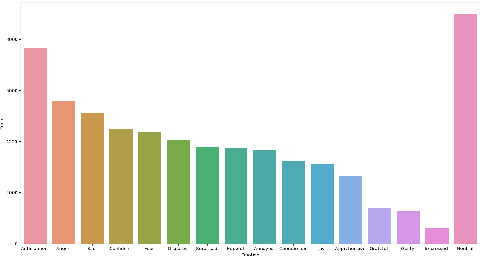
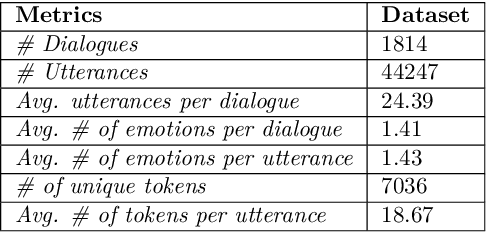
The long-standing goal of Artificial Intelligence (AI) has been to create human-like conversational systems. Such systems should have the ability to develop an emotional connection with the users, hence emotion recognition in dialogues is an important task. Emotion detection in dialogues is a challenging task because humans usually convey multiple emotions with varying degrees of intensities in a single utterance. Moreover, emotion in an utterance of a dialogue may be dependent on previous utterances making the task more complex. Emotion recognition has always been in great demand. However, most of the existing datasets for multi-label emotion and intensity detection in conversations are in English. To this end, we create a large conversational dataset in Hindi named EmoInHindi for multi-label emotion and intensity recognition in conversations containing 1,814 dialogues with a total of 44,247 utterances. We prepare our dataset in a Wizard-of-Oz manner for mental health and legal counselling of crime victims. Each utterance of the dialogue is annotated with one or more emotion categories from the 16 emotion classes including neutral, and their corresponding intensity values. We further propose strong contextual baselines that can detect emotion(s) and the corresponding intensity of an utterance given the conversational context.
M2H2: A Multimodal Multiparty Hindi Dataset For Humor Recognition in Conversations
Aug 03, 2021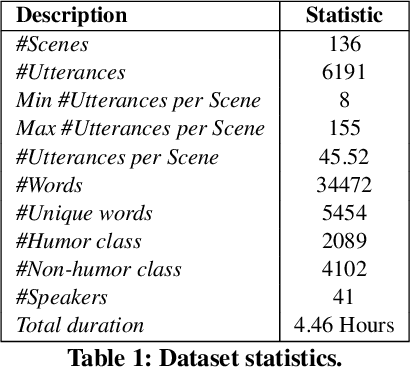


Humor recognition in conversations is a challenging task that has recently gained popularity due to its importance in dialogue understanding, including in multimodal settings (i.e., text, acoustics, and visual). The few existing datasets for humor are mostly in English. However, due to the tremendous growth in multilingual content, there is a great demand to build models and systems that support multilingual information access. To this end, we propose a dataset for Multimodal Multiparty Hindi Humor (M2H2) recognition in conversations containing 6,191 utterances from 13 episodes of a very popular TV series "Shrimaan Shrimati Phir Se". Each utterance is annotated with humor/non-humor labels and encompasses acoustic, visual, and textual modalities. We propose several strong multimodal baselines and show the importance of contextual and multimodal information for humor recognition in conversations. The empirical results on M2H2 dataset demonstrate that multimodal information complements unimodal information for humor recognition. The dataset and the baselines are available at http://www.iitp.ac.in/~ai-nlp-ml/resources.html and https://github.com/declare-lab/M2H2-dataset.