 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInspecting Model Fairness in Ultrasound Segmentation Tasks
Dec 05, 2023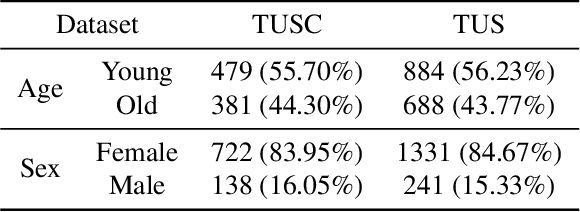
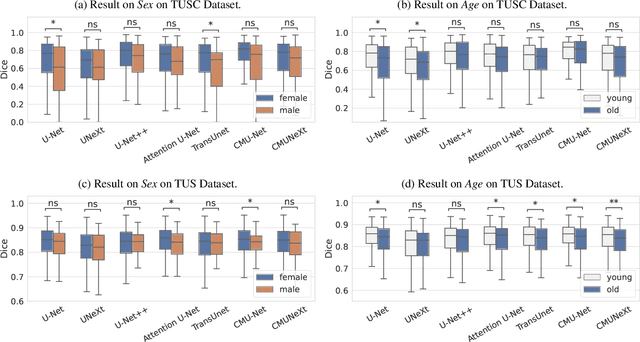
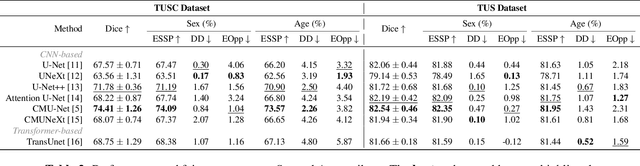
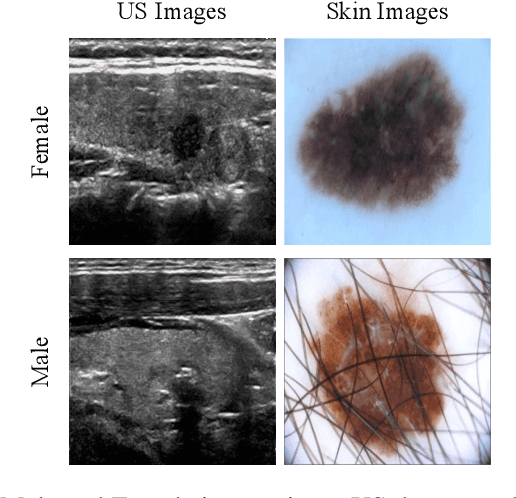
With the rapid expansion of machine learning and deep learning (DL), researchers are increasingly employing learning-based algorithms to alleviate diagnostic challenges across diverse medical tasks and applications. While advancements in diagnostic precision are notable, some researchers have identified a concerning trend: their models exhibit biased performance across subgroups characterized by different sensitive attributes. This bias not only infringes upon the rights of patients but also has the potential to lead to life-altering consequences. In this paper, we inspect a series of DL segmentation models using two ultrasound datasets, aiming to assess the presence of model unfairness in these specific tasks. Our findings reveal that even state-of-the-art DL algorithms demonstrate unfair behavior in ultrasound segmentation tasks. These results serve as a crucial warning, underscoring the necessity for careful model evaluation before their deployment in real-world scenarios. Such assessments are imperative to ensure ethical considerations and mitigate the risk of adverse impacts on patient outcomes.
MobileUtr: Revisiting the relationship between light-weight CNN and Transformer for efficient medical image segmentation
Dec 04, 2023



Due to the scarcity and specific imaging characteristics in medical images, light-weighting Vision Transformers (ViTs) for efficient medical image segmentation is a significant challenge, and current studies have not yet paid attention to this issue. This work revisits the relationship between CNNs and Transformers in lightweight universal networks for medical image segmentation, aiming to integrate the advantages of both worlds at the infrastructure design level. In order to leverage the inductive bias inherent in CNNs, we abstract a Transformer-like lightweight CNNs block (ConvUtr) as the patch embeddings of ViTs, feeding Transformer with denoised, non-redundant and highly condensed semantic information. Moreover, an adaptive Local-Global-Local (LGL) block is introduced to facilitate efficient local-to-global information flow exchange, maximizing Transformer's global context information extraction capabilities. Finally, we build an efficient medical image segmentation model (MobileUtr) based on CNN and Transformer. Extensive experiments on five public medical image datasets with three different modalities demonstrate the superiority of MobileUtr over the state-of-the-art methods, while boasting lighter weights and lower computational cost. Code is available at https://github.com/FengheTan9/MobileUtr.
SRSNetwork: Siamese Reconstruction-Segmentation Networks based on Dynamic-Parameter Convolution
Dec 04, 2023



