 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dynamic Correlations in Spatiotemporal Graphs for Motion Prediction
Apr 14, 2022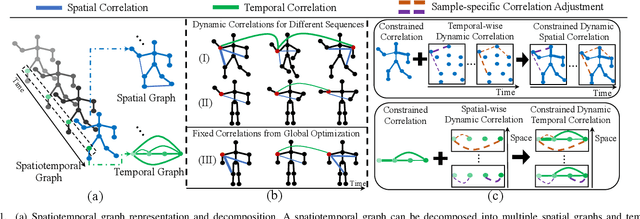
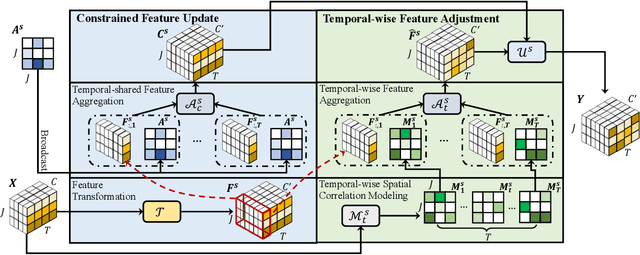
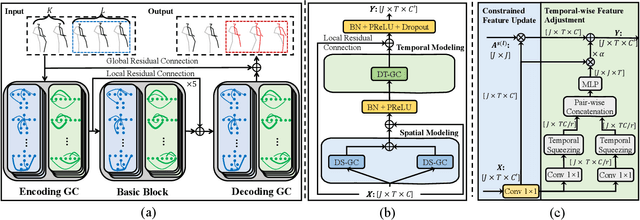

Human motion prediction is a challenge task due to the dynamic spatiotemporal graph correlations in different motion sequences. How to efficiently represent spatiotemporal graph correlations and model dynamic correlation variances between different motion sequences is a challenge for spatiotemporal graph representation in motion prediction. In this work, we present Dynamic SpatioTemporal Graph Convolution (DSTD-GC). The proposed DSTD-GC decomposes dynamic spatiotemporal graph modeling into a combination of Dynamic Spatial Graph Convolution (DS-GC) and Dynamic Temporal Graph Convolution (DT-GC). As human motions are subject to common constraints like body connections and present dynamic motion patterns from different samples, we present Constrained Dynamic Correlation Modeling strategy to represent the spatial/temporal graph as a shared spatial/temporal correlation and a function to extract temporal-specific /spatial-specific adjustments for each sample. The modeling strategy represents the spatiotemporal graph with 28.6\% parameters of the state-of-the-art static decomposition representation while also explicitly models sample-specific spatiotemporal correlation variances. Moreover, we also mathematically reformulating spatiotemporal graph convolutions and their decomposed variants into a unified form and find that DSTD-GC relaxes strict constraints of other graph convolutions, leading to a stronger representation capability. Combining DSTD-GC with prior knowledge, we propose a powerful spatiotemporal graph convolution network called DSTD-GCN which outperforms state-of-the-art methods on the Human3.6M and CMU Mocap datasets in prediction accuracy with fewest parameters.
DWnet: Deep-Wide Network for 3D Action Recognition
Aug 29, 2019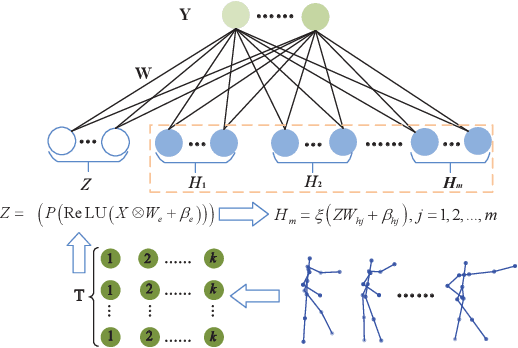
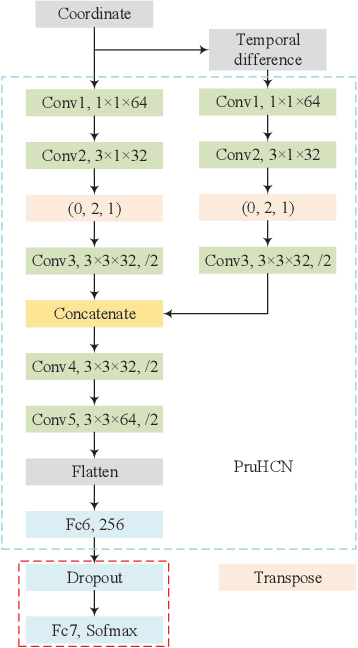
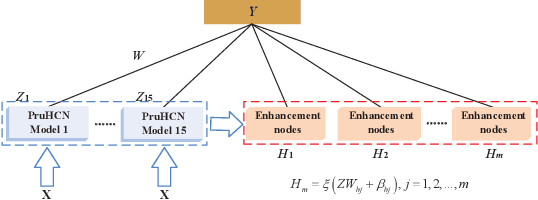
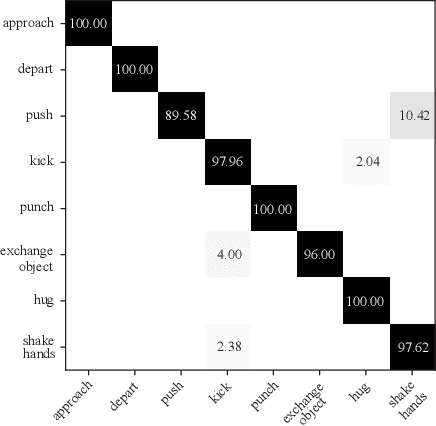
We propose in this paper a deep-wide network (DWnet) which combines the deep structure with the broad learning system (BLS) to recognize actions. Compared with the deep structure, the novel model saves lots of testing time and almost achieves real-time testing. Furthermore, the DWnet can capture better features than broad learning system can. In terms of methodology, we use pruned hierarchical co-occurrence network (PruHCN) to learn local and global spatial-temporal features. To obtain sufficient global information, BLS is used to expand features extracted by PruHCN. Experiments on two common skeletal datasets demonstrate the advantage of the proposed model on testing time and the effectiveness of the novel model to recognize the action.