 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARZero: Cross-Attention Alignment for Radiology Zero-Shot Classification
Paper and Code
Feb 27, 2024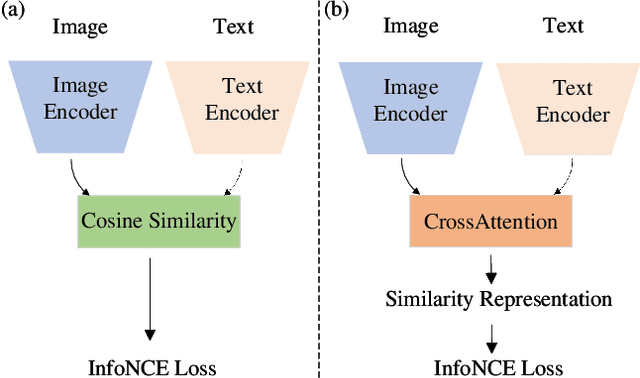

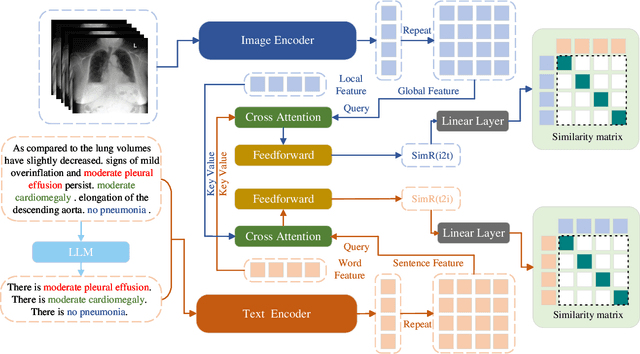
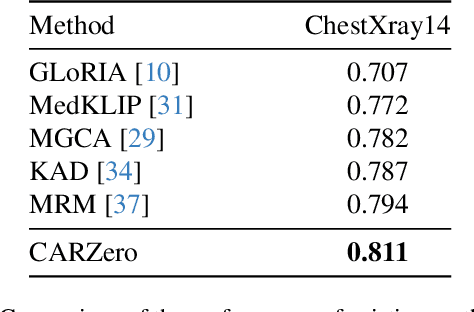
The advancement of Zero-Shot Learning in the medical domain has been driven forward by using pre-trained models on large-scale image-text pairs, focusing on image-text alignment. However, existing methods primarily rely on cosine similarity for alignment, which may not fully capture the complex relationship between medical images and reports. To address this gap, we introduce a novel approach called Cross-Attention Alignment for Radiology Zero-Shot Classification (CARZero). Our approach innovatively leverages cross-attention mechanisms to process image and report features, creating a Similarity Representation that more accurately reflects the intricate relationships in medical semantics. This representation is then linearly projected to form an image-text similarity matrix for cross-modality alignment. Additionally, recognizing the pivotal role of prompt selection in zero-shot learning, CARZero incorporates a Large Language Model-based prompt alignment strategy. This strategy standardizes diverse diagnostic expressions into a unified format for both training and inference phases, overcoming the challenges of manual prompt design. Our approach is simple yet effective, demonstrating state-of-the-art performance in zero-shot classification on five official chest radiograph diagnostic test sets, including remarkable results on datasets with long-tail distributions of rare diseases. This achievement is attributed to our new image-text alignment strategy, which effectively addresses the complex relationship between medical images and reports.