In this paper, we present a high-performance deep neural network for weak target image segmentation, including medical image segmentation and infrared image segmentation. To this end, this work analyzes the existing dynamic convolutions and proposes dynamic parameter convolution (DPConv). Furthermore, it reevaluates the relationship between reconstruction tasks and segmentation tasks from the perspective of DPConv, leading to the proposal of a dual-network model called the Siamese Reconstruction-Segmentation Network (SRSNet). The proposed model is not only a universal network but also enhances the segmentation performance without altering its structure, leveraging the reconstruction task. Additionally, as the amount of training data for the reconstruction network increases, the performance of the segmentation network also improves synchronously. On seven datasets including five medical datasets and two infrared image datasets, our SRSNet consistently achieves the best segmentation results. The code is released at https://github.com/fidshu/SRSNet.
CMUNeXt: An Efficient Medical Image Segmentation Network based on Large Kernel and Skip Fusion
Aug 03, 2023



The U-shaped architecture has emerged as a crucial paradigm in the design of medical image segmentation networks. However, due to the inherent local limitations of convolution, a fully convolutional segmentation network with U-shaped architecture struggles to effectively extract global context information, which is vital for the precise localization of lesions. While hybrid architectures combining CNNs and Transformers can address these issues, their application in real medical scenarios is limited due to the computational resource constraints imposed by the environment and edge devices. In addition, the convolutional inductive bias in lightweight networks adeptly fits the scarce medical data, which is lacking in the Transformer based network. In order to extract global context information while taking advantage of the inductive bias, we propose CMUNeXt, an efficient fully convolutional lightweight medical image segmentation network, which enables fast and accurate auxiliary diagnosis in real scene scenarios. CMUNeXt leverages large kernel and inverted bottleneck design to thoroughly mix distant spatial and location information, efficiently extracting global context information. We also introduce the Skip-Fusion block, designed to enable smooth skip-connections and ensure ample feature fusion. Experimental results on multiple medical image datasets demonstrate that CMUNeXt outperforms existing heavyweight and lightweight medical image segmentation networks in terms of segmentation performance, while offering a faster inference speed, lighter weights, and a reduced computational cost. The code is available at https://github.com/FengheTan9/CMUNeXt.
Thinking Twice: Clinical-Inspired Thyroid Ultrasound Lesion Detection Based on Feature Feedback
May 24, 2023



Accurate detection of thyroid lesions is a critical aspect of computer-aided diagnosis. However, most existing detection methods perform only one feature extraction process and then fuse multi-scale features, which can be affected by noise and blurred features in ultrasound images. In this study, we propose a novel detection network based on a feature feedback mechanism inspired by clinical diagnosis. The mechanism involves first roughly observing the overall picture and then focusing on the details of interest. It comprises two parts: a feedback feature selection module and a feature feedback pyramid. The feedback feature selection module efficiently selects the features extracted in the first phase in both space and channel dimensions to generate high semantic prior knowledge, which is similar to coarse observation. The feature feedback pyramid then uses this high semantic prior knowledge to enhance feature extraction in the second phase and adaptively fuses the two features, similar to fine observation. Additionally, since radiologists often focus on the shape and size of lesions for diagnosis, we propose an adaptive detection head strategy to aggregate multi-scale features. Our proposed method achieves an AP of 70.3% and AP50 of 99.0% on the thyroid ultrasound dataset and meets the real-time requirement. The code is available at https://github.com/HIT-wanglingtao/Thinking-Twice.
Multi-Level Global Context Cross Consistency Model for Semi-Supervised Ultrasound Image Segmentation with Diffusion Model
May 17, 2023Medical image segmentation is a critical step in computer-aided diagnosis, and convolutional neural networks are popular segmentation networks nowadays. However, the inherent local operation characteristics make it difficult to focus on the global contextual information of lesions with different positions, shapes, and sizes. Semi-supervised learning can be used to learn from both labeled and unlabeled samples, alleviating the burden of manual labeling. However, obtaining a large number of unlabeled images in medical scenarios remains challenging. To address these issues, we propose a Multi-level Global Context Cross-consistency (MGCC) framework that uses images generated by a Latent Diffusion Model (LDM) as unlabeled images for semi-supervised learning. The framework involves of two stages. In the first stage, a LDM is used to generate synthetic medical images, which reduces the workload of data annotation and addresses privacy concerns associated with collecting medical data. In the second stage, varying levels of global context noise perturbation are added to the input of the auxiliary decoder, and output consistency is maintained between decoders to improve the representation ability. Experiments conducted on open-source breast ultrasound and private thyroid ultrasound datasets demonstrate the effectiveness of our framework in bridging the probability distribution and the semantic representation of the medical image. Our approach enables the effective transfer of probability distribution knowledge to the segmentation network, resulting in improved segmentation accuracy. The code is available at https://github.com/FengheTan9/Multi-Level-Global-Context-Cross-Consistency.
CMU-Net: A Strong ConvMixer-based Medical Ultrasound Image Segmentation Network
Nov 02, 2022



