 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARP: A challenging human-annotated math reasoning benchmark
Dec 11, 2024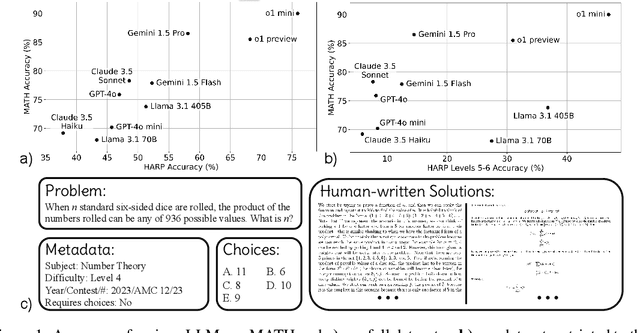

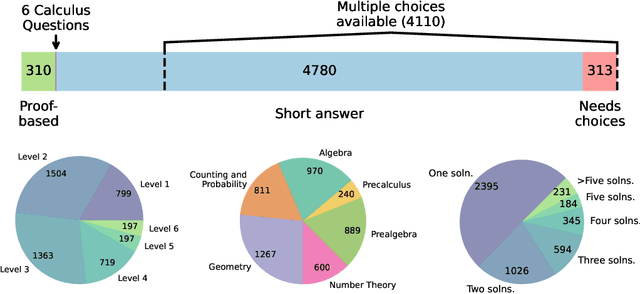

Math reasoning is becoming an ever increasing area of focus as we scale large language models. However, even the previously-toughest evals like MATH are now close to saturated by frontier models (90.0% for o1-mini and 86.5% for Gemini 1.5 Pro). We introduce HARP, Human Annotated Reasoning Problems (for Math), consisting of 5,409 problems from the US national math competitions (A(J)HSME, AMC, AIME, USA(J)MO). Of these, 4,780 have answers that are automatically check-able (with libraries such as SymPy). These problems range six difficulty levels, with frontier models performing relatively poorly on the hardest bracket of 197 problems (average accuracy 41.1% for o1-mini, and 9.6% for Gemini 1.5 Pro). Our dataset also features multiple choices (for 4,110 problems) and an average of two human-written, ground-truth solutions per problem, offering new avenues of research that we explore briefly. We report evaluations for many frontier models and share some interesting analyses, such as demonstrating that frontier models across families intrinsically scale their inference-time compute for more difficult problems. Finally, we open source all code used for dataset construction (including scraping) and all code for evaluation (including answer checking) to enable future research at: https://github.com/aadityasingh/HARP.