 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCats, not CAT scans: a study of dataset similarity in transfer learning for 2D medical image classification
Jul 13, 2021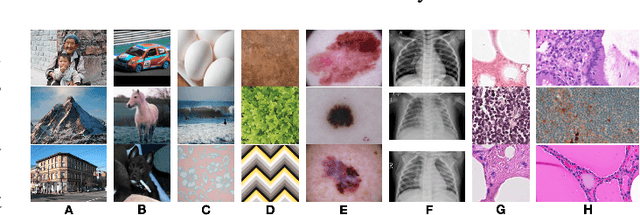
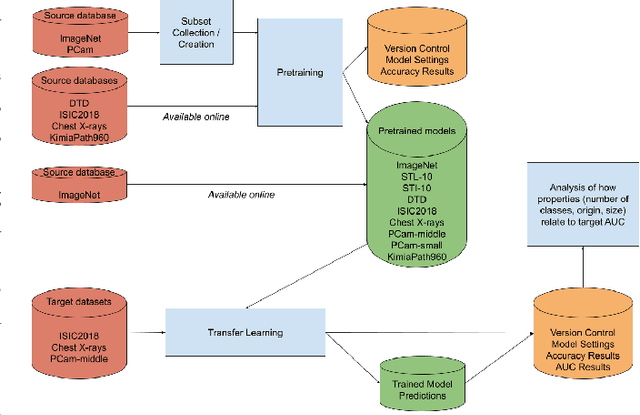
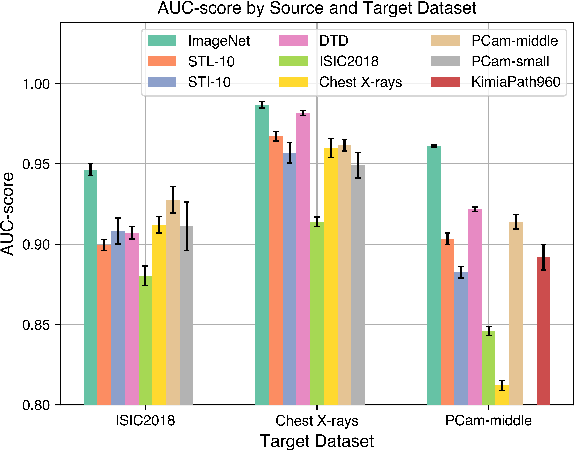
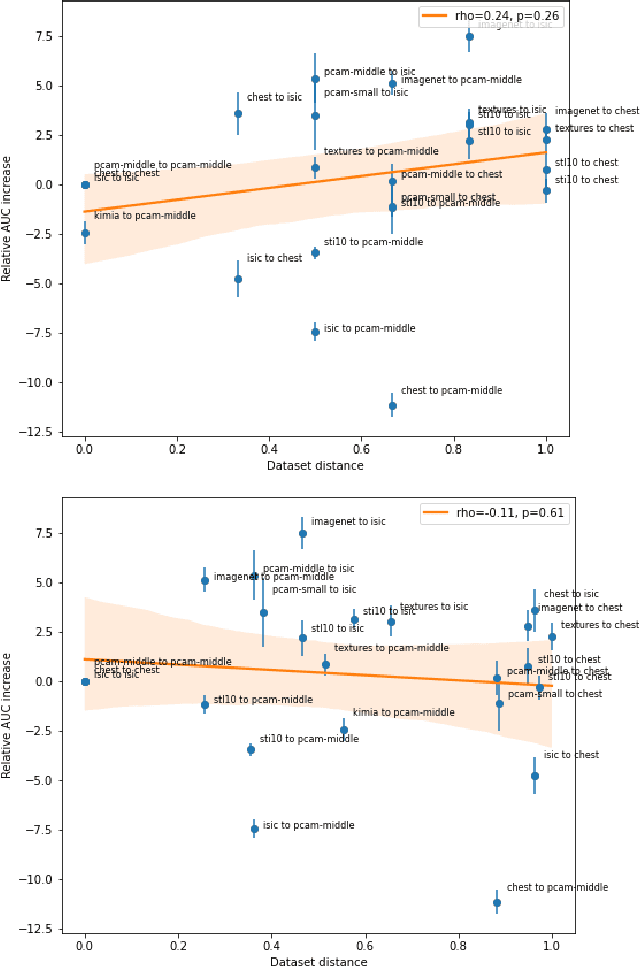
Transfer learning is a commonly used strategy for medical image classification, especially via pretraining on source data and fine-tuning on target data. There is currently no consensus on how to choose appropriate source data, and in the literature we can find both evidence of favoring large natural image datasets such as ImageNet, and evidence of favoring more specialized medical datasets. In this paper we perform a systematic study with nine source datasets with natural or medical images, and three target medical datasets, all with 2D images. We find that ImageNet is the source leading to the highest performances, but also that larger datasets are not necessarily better. We also study different definitions of data similarity. We show that common intuitions about similarity may be inaccurate, and therefore not sufficient to predict an appropriate source a priori. Finally, we discuss several steps needed for further research in this field, especially with regard to other types (for example 3D) medical images. Our experiments and pretrained models are available via \url{https://www.github.com/vcheplygina/cats-scans}