 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAIGR: Towards Modeling Influencer Content on Social Media via Structured, Pragmatic Inference
Jan 27, 2026Health influencers play a growing role in shaping public beliefs, yet their content is often conveyed through conversational narratives and rhetorical strategies rather than explicit factual claims. As a result, claim-centric verification methods struggle to capture the pragmatic meaning of influencer discourse. In this paper, we propose TAIGR (Takeaway Argumentation Inference with Grounded References), a structured framework designed to analyze influencer discourse, which operates in three stages: (1) identifying the core influencer recommendation--takeaway; (2) constructing an argumentation graph that captures influencer justification for the takeaway; (3) performing factor graph-based probabilistic inference to validate the takeaway. We evaluate TAIGR on a content validation task over influencer video transcripts on health, showing that accurate validation requires modeling the discourse's pragmatic and argumentative structure rather than treating transcripts as flat collections of claims.
LLM-Human Pipeline for Cultural Context Grounding of Conversations
Oct 17, 2024Conversations often adhere to well-understood social norms that vary across cultures. For example, while "addressing parents by name" is commonplace in the West, it is rare in most Asian cultures. Adherence or violation of such norms often dictates the tenor of conversations. Humans are able to navigate social situations requiring cultural awareness quite adeptly. However, it is a hard task for NLP models. In this paper, we tackle this problem by introducing a "Cultural Context Schema" for conversations. It comprises (1) conversational information such as emotions, dialogue acts, etc., and (2) cultural information such as social norms, violations, etc. We generate ~110k social norm and violation descriptions for ~23k conversations from Chinese culture using LLMs. We refine them using automated verification strategies which are evaluated against culturally aware human judgements. We organize these descriptions into meaningful structures we call "Norm Concepts", using an interactive human-in-loop framework. We ground the norm concepts and the descriptions in conversations using symbolic annotation. Finally, we use the obtained dataset for downstream tasks such as emotion, sentiment, and dialogue act detection. We show that it significantly improves the empirical performance.
"We Demand Justice!": Towards Grounding Political Text in Social Context
Nov 15, 2023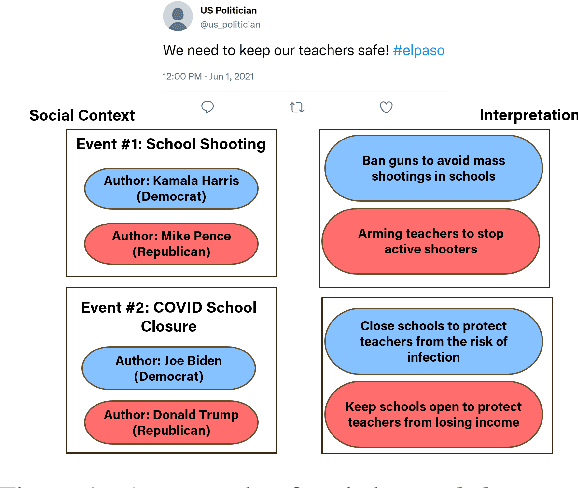
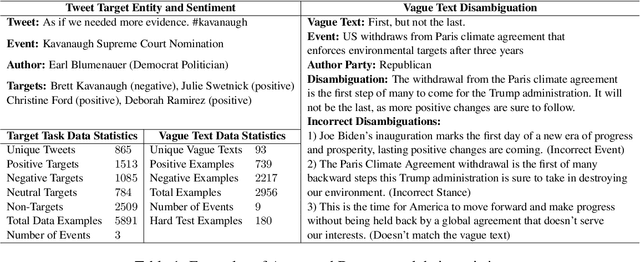
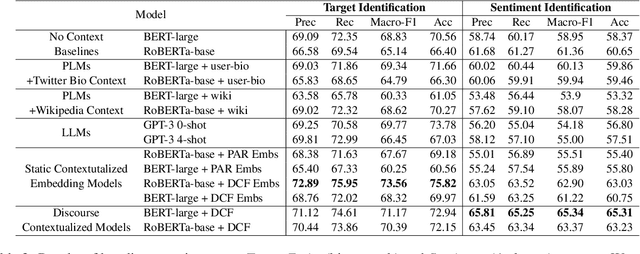
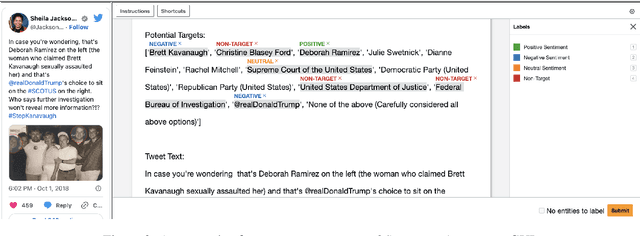
Social media discourse from US politicians frequently consists of 'seemingly similar language used by opposing sides of the political spectrum'. But often, it translates to starkly contrasting real-world actions. For instance, "We need to keep our students safe from mass shootings" may signal either "arming teachers to stop the shooter" or "banning guns to reduce mass shootings" depending on who says it and their political stance on the issue. In this paper, we define and characterize the context that is required to fully understand such ambiguous statements in a computational setting and ground them in real-world entities, actions, and attitudes. To that end, we propose two challenging datasets that require an understanding of the real-world context of the text to be solved effectively. We benchmark these datasets against baselines built upon large pre-trained models such as BERT, RoBERTa, GPT-3, etc. Additionally, we develop and benchmark more structured baselines building upon existing 'Discourse Contextualization Framework' and 'Political Actor Representation' models. We perform analysis of the datasets and baseline predictions to obtain further insights into the pragmatic language understanding challenges posed by the proposed social grounding tasks.