U-Net and its extensions have achieved great success in medical image segmentation. However, due to the inherent local characteristics of ordinary convolution operations, U-Net encoder cannot effectively extract global context information. In addition, simple skip connections cannot capture salient features. In this work, we propose a fully convolutional segmentation network (CMU-Net) which incorporates hybrid convolutions and multi-scale attention gate. The ConvMixer module extracts global context information by mixing features at distant spatial locations. Moreover, the multi-scale attention gate emphasizes valuable features and achieves efficient skip connections. We evaluate the proposed method using both breast ultrasound datasets and a thyroid ultrasound image dataset; and CMU-Net achieves average Intersection over Union (IoU) values of 73.27% and 84.75%, and F1 scores of 84.81% and 91.71%. The code is available at https://github.com/FengheTan9/CMU-Net.
EMT-NET: Efficient multitask network for computer-aided diagnosis of breast cancer
Jan 13, 2022
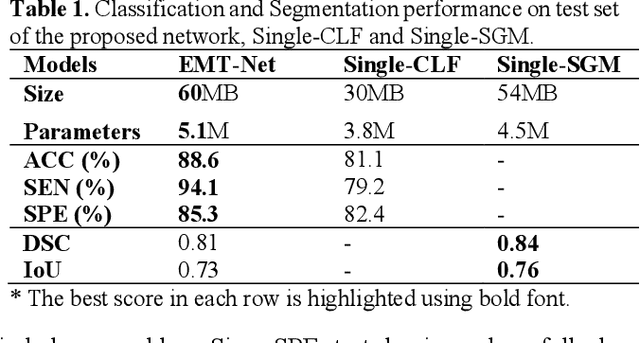
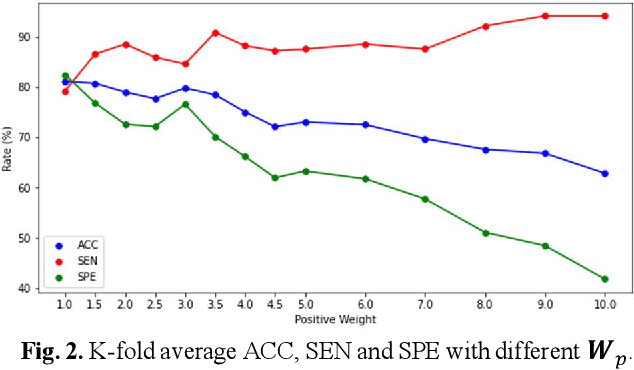

Deep learning-based computer-aided diagnosis has achieved unprecedented performance in breast cancer detection. However, most approaches are computationally intensive, which impedes their broader dissemination in real-world applications. In this work, we propose an efficient and light-weighted multitask learning architecture to classify and segment breast tumors simultaneously. We incorporate a segmentation task into a tumor classification network, which makes the backbone network learn representations focused on tumor regions. Moreover, we propose a new numerically stable loss function that easily controls the balance between the sensitivity and specificity of cancer detection. The proposed approach is evaluated using a breast ultrasound dataset with 1,511 images. The accuracy, sensitivity, and specificity of tumor classification is 88.6%, 94.1%, and 85.3%, respectively. We validate the model using a virtual mobile device, and the average inference time is 0.35 seconds per image.
Breast Anatomy Enriched Tumor Saliency Estimation
Oct 23, 2019

