 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Deep Learning and Iterative Algorithms for Joint Channel Estimation and Signal Detection
Mar 07, 2023



Joint channel estimation and signal detection (JCESD) is crucial in wireless communication systems, but traditional algorithms perform poorly in low signal-to-noise ratio (SNR) scenarios. Deep learning (DL) methods have been investigated, but concerns regarding computational expense and lack of validation in low-SNR settings remain. Hence, the development of a robust and low-complexity model that can deliver excellent performance across a wide range of SNRs is highly desirable. In this paper, we aim to establish a benchmark where traditional algorithms and DL methods are validated on different channel models, Doppler, and SNR settings. In particular, we propose a new DL model where the backbone network is formed by unrolling the iterative algorithm, and the hyperparameters are estimated by hypernetworks. Additionally, we adapt a lightweight DenseNet to the task of JCESD for comparison. We evaluate different methods in three aspects: generalization in terms of bit error rate (BER), robustness, and complexity. Our results indicate that DL approaches outperform traditional algorithms in the challenging low-SNR setting, while the iterative algorithm performs better in highSNR settings. Furthermore, the iterative algorithm is more robust in the presence of carrier frequency offset, whereas DL methods excel when signals are corrupted by asymmetric Gaussian noise.
Active CT Reconstruction with a Learned Sampling Policy
Nov 03, 2022



Computed tomography (CT) is a widely-used imaging technology that assists clinical decision-making with high-quality human body representations. To reduce the radiation dose posed by CT, sparse-view and limited-angle CT are developed with preserved image quality. However, these methods are still stuck with a fixed or uniform sampling strategy, which inhibits the possibility of acquiring a better image with an even reduced dose. In this paper, we explore this possibility via learning an active sampling policy that optimizes the sampling positions for patient-specific, high-quality reconstruction. To this end, we design an \textit{intelligent agent} for active recommendation of sampling positions based on on-the-fly reconstruction with obtained sinograms in a progressive fashion. With such a design, we achieve better performances on the NIH-AAPM dataset over popular uniform sampling, especially when the number of views is small. Finally, such a design also enables RoI-aware reconstruction with improved reconstruction quality within regions of interest (RoI's) that are clinically important. Experiments on the VerSe dataset demonstrate this ability of our sampling policy, which is difficult to achieve based on uniform sampling.
InDuDoNet+: A Model-Driven Interpretable Dual Domain Network for Metal Artifact Reduction in CT Images
Dec 23, 2021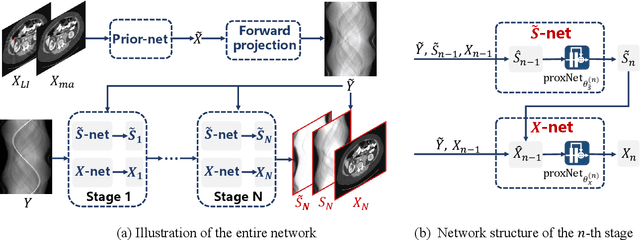
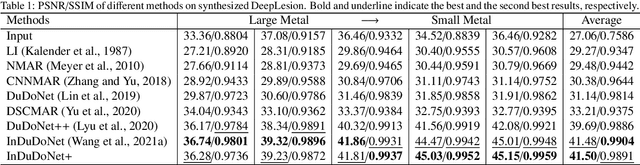
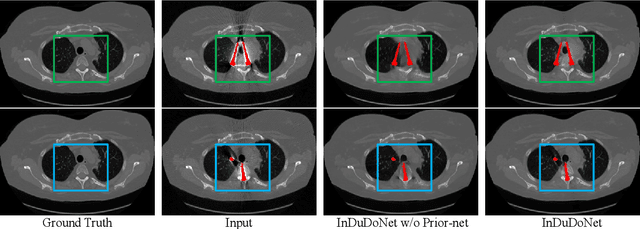