Reinforcement Guided Multi-Task Learning Framework for Low-Resource Stereotype Detection
Mar 27, 2022
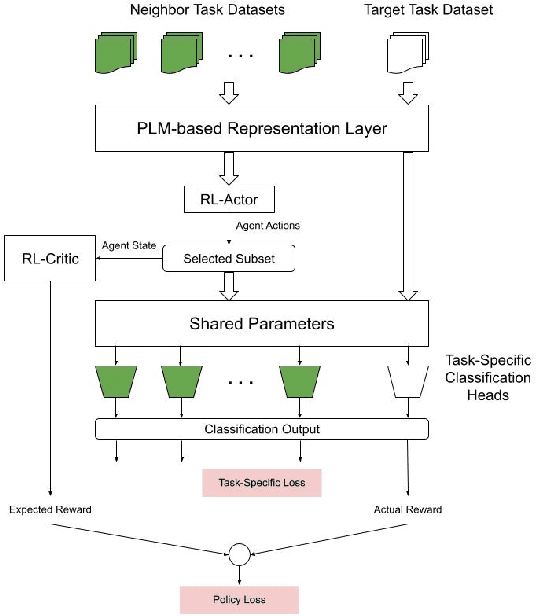

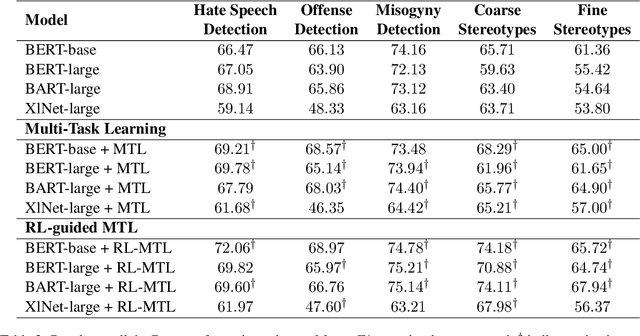
As large Pre-trained Language Models (PLMs) trained on large amounts of data in an unsupervised manner become more ubiquitous, identifying various types of bias in the text has come into sharp focus. Existing "Stereotype Detection" datasets mainly adopt a diagnostic approach toward large PLMs. Blodgett et. al (2021a) show that there are significant reliability issues with the existing benchmark datasets. Annotating a reliable dataset requires a precise understanding of the subtle nuances of how stereotypes manifest in text. In this paper, we annotate a focused evaluation set for "Stereotype Detection" that addresses those pitfalls by de-constructing various ways in which stereotypes manifest in text. Further, we present a multi-task model that leverages the abundance of data-rich neighboring tasks such as hate speech detection, offensive language detection, misogyny detection, etc., to improve the empirical performance on "Stereotype Detection". We then propose a reinforcement-learning agent that guides the multi-task learning model by learning to identify the training examples from the neighboring tasks that help the target task the most. We show that the proposed models achieve significant empirical gains over existing baselines on all the tasks.
