 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2H2: A Multimodal Multiparty Hindi Dataset For Humor Recognition in Conversations
Aug 03, 2021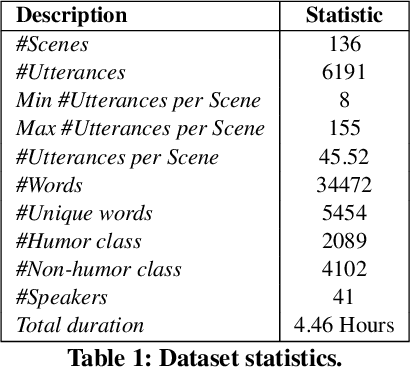


Humor recognition in conversations is a challenging task that has recently gained popularity due to its importance in dialogue understanding, including in multimodal settings (i.e., text, acoustics, and visual). The few existing datasets for humor are mostly in English. However, due to the tremendous growth in multilingual content, there is a great demand to build models and systems that support multilingual information access. To this end, we propose a dataset for Multimodal Multiparty Hindi Humor (M2H2) recognition in conversations containing 6,191 utterances from 13 episodes of a very popular TV series "Shrimaan Shrimati Phir Se". Each utterance is annotated with humor/non-humor labels and encompasses acoustic, visual, and textual modalities. We propose several strong multimodal baselines and show the importance of contextual and multimodal information for humor recognition in conversations. The empirical results on M2H2 dataset demonstrate that multimodal information complements unimodal information for humor recognition. The dataset and the baselines are available at http://www.iitp.ac.in/~ai-nlp-ml/resources.html and https://github.com/declare-lab/M2H2-dataset.
Bi-Bimodal Modality Fusion for Correlation-Controlled Multimodal Sentiment Analysis
Jul 28, 2021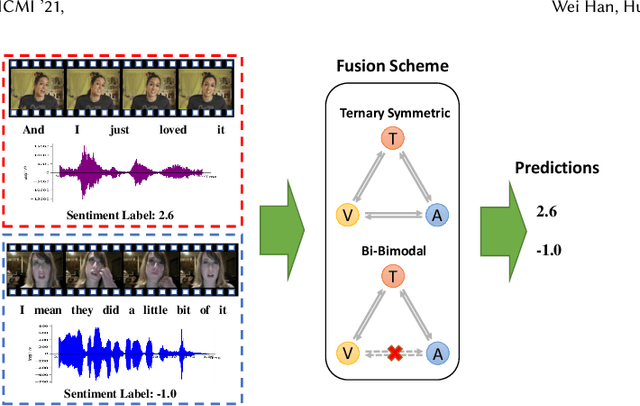
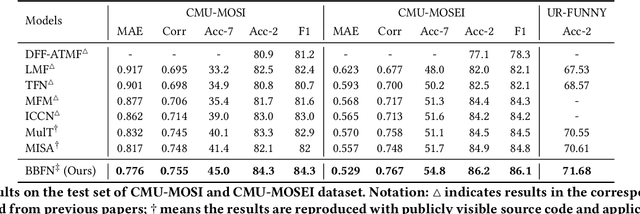
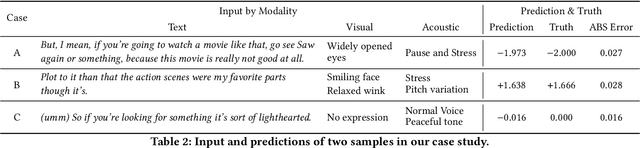
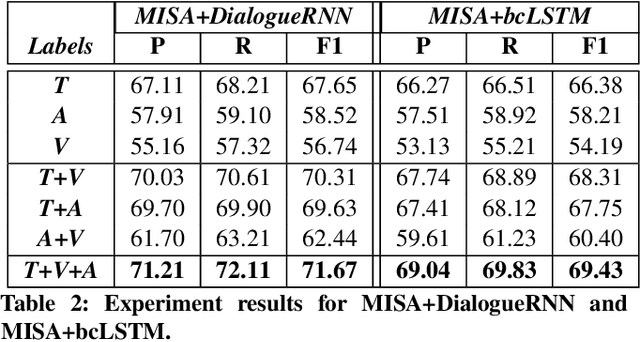
Multimodal sentiment analysis aims to extract and integrate semantic information collected from multiple modalities to recognize the expressed emotions and sentiment in multimodal data. This research area's major concern lies in developing an extraordinary fusion scheme that can extract and integrate key information from various modalities. However, one issue that may restrict previous work to achieve a higher level is the lack of proper modeling for the dynamics of the competition between the independence and relevance among modalities, which could deteriorate fusion outcomes by causing the collapse of modality-specific feature space or introducing extra noise. To mitigate this, we propose the Bi-Bimodal Fusion Network (BBFN), a novel end-to-end network that performs fusion (relevance increment) and separation (difference increment) on pairwise modality representations. The two parts are trained simultaneously such that the combat between them is simulated. The model takes two bimodal pairs as input due to the known information imbalance among modalities. In addition, we leverage a gated control mechanism in the Transformer architecture to further improve the final output. Experimental results on three datasets (CMU-MOSI, CMU-MOSEI, and UR-FUNNY) verifies that our model significantly outperforms the SOTA. The implementation of this work is available at https://github.com/declare-lab/BBFN.
Hand2Face: Automatic Synthesis and Recognition of Hand Over Face Occlusions
Aug 17, 2017
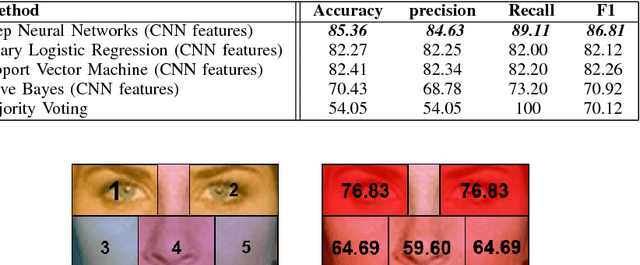


A person's face discloses important information about their affective state. Although there has been extensive research on recognition of facial expressions, the performance of existing approaches is challenged by facial occlusions. Facial occlusions are often treated as noise and discarded in recognition of affective states. However, hand over face occlusions can provide additional information for recognition of some affective states such as curiosity, frustration and boredom. One of the reasons that this problem has not gained attention is the lack of naturalistic occluded faces that contain hand over face occlusions as well as other types of occlusions. Traditional approaches for obtaining affective data are time demanding and expensive, which limits researchers in affective computing to work on small datasets. This limitation affects the generalizability of models and deprives researchers from taking advantage of recent advances in deep learning that have shown great success in many fields but require large volumes of data. In this paper, we first introduce a novel framework for synthesizing naturalistic facial occlusions from an initial dataset of non-occluded faces and separate images of hands, reducing the costly process of data collection and annotation. We then propose a model for facial occlusion type recognition to differentiate between hand over face occlusions and other types of occlusions such as scarves, hair, glasses and objects. Finally, we present a model to localize hand over face occlusions and identify the occluded regions of the face.