 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Exogenous States and Rewards
Mar 22, 2023
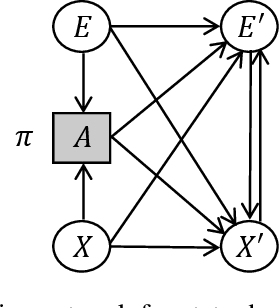
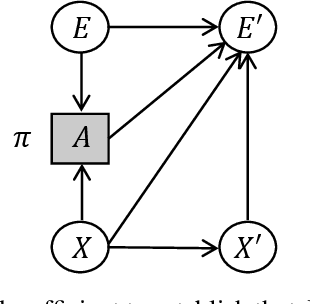
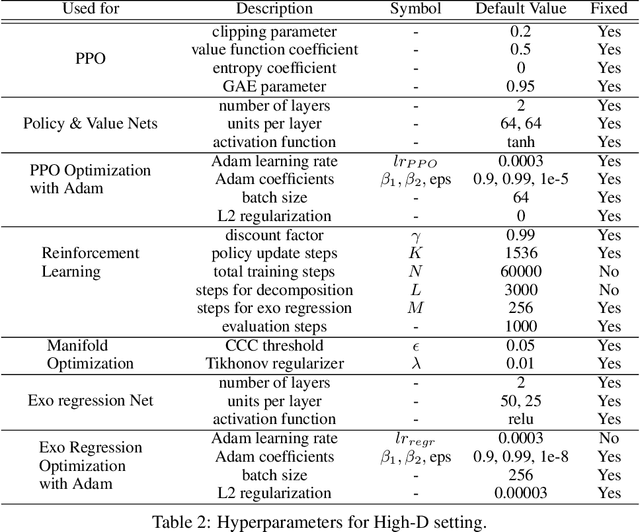
Exogenous state variables and rewards can slow reinforcement learning by injecting uncontrolled variation into the reward signal. This paper formalizes exogenous state variables and rewards and shows that if the reward function decomposes additively into endogenous and exogenous components, the MDP can be decomposed into an exogenous Markov Reward Process (based on the exogenous reward) and an endogenous Markov Decision Process (optimizing the endogenous reward). Any optimal policy for the endogenous MDP is also an optimal policy for the original MDP, but because the endogenous reward typically has reduced variance, the endogenous MDP is easier to solve. We study settings where the decomposition of the state space into exogenous and endogenous state spaces is not given but must be discovered. The paper introduces and proves correctness of algorithms for discovering the exogenous and endogenous subspaces of the state space when they are mixed through linear combination. These algorithms can be applied during reinforcement learning to discover the exogenous space, remove the exogenous reward, and focus reinforcement learning on the endogenous MDP. Experiments on a variety of challenging synthetic MDPs show that these methods, applied online, discover large exogenous state spaces and produce substantial speedups in reinforcement learning.
Multi-objective Neural Architecture Search via Non-stationary Policy Gradient
Jan 31, 2020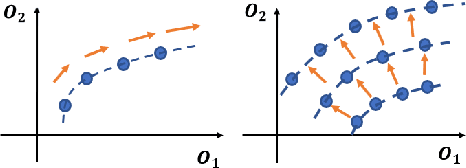
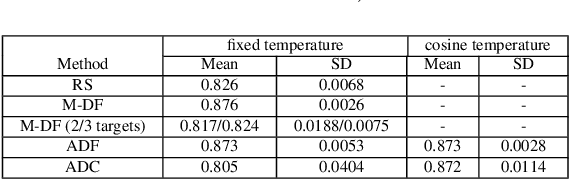
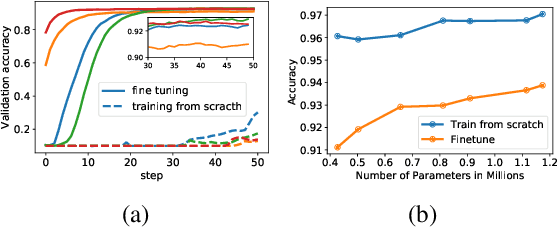
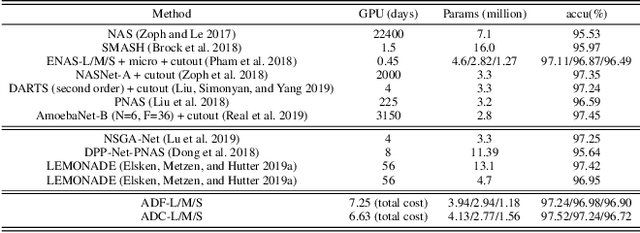
Multi-objective Neural Architecture Search (NAS) aims to discover novel architectures in the presence of multiple conflicting objectives. Despite recent progress, the problem of approximating the full Pareto front accurately and efficiently remains challenging. In this work, we explore the novel reinforcement learning (RL) based paradigm of non-stationary policy gradient (NPG). NPG utilizes a non-stationary reward function, and encourages a continuous adaptation of the policy to capture the entire Pareto front efficiently. We introduce two novel reward functions with elements from the dominant paradigms of scalarization and evolution. To handle non-stationarity, we propose a new exploration scheme using cosine temperature decay with warm restarts. For fast and accurate architecture evaluation, we introduce a novel pre-trained shared model that we continuously fine-tune throughout training. Our extensive experimental study with various datasets shows that our framework can approximate the full Pareto front well at fast speeds. Moreover, our discovered cells can achieve supreme predictive performance compared to other multi-objective NAS methods, and other single-objective NAS methods at similar network sizes. Our work demonstrates the potential of NPG as a simple, efficient, and effective paradigm for multi-objective NAS.
Comparing EM with GD in Mixture Models of Two Components
Jul 19, 2019

