Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Federated Optimization
Paper and Code
Mar 13, 2019
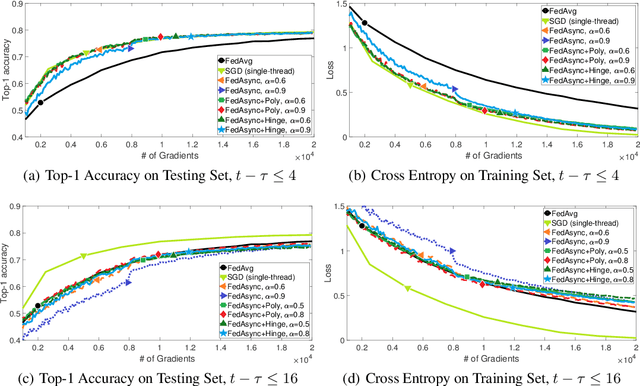
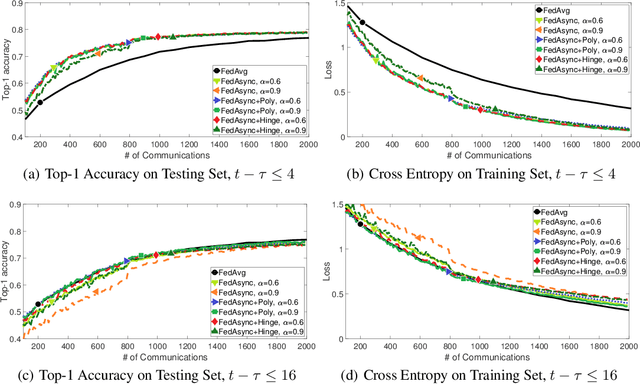
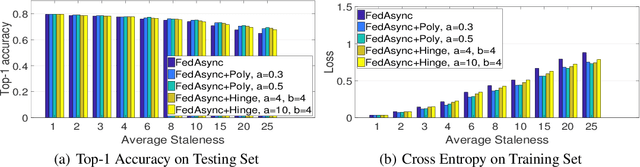
Federated learning enables training on a massive number of edge devices. To improve flexibility and scalability, we propose a new asynchronous federated optimization algorithm. We prove that the proposed approach has near-linear convergence to a global optimum, for both strongly and non-strongly convex problems, as well as a restricted family of non-convex problems. Empirical results show that the proposed algorithm converges fast and tolerates staleness.
View paper on