 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning and Generating Mixed States Prepared by Shallow Channel Circuits
Apr 01, 2026Learning quantum states from measurement data is a central problem in quantum information and computational complexity. In this work, we study the problem of learning to generate mixed states on a finite-dimensional lattice. Motivated by recent developments in mixed state phases of matter, we focus on arbitrary states in the trivial phase. A state belongs to the trivial phase if there exists a shallow preparation channel circuit under which local reversibility is preserved throughout the preparation. We prove that any mixed state in this class can be efficiently learned from measurement access alone. Specifically, given copies of an unknown trivial phase mixed state, our algorithm outputs a shallow local channel circuit that approximately generates this state in trace distance. The sample complexity and runtime are polynomial (or quasi-polynomial) in the number of qubits, assuming constant (or polylogarithmic) circuit depth and gate locality. Importantly, the learner is not given the original preparation circuit and relies only on its existence. Our results provide a structural foundation for quantum generative models based on shallow channel circuits. In the classical limit, our framework also inspires an efficient algorithm for classical diffusion models using only a polynomial overhead of training and generation.
Non-native Quantum Generative Optimization with Adversarial Autoencoders
Jul 18, 2024



Large-scale optimization problems are prevalent in several fields, including engineering, finance, and logistics. However, most optimization problems cannot be efficiently encoded onto a physical system because the existing quantum samplers have too few qubits. Another typical limiting factor is that the optimization constraints are not compatible with the native cost Hamiltonian. This work presents a new approach to address these challenges. We introduce the adversarial quantum autoencoder model (AQAM) that can be used to map large-scale optimization problems onto existing quantum samplers while simultaneously optimizing the problem through latent quantum-enhanced Boltzmann sampling. We demonstrate the AQAM on a neutral atom sampler, and showcase the model by optimizing 64px by 64px unit cells that represent a broad-angle filter metasurface applicable to improving the coherence of neutral atom devices. Using 12-atom simulations, we demonstrate that the AQAM achieves a lower Renyi divergence and a larger spectral gap when compared to classical Markov Chain Monte Carlo samplers. Our work paves the way to more efficient mapping of conventional optimization problems into existing quantum samplers.
Digital-analog quantum learning on Rydberg atom arrays
Jan 05, 2024We propose hybrid digital-analog learning algorithms on Rydberg atom arrays, combining the potentially practical utility and near-term realizability of quantum learning with the rapidly scaling architectures of neutral atoms. Our construction requires only single-qubit operations in the digital setting and global driving according to the Rydberg Hamiltonian in the analog setting. We perform a comprehensive numerical study of our algorithm on both classical and quantum data, given respectively by handwritten digit classification and unsupervised quantum phase boundary learning. We show in the two representative problems that digital-analog learning is not only feasible in the near term, but also requires shorter circuit depths and is more robust to realistic error models as compared to digital learning schemes. Our results suggest that digital-analog learning opens a promising path towards improved variational quantum learning experiments in the near term.
Enhancing Generative Models via Quantum Correlations
Jan 20, 2021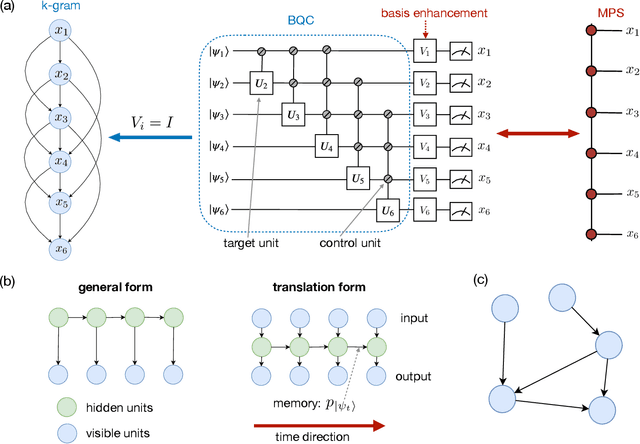
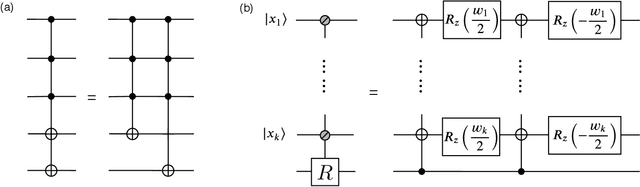
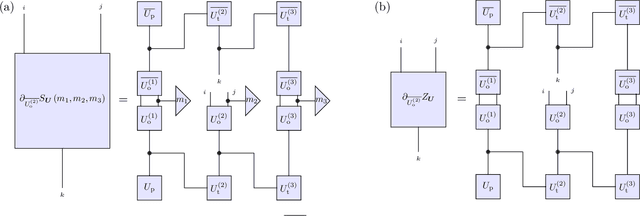
Generative modeling using samples drawn from the probability distribution constitutes a powerful approach for unsupervised machine learning. Quantum mechanical systems can produce probability distributions that exhibit quantum correlations which are difficult to capture using classical models. We show theoretically that such quantum correlations provide a powerful resource for generative modeling. In particular, we provide an unconditional proof of separation in expressive power between a class of widely-used generative models, known as Bayesian networks, and its minimal quantum extension. We show that this expressivity advantage is associated with quantum nonlocality and quantum contextuality. Furthermore, we numerically test this separation on standard machine learning data sets and show that it holds for practical problems. The possibility of quantum advantage demonstrated in this work not only sheds light on the design of useful quantum machine learning protocols but also provides inspiration to draw on ideas from quantum foundations to improve purely classical algorithms.