A Novel Two-stage Framework for Extracting Opinionated Sentences from News Articles
Jan 24, 2021
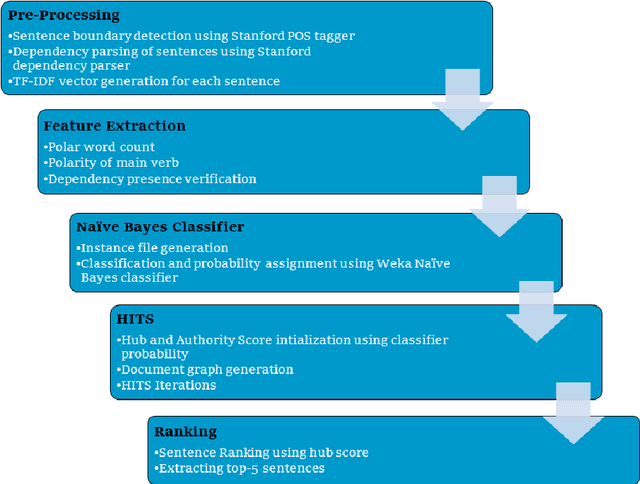
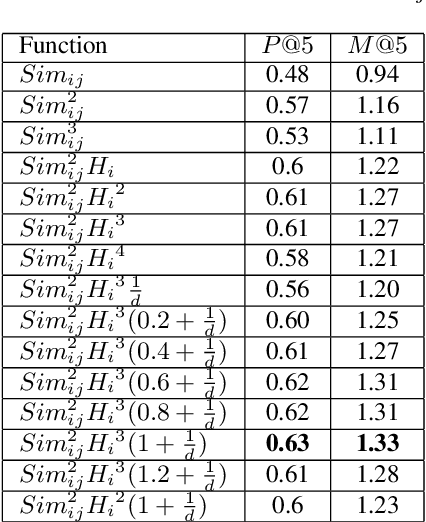
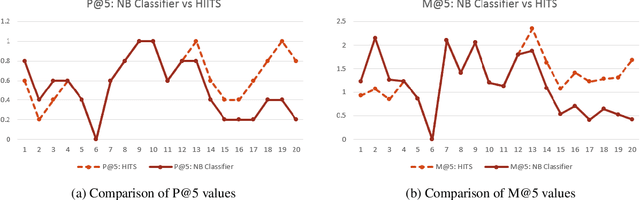
This paper presents a novel two-stage framework to extract opinionated sentences from a given news article. In the first stage, Naive Bayes classifier by utilizing the local features assigns a score to each sentence - the score signifies the probability of the sentence to be opinionated. In the second stage, we use this prior within the HITS (Hyperlink-Induced Topic Search) schema to exploit the global structure of the article and relation between the sentences. In the HITS schema, the opinionated sentences are treated as Hubs and the facts around these opinions are treated as the Authorities. The algorithm is implemented and evaluated against a set of manually marked data. We show that using HITS significantly improves the precision over the baseline Naive Bayes classifier. We also argue that the proposed method actually discovers the underlying structure of the article, thus extracting various opinions, grouped with supporting facts as well as other supporting opinions from the article.
Can Taxonomy Help? Improving Semantic Question Matching using Question Taxonomy
Jan 20, 2021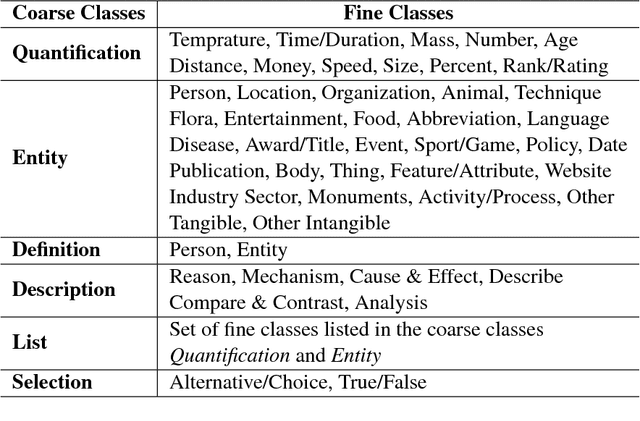
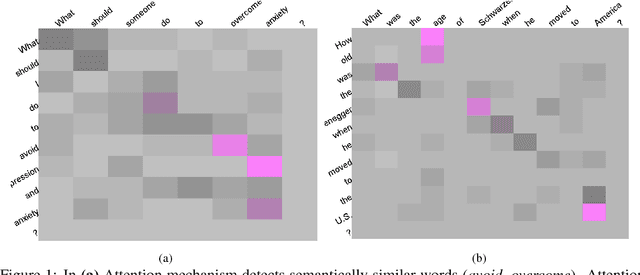
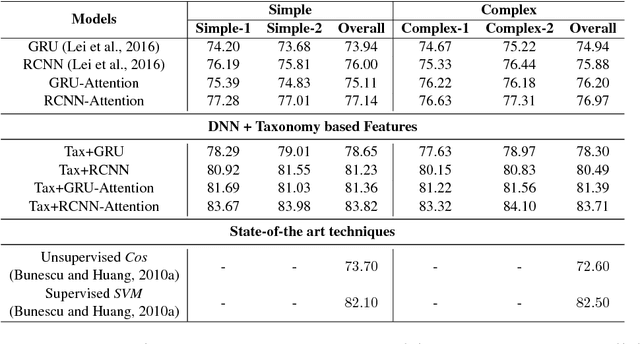
In this paper, we propose a hybrid technique for semantic question matching. It uses our proposed two-layered taxonomy for English questions by augmenting state-of-the-art deep learning models with question classes obtained from a deep learning based question classifier. Experiments performed on three open-domain datasets demonstrate the effectiveness of our proposed approach. We achieve state-of-the-art results on partial ordering question ranking (POQR) benchmark dataset. Our empirical analysis shows that coupling standard distributional features (provided by the question encoder) with knowledge from taxonomy is more effective than either deep learning (DL) or taxonomy-based knowledge alone.
