 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Parallel Training of Residual Networks with Auxiliary-Variable Networks
Paper and Code
Dec 10, 2021
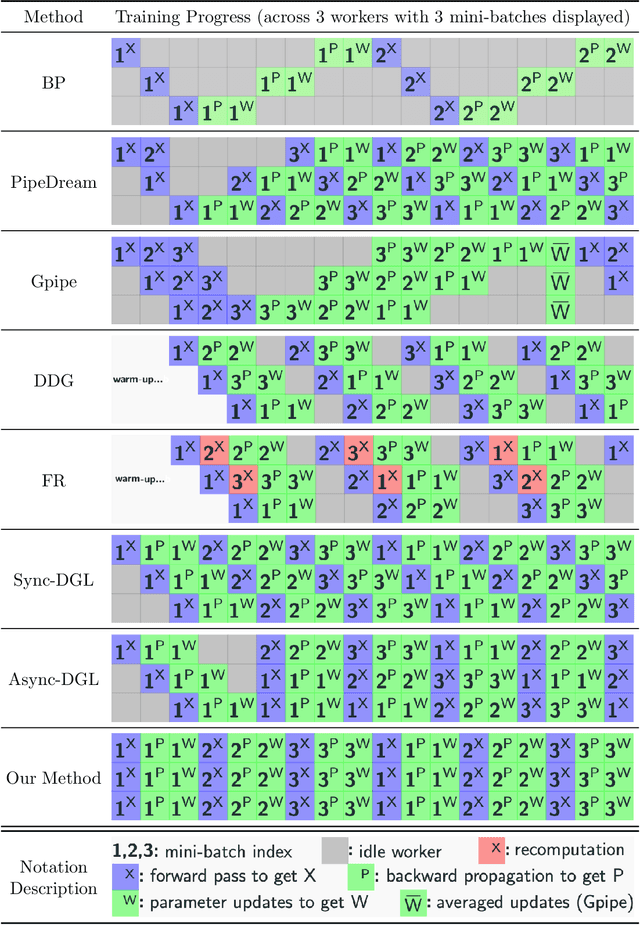

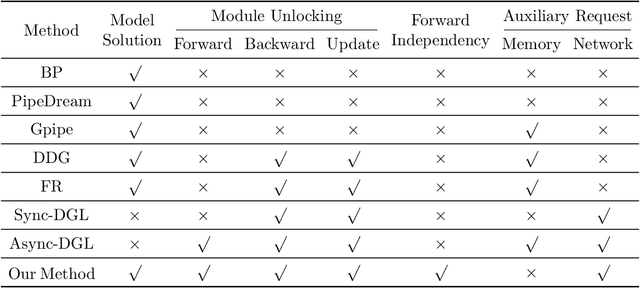
Gradient-based methods for the distributed training of residual networks (ResNets) typically require a forward pass of the input data, followed by back-propagating the error gradient to update model parameters, which becomes time-consuming as the network goes deeper. To break the algorithmic locking and exploit synchronous module parallelism in both the forward and backward modes, auxiliary-variable methods have attracted much interest lately but suffer from significant communication overhead and lack of data augmentation. In this work, a novel joint learning framework for training realistic ResNets across multiple compute devices is established by trading off the storage and recomputation of external auxiliary variables. More specifically, the input data of each independent processor is generated from its low-capacity auxiliary network (AuxNet), which permits the use of data augmentation and realizes forward unlocking. The backward passes are then executed in parallel, each with a local loss function that originates from the penalty or augmented Lagrangian (AL) methods. Finally, the proposed AuxNet is employed to reproduce the updated auxiliary variables through an end-to-end training process. We demonstrate the effectiveness of our methods on ResNets and WideResNets across CIFAR-10, CIFAR-100, and ImageNet datasets, achieving speedup over the traditional layer-serial training method while maintaining comparable testing accuracy.