During the computed tomography (CT) imaging process, metallic implants within patients always cause harmful artifacts, which adversely degrade the visual quality of reconstructed CT images and negatively affect the subsequent clinical diagnosis. For the metal artifact reduction (MAR) task, current deep learning based methods have achieved promising performance. However, most of them share two main common limitations: 1) the CT physical imaging geometry constraint is not comprehensively incorporated into deep network structures; 2) the entire framework has weak interpretability for the specific MAR task; hence, the role of every network module is difficult to be evaluated. To alleviate these issues, in the paper, we construct a novel interpretable dual domain network, termed InDuDoNet+, into which CT imaging process is finely embedded. Concretely, we derive a joint spatial and Radon domain reconstruction model and propose an optimization algorithm with only simple operators for solving it. By unfolding the iterative steps involved in the proposed algorithm into the corresponding network modules, we easily build the InDuDoNet+ with clear interpretability. Furthermore, we analyze the CT values among different tissues, and merge the prior observations into a prior network for our InDuDoNet+, which significantly improve its generalization performance. Comprehensive experiments on synthesized data and clinical data substantiate the superiority of the proposed methods as well as the superior generalization performance beyond the current state-of-the-art (SOTA) MAR methods. Code is available at \url{https://github.com/hongwang01/InDuDoNet_plus}.
DuDoTrans: Dual-Domain Transformer Provides More Attention for Sinogram Restoration in Sparse-View CT Reconstruction
Nov 25, 2021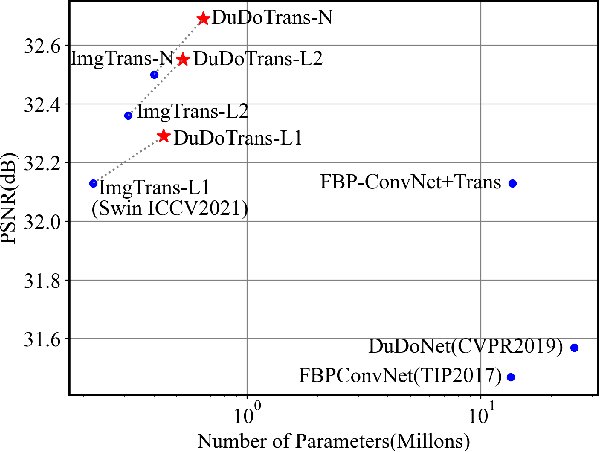



While Computed Tomography (CT) reconstruction from X-ray sinograms is necessary for clinical diagnosis, iodine radiation in the imaging process induces irreversible injury, thereby driving researchers to study sparse-view CT reconstruction, that is, recovering a high-quality CT image from a sparse set of sinogram views. Iterative models are proposed to alleviate the appeared artifacts in sparse-view CT images, but the computation cost is too expensive. Then deep-learning-based methods have gained prevalence due to the excellent performances and lower computation. However, these methods ignore the mismatch between the CNN's \textbf{local} feature extraction capability and the sinogram's \textbf{global} characteristics. To overcome the problem, we propose \textbf{Du}al-\textbf{Do}main \textbf{Trans}former (\textbf{DuDoTrans}) to simultaneously restore informative sinograms via the long-range dependency modeling capability of Transformer and reconstruct CT image with both the enhanced and raw sinograms. With such a novel design, reconstruction performance on the NIH-AAPM dataset and COVID-19 dataset experimentally confirms the effectiveness and generalizability of DuDoTrans with fewer involved parameters. Extensive experiments also demonstrate its robustness with different noise-level scenarios for sparse-view CT reconstruction. The code and models are publicly available at https://github.com/DuDoTrans/CODE
InDuDoNet: An Interpretable Dual Domain Network for CT Metal Artifact Reduction
Sep 11, 2021