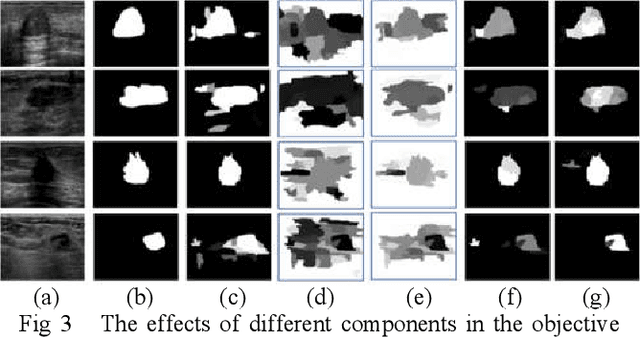
Breast cancer investigation is of great significance, and developing tumor detection methodologies is a critical need. However, it is a challenging task for breast ultrasound due to the complicated breast structure and poor quality of the images. In this paper, we propose a novel tumor saliency estimation model guided by enriched breast anatomy knowledge to localize the tumor. Firstly, the breast anatomy layers are generated by a deep neural network. Then we refine the layers by integrating a non-semantic breast anatomy model to solve the problems of incomplete mammary layers. Meanwhile, a new background map generation method weighted by the semantic probability and spatial distance is proposed to improve the performance. The experiment demonstrates that the proposed method with the new background map outperforms four state-of-the-art TSE models with increasing 10% of F_meansure on the BUS public dataset.
Tumor Saliency Estimation for Breast Ultrasound Images via Breast Anatomy Modeling
Jun 18, 2019
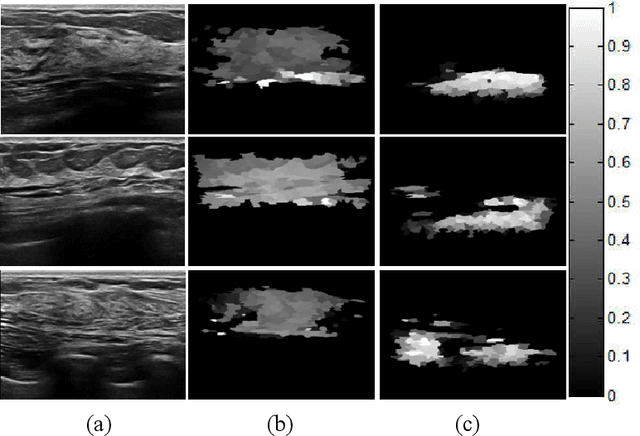

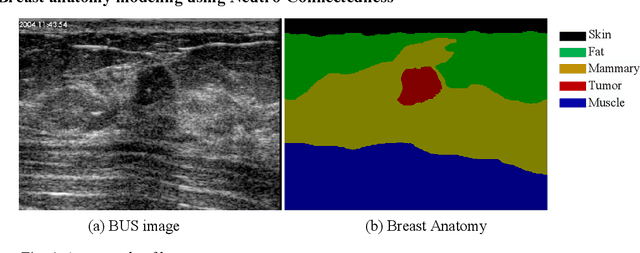
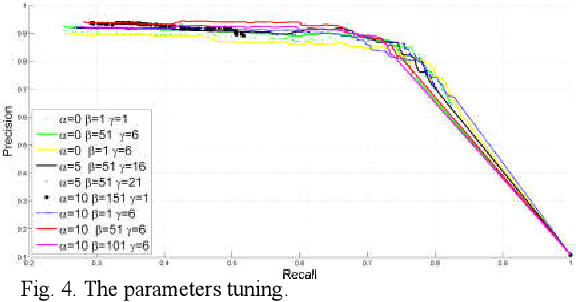
Tumor saliency estimation aims to localize tumors by modeling the visual stimuli in medical images. However, it is a challenging task for breast ultrasound due to the complicated anatomic structure of the breast and poor image quality; and existing saliency estimation approaches only model generic visual stimuli, e.g., local and global contrast, location, and feature correlation, and achieve poor performance for tumor saliency estimation. In this paper, we propose a novel optimization model to estimate tumor saliency by utilizing breast anatomy. First, we model breast anatomy and decompose breast ultrasound image into layers using Neutro-Connectedness; then utilize the layers to generate the foreground and background maps; and finally propose a novel objective function to estimate the tumor saliency by integrating the foreground map, background map, adaptive center bias, and region-based correlation cues. The extensive experiments demonstrate that the proposed approach obtains more accurate foreground and background maps with the assistance of the breast anatomy; especially, for the images having large or small tumors; meanwhile, the new objective function can handle the images without tumors. The newly proposed method achieves state-of-the-art performance when compared to eight tumor saliency estimation approaches using two breast ultrasound datasets.