 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniVLR: Unifying Text and Vision in Visual Latent Reasoning for Multimodal LLMs
May 12, 2026Multimodal large language models are increasingly expected to perform thinking with images, yet existing visual latent reasoning methods still rely on explicit textual chain-of-thought interleaved with visual latent tokens. This interleaved design limits efficiency and keeps reasoning fragmented across separate text and vision channels. We propose UniVLR, a unified visual latent reasoning framework that treats textual reasoning and auxiliary visual evidence as a shared visual workspace. Instead of preserving text CoT as an independent inference-time path, UniVLR renders reasoning traces together with auxiliary images and learns to compress this unified representation into compact visual latent tokens. At inference time, the model reasons only through visual latents and directly decodes the final answer, avoiding both external tool calls and verbose text reasoning. Experiments on real-world perception and visual reasoning tasks show that UniVLR outperforms prior visual latent reasoning methods while using substantially fewer generated reasoning tokens, suggesting a more unified and efficient paradigm for visual thinking in MLLMs.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
Topology-aware MLP for Skeleton-based Action Recognition
Sep 04, 2023
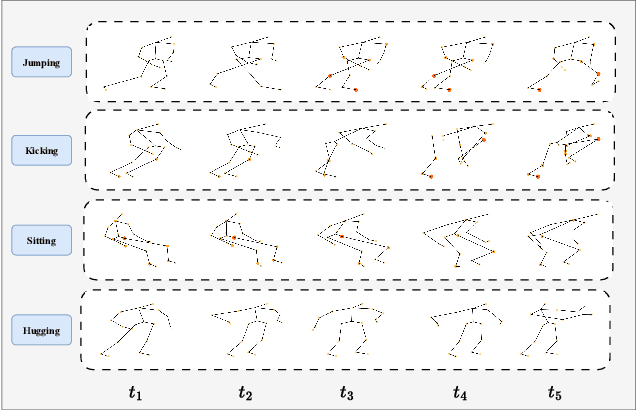
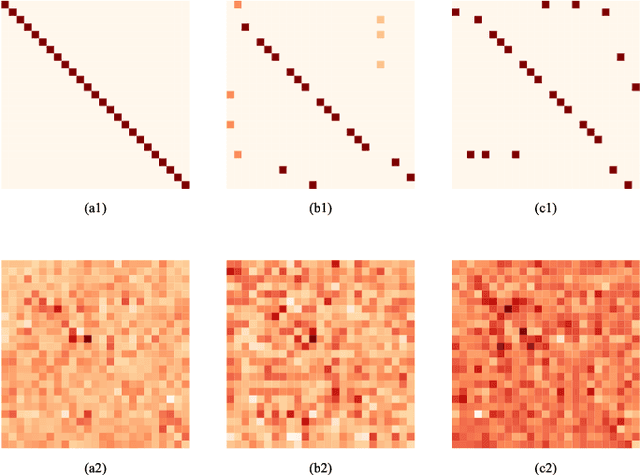
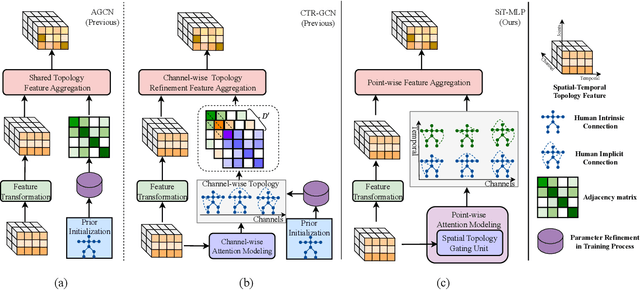
Graph convolution networks (GCNs) have achieved remarkable performance in skeleton-based action recognition. However, existing previous GCN-based methods have relied excessively on elaborate human body priors and constructed complex feature aggregation mechanisms, which limits the generalizability of networks. To solve these problems, we propose a novel Spatial Topology Gating Unit (STGU), which is an MLP-based variant without extra priors, to capture the co-occurrence topology features that encode the spatial dependency across all joints. In STGU, to model the sample-specific and completely independent point-wise topology attention, a new gate-based feature interaction mechanism is introduced to activate the features point-to-point by the attention map generated from the input. Based on the STGU, in this work, we propose the first topology-aware MLP-based model, Ta-MLP, for skeleton-based action recognition. In comparison with existing previous methods on three large-scale datasets, Ta-MLP achieves competitive performance. In addition, Ta-MLP reduces the parameters by up to 62.5% with favorable results. Compared with previous state-of-the-art (SOAT) approaches, Ta-MLP pushes the frontier of real-time action recognition. The code will be available at https://github.com/BUPTSJZhang/Ta-MLP.
An Improved Baseline Framework for Pose Estimation Challenge at ECCV 2022 Visual Perception for Navigation in Human Environments Workshop
Mar 13, 2023