Using Natural Language Relations between Answer Choices for Machine Comprehension
Dec 31, 2020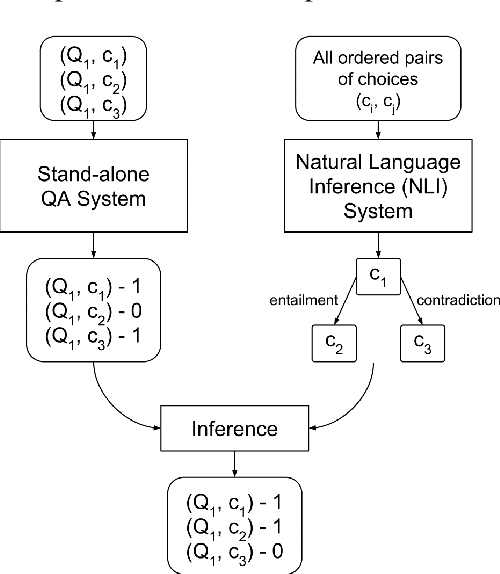
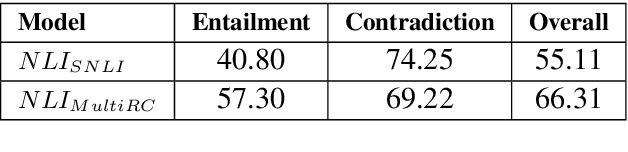
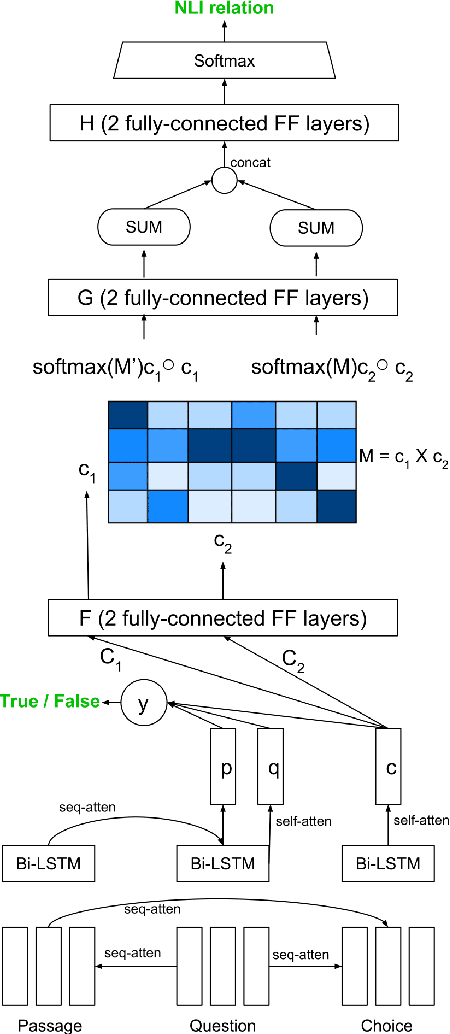
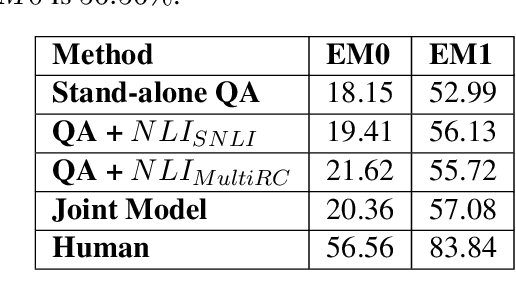
When evaluating an answer choice for Reading Comprehension task, other answer choices available for the question and the answers of related questions about the same paragraph often provide valuable information. In this paper, we propose a method to leverage the natural language relations between the answer choices, such as entailment and contradiction, to improve the performance of machine comprehension. We use a stand-alone question answering (QA) system to perform QA task and a Natural Language Inference (NLI) system to identify the relations between the choice pairs. Then we perform inference using an Integer Linear Programming (ILP)-based relational framework to re-evaluate the decisions made by the standalone QA system in light of the relations identified by the NLI system. We also propose a multitask learning model that learns both the tasks jointly.