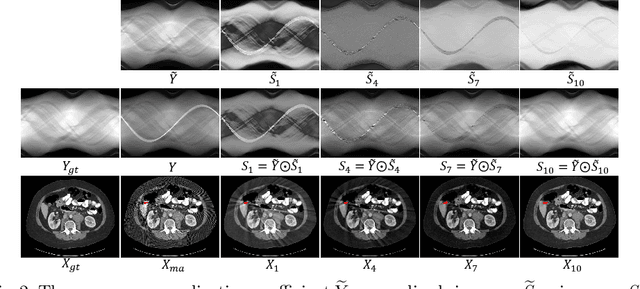
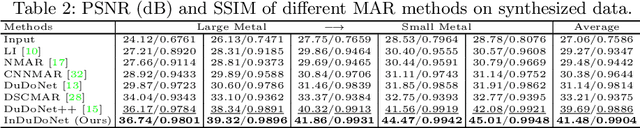
For the task of metal artifact reduction (MAR), although deep learning (DL)-based methods have achieved promising performances, most of them suffer from two problems: 1) the CT imaging geometry constraint is not fully embedded into the network during training, leaving room for further performance improvement; 2) the model interpretability is lack of sufficient consideration. Against these issues, we propose a novel interpretable dual domain network, termed as InDuDoNet, which combines the advantages of model-driven and data-driven methodologies. Specifically, we build a joint spatial and Radon domain reconstruction model and utilize the proximal gradient technique to design an iterative algorithm for solving it. The optimization algorithm only consists of simple computational operators, which facilitate us to correspondingly unfold iterative steps into network modules and thus improve the interpretablility of the framework. Extensive experiments on synthesized and clinical data show the superiority of our InDuDoNet. Code is available in \url{https://github.com/hongwang01/InDuDoNet}.%method on the tasks of MAR and downstream multi-class pelvic fracture segmentation.
Generalizable Limited-Angle CT Reconstruction via Sinogram Extrapolation
Mar 15, 2021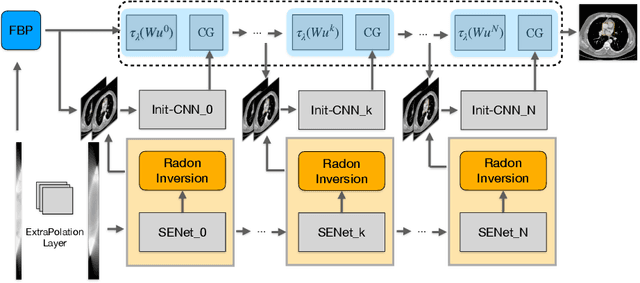


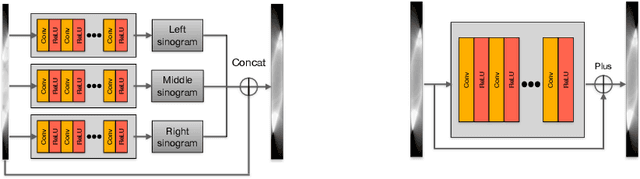
Computed tomography (CT) reconstruction from X-ray projections acquired within a limited angle range is challenging, especially when the angle range is extremely small. Both analytical and iterative models need more projections for effective modeling. Deep learning methods have gained prevalence due to their excellent reconstruction performances, but such success is mainly limited within the same dataset and does not generalize across datasets with different distributions. Hereby we propose ExtraPolationNetwork for limited-angle CT reconstruction via the introduction of a sinogram extrapolation module, which is theoretically justified. The module complements extra sinogram information and boots model generalizability. Extensive experimental results show that our reconstruction model achieves state-of-the-art performance on NIH-AAPM dataset, similar to existing approaches. More importantly, we show that using such a sinogram extrapolation module significantly improves the generalization capability of the model on unseen datasets (e.g., COVID-19 and LIDC datasets) when compared to existing approaches.
MetaInv-Net: Meta Inversion Network for Sparse View CT Image Reconstruction
May 30, 2020

