 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePenalty and Augmented Lagrangian Methods for Layer-parallel Training of Residual Networks
Paper and Code
Sep 03, 2020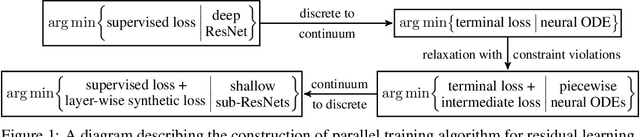

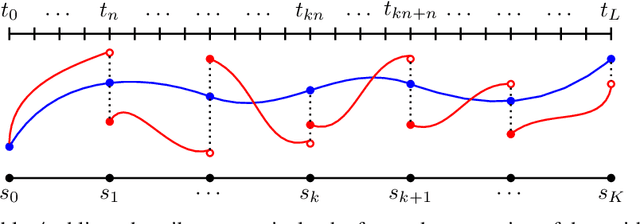
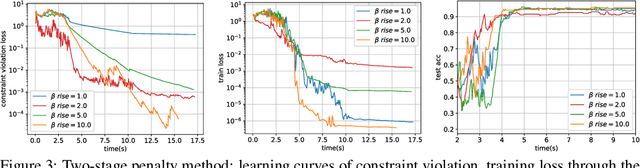
Algorithms for training residual networks (ResNets) typically require forward pass of data, followed by backpropagating of loss gradient to perform parameter updates, which can take many hours or even days for networks with hundreds of layers. Inspired by the penalty and augmented Lagrangian methods, a layer-parallel training algorithm is proposed in this work to overcome the scalability barrier caused by the serial nature of forward-backward propagation in deep residual learning. Moreover, by viewing the supervised classification task as a numerical discretization of the terminal control problem, we bridge the concept of synthetic gradient for decoupling backpropagation with the parareal method for solving differential equations, which not only offers a novel perspective on the design of synthetic loss function but also performs parameter updates with reduced storage overhead. Experiments on a preliminary example demonstrate that the proposed algorithm achieves comparable or even better testing accuracy to the full serial backpropagation approach, while enabling layer-parallelism can provide speedup over the traditional layer-serial training methods.