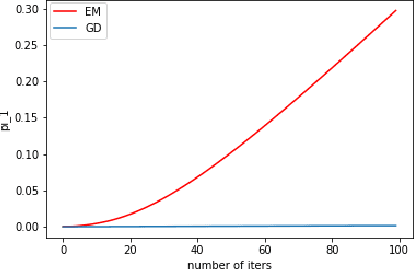
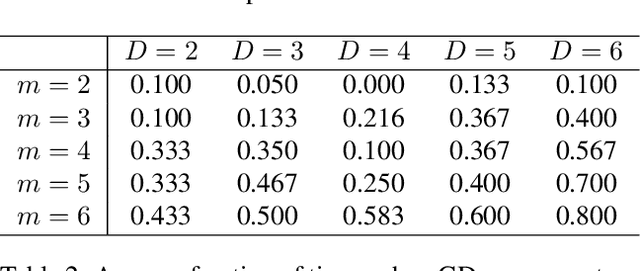
The expectation-maximization (EM) algorithm has been widely used in minimizing the negative log likelihood (also known as cross entropy) of mixture models. However, little is understood about the goodness of the fixed points it converges to. In this paper, we study the regions where one component is missing in two-component mixture models, which we call one-cluster regions. We analyze the propensity of such regions to trap EM and gradient descent (GD) for mixtures of two Gaussians and mixtures of two Bernoullis. In the case of Gaussian mixtures, EM escapes one-cluster regions exponentially fast, while GD escapes them linearly fast. In the case of mixtures of Bernoullis, we find that there exist one-cluster regions that are stable for GD and therefore trap GD, but those regions are unstable for EM, allowing EM to escape. Those regions are local minima that appear universally in experiments and can be arbitrarily bad. This work implies that EM is less likely than GD to converge to certain bad local optima in mixture models.
Discovering and Removing Exogenous State Variables and Rewards for Reinforcement Learning
Jun 05, 2018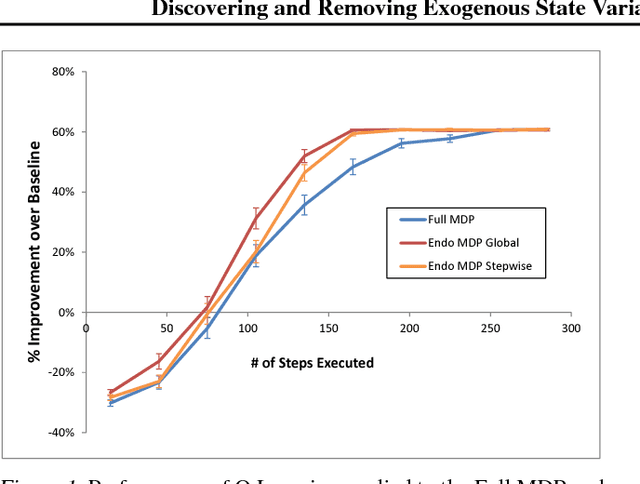



Exogenous state variables and rewards can slow down reinforcement learning by injecting uncontrolled variation into the reward signal. We formalize exogenous state variables and rewards and identify conditions under which an MDP with exogenous state can be decomposed into an exogenous Markov Reward Process involving only the exogenous state+reward and an endogenous Markov Decision Process defined with respect to only the endogenous rewards. We also derive a variance-covariance condition under which Monte Carlo policy evaluation on the endogenous MDP is accelerated compared to using the full MDP. Similar speedups are likely to carry over to all RL algorithms. We develop two algorithms for discovering the exogenous variables and test them on several MDPs. Results show that the algorithms are practical and can significantly speed up reinforcement learning.
Dynamic Sum Product Networks for Tractable Inference on Sequence Data (Extended Version)
Jul 16, 2016

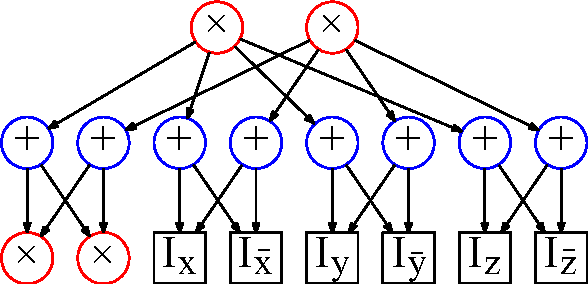
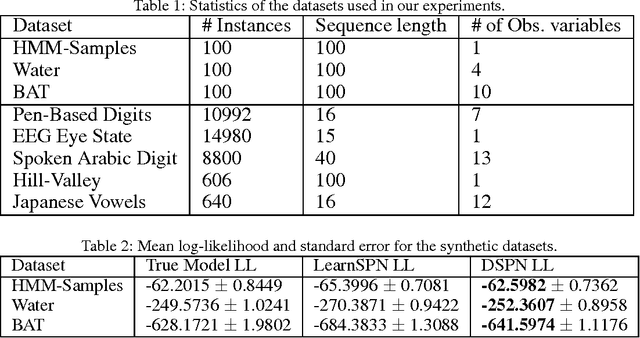
Sum-Product Networks (SPN) have recently emerged as a new class of tractable probabilistic graphical models. Unlike Bayesian networks and Markov networks where inference may be exponential in the size of the network, inference in SPNs is in time linear in the size of the network. Since SPNs represent distributions over a fixed set of variables only, we propose dynamic sum product networks (DSPNs) as a generalization of SPNs for sequence data of varying length. A DSPN consists of a template network that is repeated as many times as needed to model data sequences of any length. We present a local search technique to learn the structure of the template network. In contrast to dynamic Bayesian networks for which inference is generally exponential in the number of variables per time slice, DSPNs inherit the linear inference complexity of SPNs. We demonstrate the advantages of DSPNs over DBNs and other models on several datasets of sequence data.