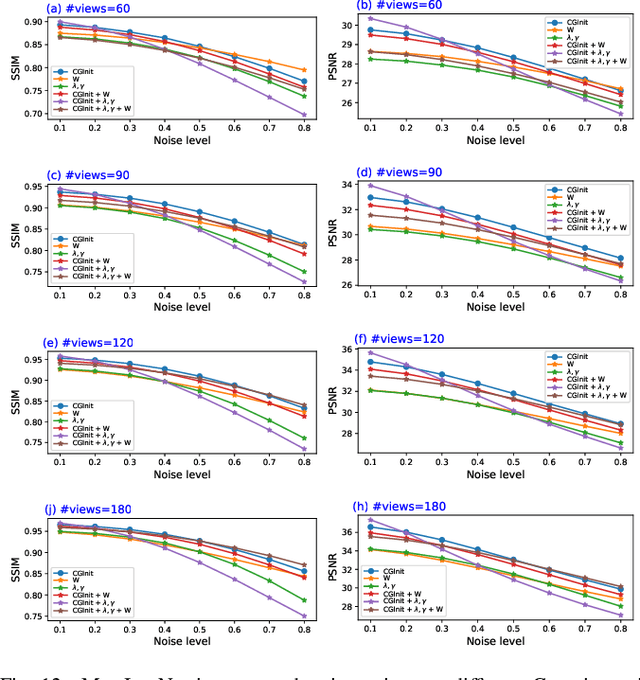

X-ray Computed Tomography (CT) is widely used in clinical applications such as diagnosis and image-guided interventions. In this paper, we propose a new deep learning based model for CT image reconstruction with the backbone network architecture built by unrolling an iterative algorithm. However, unlike the existing strategy to include as many data-adaptive components in the unrolled dynamics model as possible, we find that it is enough to only learn the parts where traditional designs mostly rely on intuitions and experience. More specifically, we propose to learn an initializer for the conjugate gradient (CG) algorithm that involved in one of the subproblems of the backbone model. Other components, such as image priors and hyperparameters, are kept as the original design. This makes the proposed model very light-weighted. Since a hypernetwork is introduced to inference on the initialization of the CG module, it makes the proposed model a certain meta-learning model. Therefore, we shall call the proposed model the meta-inversion network (MetaInv-Net). The proposed MetaInv-Net has much less trainable parameters and superior image reconstruction performance than some state-of-the-art deep models in CT imaging. In simulated and real data experiments, MetaInv-Net performs very well and can be generalized beyond the training setting, i.e., to other scanning settings, noise levels, and noise types.
A Review on Deep Learning in Medical Image Reconstruction
Jun 23, 2019



