 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentVLA: Efficient Vision-Language Models for Autonomous Driving via Latent Action Prediction
Jan 09, 2026End-to-end autonomous driving models trained on largescale datasets perform well in common scenarios but struggle with rare, long-tail situations due to limited scenario diversity. Recent Vision-Language-Action (VLA) models leverage broad knowledge from pre-trained visionlanguage models to address this limitation, yet face critical challenges: (1) numerical imprecision in trajectory prediction due to discrete tokenization, (2) heavy reliance on language annotations that introduce linguistic bias and annotation burden, and (3) computational inefficiency from multi-step chain-of-thought reasoning hinders real-time deployment. We propose LatentVLA, a novel framework that employs self-supervised latent action prediction to train VLA models without language annotations, eliminating linguistic bias while learning rich driving representations from unlabeled trajectory data. Through knowledge distillation, LatentVLA transfers the generalization capabilities of VLA models to efficient vision-based networks, achieving both robust performance and real-time efficiency. LatentVLA establishes a new state-of-the-art on the NAVSIM benchmark with a PDMS score of 92.4 and demonstrates strong zeroshot generalization on the nuScenes benchmark.
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
Mar 09, 2025We explore how scalable robot data can address real-world challenges for generalized robotic manipulation. Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution. It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition. Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume. Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios. GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%. By open-sourcing the dataset, tools, and models, we aim to democratize access to large-scale, high-quality robot data, advancing the pursuit of scalable and general-purpose intelligence.
DriveLM: Driving with Graph Visual Question Answering
Dec 21, 2023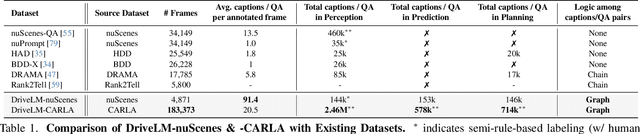
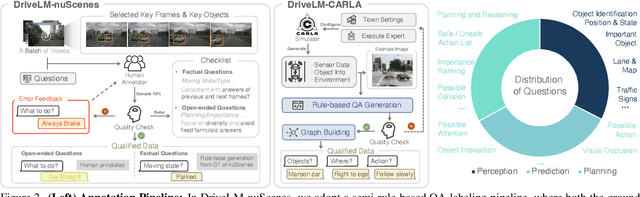
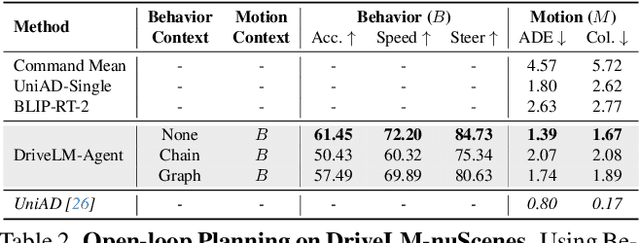
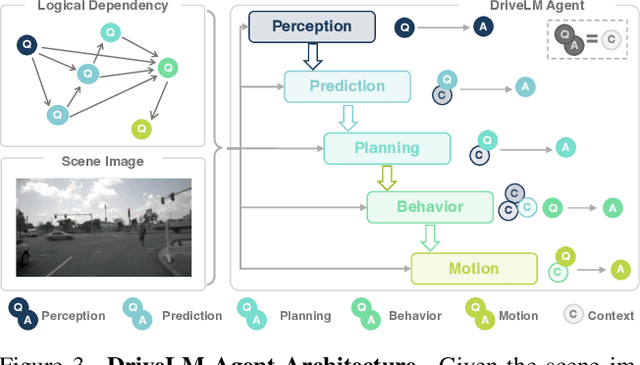
We study how vision-language models (VLMs) trained on web-scale data can be integrated into end-to-end driving systems to boost generalization and enable interactivity with human users. While recent approaches adapt VLMs to driving via single-round visual question answering (VQA), human drivers reason about decisions in multiple steps. Starting from the localization of key objects, humans estimate object interactions before taking actions. The key insight is that with our proposed task, Graph VQA, where we model graph-structured reasoning through perception, prediction and planning question-answer pairs, we obtain a suitable proxy task to mimic the human reasoning process. We instantiate datasets (DriveLM-Data) built upon nuScenes and CARLA, and propose a VLM-based baseline approach (DriveLM-Agent) for jointly performing Graph VQA and end-to-end driving. The experiments demonstrate that Graph VQA provides a simple, principled framework for reasoning about a driving scene, and DriveLM-Data provides a challenging benchmark for this task. Our DriveLM-Agent baseline performs end-to-end autonomous driving competitively in comparison to state-of-the-art driving-specific architectures. Notably, its benefits are pronounced when it is evaluated zero-shot on unseen objects or sensor configurations. We hope this work can be the starting point to shed new light on how to apply VLMs for autonomous driving. To facilitate future research, all code, data, and models are available to the public.