This technical report describes our first-place solution to the pose estimation challenge at ECCV 2022 Visual Perception for Navigation in Human Environments Workshop. In this challenge, we aim to estimate human poses from in-the-wild stitched panoramic images. Our method is built based on Faster R-CNN for human detection, and HRNet for human pose estimation. We describe technical details for the JRDB-Pose dataset, together with some experimental results. In the competition, we achieved 0.303 $\text{OSPA}_{\text{IOU}}$ and 64.047\% $\text{AP}_{\text{0.5}}$ on the test set of JRDB-Pose.
Learning Dynamic Correlations in Spatiotemporal Graphs for Motion Prediction
Apr 14, 2022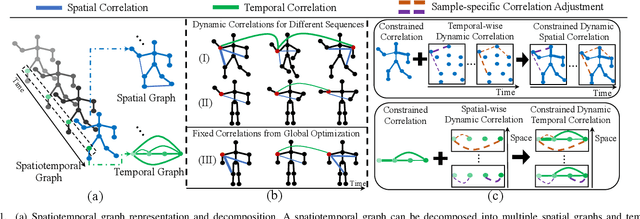
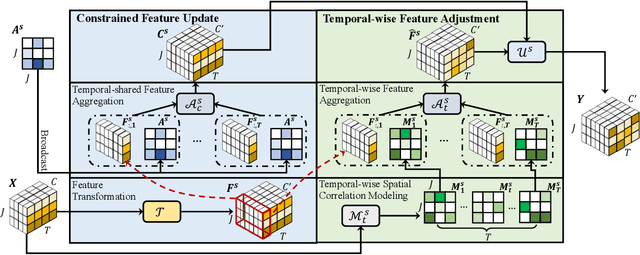
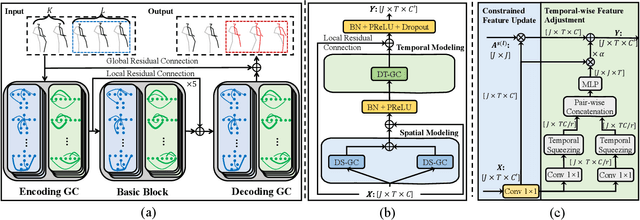

Human motion prediction is a challenge task due to the dynamic spatiotemporal graph correlations in different motion sequences. How to efficiently represent spatiotemporal graph correlations and model dynamic correlation variances between different motion sequences is a challenge for spatiotemporal graph representation in motion prediction. In this work, we present Dynamic SpatioTemporal Graph Convolution (DSTD-GC). The proposed DSTD-GC decomposes dynamic spatiotemporal graph modeling into a combination of Dynamic Spatial Graph Convolution (DS-GC) and Dynamic Temporal Graph Convolution (DT-GC). As human motions are subject to common constraints like body connections and present dynamic motion patterns from different samples, we present Constrained Dynamic Correlation Modeling strategy to represent the spatial/temporal graph as a shared spatial/temporal correlation and a function to extract temporal-specific /spatial-specific adjustments for each sample. The modeling strategy represents the spatiotemporal graph with 28.6\% parameters of the state-of-the-art static decomposition representation while also explicitly models sample-specific spatiotemporal correlation variances. Moreover, we also mathematically reformulating spatiotemporal graph convolutions and their decomposed variants into a unified form and find that DSTD-GC relaxes strict constraints of other graph convolutions, leading to a stronger representation capability. Combining DSTD-GC with prior knowledge, we propose a powerful spatiotemporal graph convolution network called DSTD-GCN which outperforms state-of-the-art methods on the Human3.6M and CMU Mocap datasets in prediction accuracy with fewest parameters.
U-DuDoNet: Unpaired dual-domain network for CT metal artifact reduction
Mar 08, 2021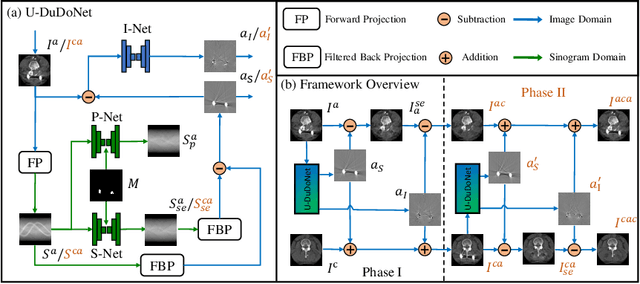
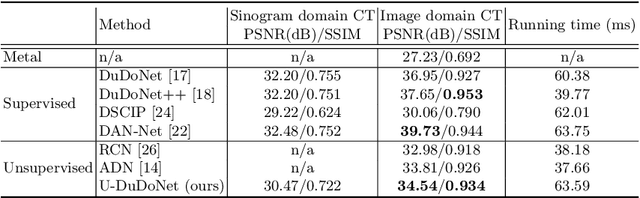
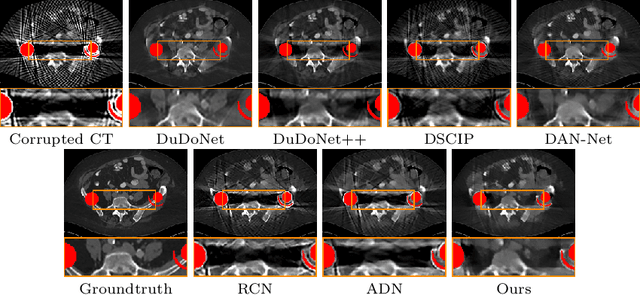

Recently, both supervised and unsupervised deep learning methods have been widely applied on the CT metal artifact reduction (MAR) task. Supervised methods such as Dual Domain Network (Du-DoNet) work well on simulation data; however, their performance on clinical data is limited due to domain gap. Unsupervised methods are more generalized, but do not eliminate artifacts completely through the sole processing on the image domain. To combine the advantages of both MAR methods, we propose an unpaired dual-domain network (U-DuDoNet) trained using unpaired data. Unlike the artifact disentanglement network (ADN) that utilizes multiple encoders and decoders for disentangling content from artifact, our U-DuDoNet directly models the artifact generation process through additions in both sinogram and image domains, which is theoretically justified by an additive property associated with metal artifact. Our design includes a self-learned sinogram prior net, which provides guidance for restoring the information in the sinogram domain, and cyclic constraints for artifact reduction and addition on unpaired data. Extensive experiments on simulation data and clinical images demonstrate that our novel framework outperforms the state-of-the-art unpaired approaches.