 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Routing: Masking Gradients to Localize Computation in Neural Networks
Paper and Code

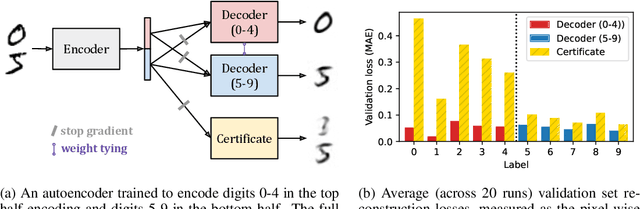

Neural networks are trained primarily based on their inputs and outputs, without regard for their internal mechanisms. These neglected mechanisms determine properties that are critical for safety, like (i) transparency; (ii) the absence of sensitive information or harmful capabilities; and (iii) reliable generalization of goals beyond the training distribution. To address this shortcoming, we introduce gradient routing, a training method that isolates capabilities to specific subregions of a neural network. Gradient routing applies data-dependent, weighted masks to gradients during backpropagation. These masks are supplied by the user in order to configure which parameters are updated by which data points. We show that gradient routing can be used to (1) learn representations which are partitioned in an interpretable way; (2) enable robust unlearning via ablation of a pre-specified network subregion; and (3) achieve scalable oversight of a reinforcement learner by localizing modules responsible for different behaviors. Throughout, we find that gradient routing localizes capabilities even when applied to a limited, ad-hoc subset of the data. We conclude that the approach holds promise for challenging, real-world applications where quality data are scarce.