 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstration of Robust and Efficient Quantum Property Learning with Shallow Shadows
Feb 27, 2024



Extracting information efficiently from quantum systems is a major component of quantum information processing tasks. Randomized measurements, or classical shadows, enable predicting many properties of arbitrary quantum states using few measurements. While random single qubit measurements are experimentally friendly and suitable for learning low-weight Pauli observables, they perform poorly for nonlocal observables. Prepending a shallow random quantum circuit before measurements maintains this experimental friendliness, but also has favorable sample complexities for observables beyond low-weight Paulis, including high-weight Paulis and global low-rank properties such as fidelity. However, in realistic scenarios, quantum noise accumulated with each additional layer of the shallow circuit biases the results. To address these challenges, we propose the robust shallow shadows protocol. Our protocol uses Bayesian inference to learn the experimentally relevant noise model and mitigate it in postprocessing. This mitigation introduces a bias-variance trade-off: correcting for noise-induced bias comes at the cost of a larger estimator variance. Despite this increased variance, as we demonstrate on a superconducting quantum processor, our protocol correctly recovers state properties such as expectation values, fidelity, and entanglement entropy, while maintaining a lower sample complexity compared to the random single qubit measurement scheme. We also theoretically analyze the effects of noise on sample complexity and show how the optimal choice of the shallow shadow depth varies with noise strength. This combined theoretical and experimental analysis positions the robust shallow shadow protocol as a scalable, robust, and sample-efficient protocol for characterizing quantum states on current quantum computing platforms.
The impact of memory on learning sequence-to-sequence tasks
May 29, 2022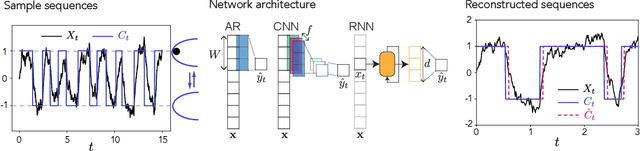
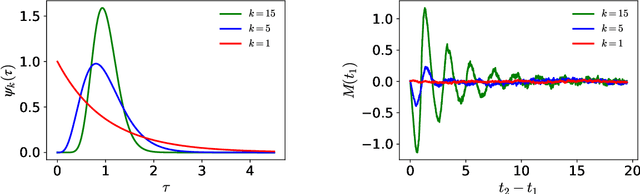
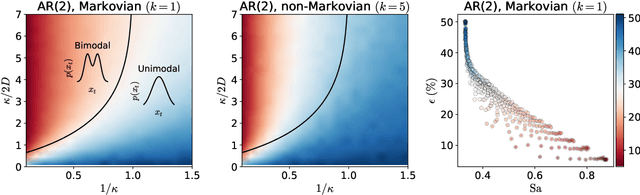
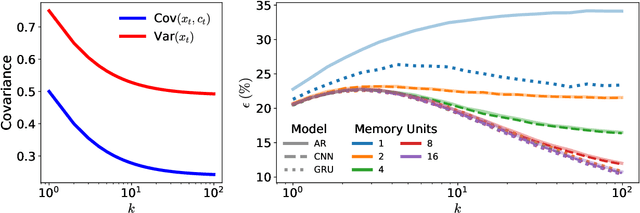
The recent success of neural networks in machine translation and other fields has drawn renewed attention to learning sequence-to-sequence (seq2seq) tasks. While there exists a rich literature that studies classification and regression using solvable models of neural networks, learning seq2seq tasks is significantly less studied from this perspective. Here, we propose a simple model for a seq2seq task that gives us explicit control over the degree of memory, or non-Markovianity, in the sequences -- the stochastic switching-Ornstein-Uhlenbeck (SSOU) model. We introduce a measure of non-Markovianity to quantify the amount of memory in the sequences. For a minimal auto-regressive (AR) learning model trained on this task, we identify two learning regimes corresponding to distinct phases in the stationary state of the SSOU process. These phases emerge from the interplay between two different time scales that govern the sequence statistics. Moreover, we observe that while increasing the memory of the AR model always improves performance, increasing the non-Markovianity of the input sequences can improve or degrade performance. Finally, our experiments with recurrent and convolutional neural networks show that our observations carry over to more complicated neural network architectures.