* Published at NAACL-HLT 2019. This version has link to code repository. 6 pages, 3 figures & 2 tables
Understanding Politics via Contextualized Discourse Processing
Dec 31, 2020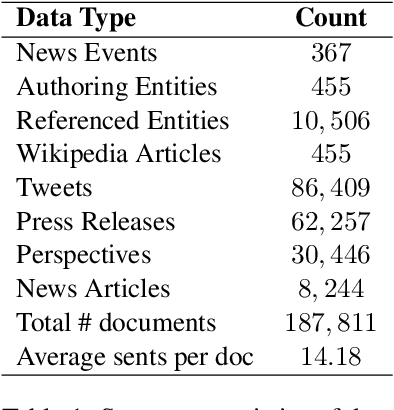
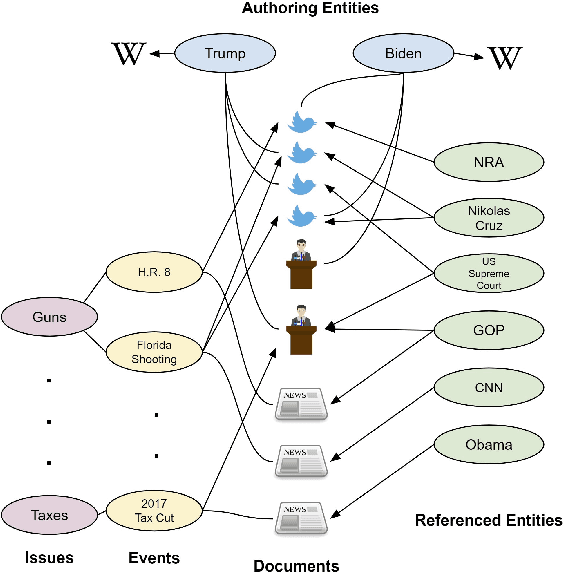
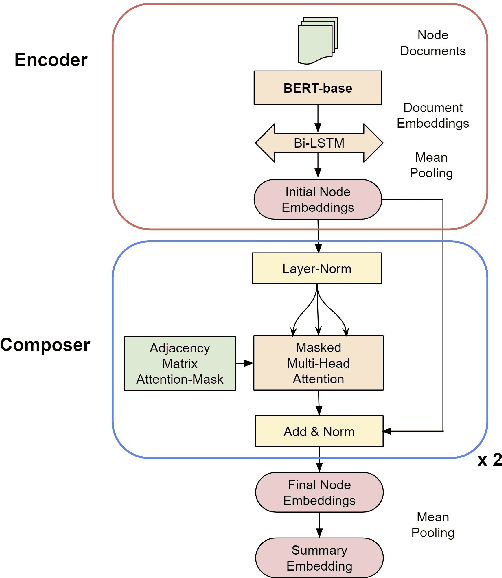
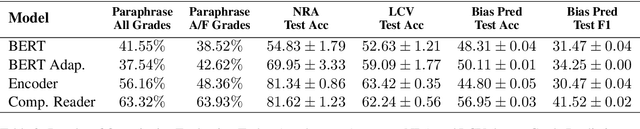
Politicians often have underlying agendas when reacting to events. Arguments in contexts of various events reflect a fairly consistent set of agendas for a given entity. In spite of recent advances in Pretrained Language Models (PLMs), those text representations are not designed to capture such nuanced patterns. In this paper, we propose a Compositional Reader model consisting of encoder and composer modules, that attempts to capture and leverage such information to generate more effective representations for entities, issues, and events. These representations are contextualized by tweets, press releases, issues, news articles, and participating entities. Our model can process several documents at once and generate composed representations for multiple entities over several issues or events. Via qualitative and quantitative empirical analysis, we show that these representations are meaningful and effective.