Medical imaging is crucial in modern clinics to guide the diagnosis and treatment of diseases. Medical image reconstruction is one of the most fundamental and important components of medical imaging, whose major objective is to acquire high-quality medical images for clinical usage at the minimal cost and risk to the patients. Mathematical models in medical image reconstruction or, more generally, image restoration in computer vision, have been playing a prominent role. Earlier mathematical models are mostly designed by human knowledge or hypothesis on the image to be reconstructed, and we shall call these models handcrafted models. Later, handcrafted plus data-driven modeling started to emerge which still mostly relies on human designs, while part of the model is learned from the observed data. More recently, as more data and computation resources are made available, deep learning based models (or deep models) pushed the data-driven modeling to the extreme where the models are mostly based on learning with minimal human designs. Both handcrafted and data-driven modeling have their own advantages and disadvantages. One of the major research trends in medical imaging is to combine handcrafted modeling with deep modeling so that we can enjoy benefits from both approaches. The major part of this article is to provide a conceptual review of some recent works on deep modeling from the unrolling dynamics viewpoint. This viewpoint stimulates new designs of neural network architectures with inspirations from optimization algorithms and numerical differential equations. Given the popularity of deep modeling, there are still vast remaining challenges in the field, as well as opportunities which we shall discuss at the end of this article.
JSR-Net: A Deep Network for Joint Spatial-Radon Domain CT Reconstruction from incomplete data
Dec 03, 2018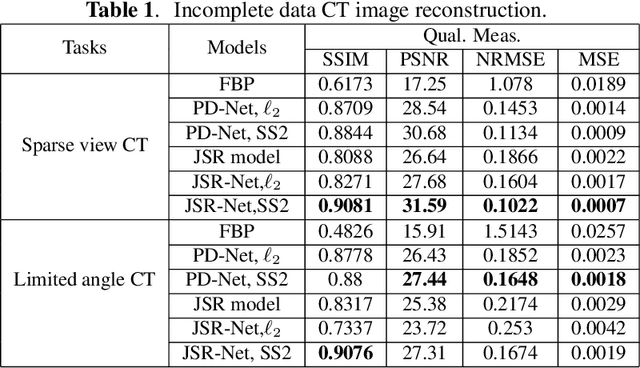
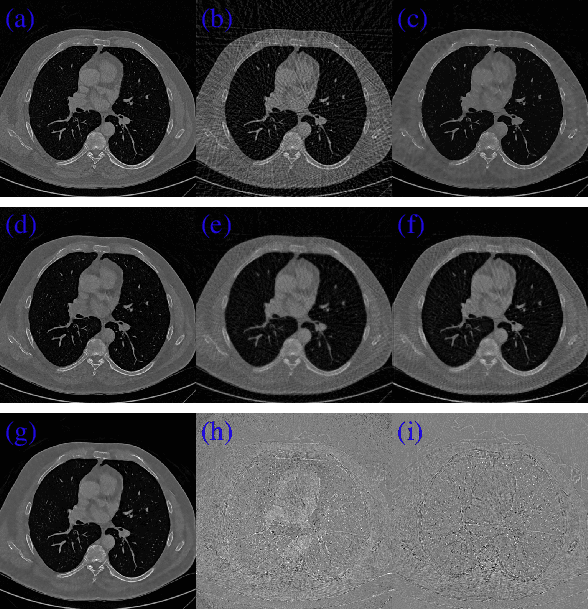
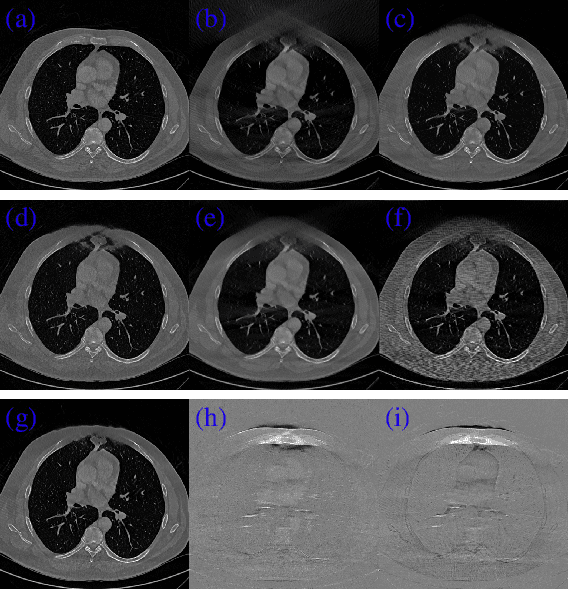
CT image reconstruction from incomplete data, such as sparse views and limited angle reconstruction, is an important and challenging problem in medical imaging. This work proposes a new deep convolutional neural network (CNN), called JSR-Net, that jointly reconstructs CT images and their associated Radon domain projections. JSR-Net combines the traditional model based approach with deep architecture design of deep learning. A hybrid loss function is adopted to improve the performance of the JSR-Net making it more effective in protecting important image structures. Numerical experiments demonstrate that JSR-Net outperforms some latest model based reconstruction methods, as well as a recently proposed deep model.