 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreoPep: A Universal Deep Learning Framework for Target-Specific Peptide Design and Optimization
May 05, 2025Target-specific peptides, such as conotoxins, exhibit exceptional binding affinity and selectivity toward ion channels and receptors. However, their therapeutic potential remains underutilized due to the limited diversity of natural variants and the labor-intensive nature of traditional optimization strategies. Here, we present CreoPep, a deep learning-based conditional generative framework that integrates masked language modeling with a progressive masking scheme to design high-affinity peptide mutants while uncovering novel structural motifs. CreoPep employs an integrative augmentation pipeline, combining FoldX-based energy screening with temperature-controlled multinomial sampling, to generate structurally and functionally diverse peptides that retain key pharmacological properties. We validate this approach by designing conotoxin inhibitors targeting the $\alpha$7 nicotinic acetylcholine receptor, achieving submicromolar potency in electrophysiological assays. Structural analysis reveals that CreoPep-generated variants engage in both conserved and novel binding modes, including disulfide-deficient forms, thus expanding beyond conventional design paradigms. Overall, CreoPep offers a robust and generalizable platform that bridges computational peptide design with experimental validation, accelerating the discovery of next-generation peptide therapeutics.
Saga: Capturing Multi-granularity Semantics from Massive Unlabelled IMU Data for User Perception
Apr 16, 2025Inertial measurement units (IMUs), have been prevalently used in a wide range of mobile perception applications such as activity recognition and user authentication, where a large amount of labelled data are normally required to train a satisfactory model. However, it is difficult to label micro-activities in massive IMU data due to the hardness of understanding raw IMU data and the lack of ground truth. In this paper, we propose a novel fine-grained user perception approach, called Saga, which only needs a small amount of labelled IMU data to achieve stunning user perception accuracy. The core idea of Saga is to first pre-train a backbone feature extraction model, utilizing the rich semantic information of different levels embedded in the massive unlabelled IMU data. Meanwhile, for a specific downstream user perception application, Bayesian Optimization is employed to determine the optimal weights for pre-training tasks involving different semantic levels. We implement Saga on five typical mobile phones and evaluate Saga on three typical tasks on three IMU datasets. Results show that when only using about 100 training samples per class, Saga can achieve over 90% accuracy of the full-fledged model trained on over ten thousands training samples with no additional system overhead.
Prism: Mining Task-aware Domains in Non-i.i.d. IMU Data for Flexible User Perception
Jan 03, 2025



A wide range of user perception applications leverage inertial measurement unit (IMU) data for online prediction. However, restricted by the non-i.i.d. nature of IMU data collected from mobile devices, most systems work well only in a controlled setting (e.g., for a specific user in particular postures), limiting application scenarios. To achieve uncontrolled online prediction on mobile devices, referred to as the flexible user perception (FUP) problem, is attractive but hard. In this paper, we propose a novel scheme, called Prism, which can obtain high FUP accuracy on mobile devices. The core of Prism is to discover task-aware domains embedded in IMU dataset, and to train a domain-aware model on each identified domain. To this end, we design an expectation-maximization (EM) algorithm to estimate latent domains with respect to the specific downstream perception task. Finally, the best-fit model can be automatically selected for use by comparing the test sample and all identified domains in the feature space. We implement Prism on various mobile devices and conduct extensive experiments. Results demonstrate that Prism can achieve the best FUP performance with a low latency.
Extend Your Own Correspondences: Unsupervised Distant Point Cloud Registration by Progressive Distance Extension
Mar 06, 2024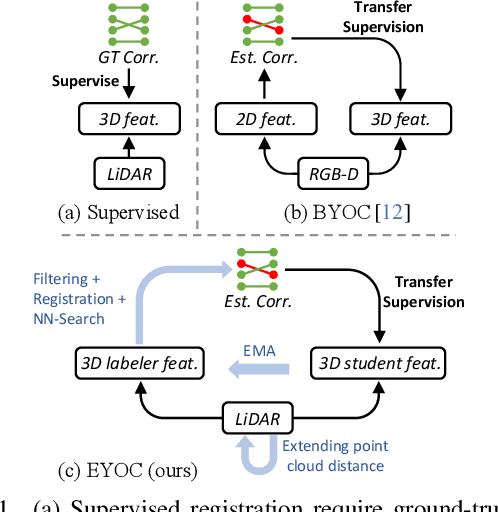
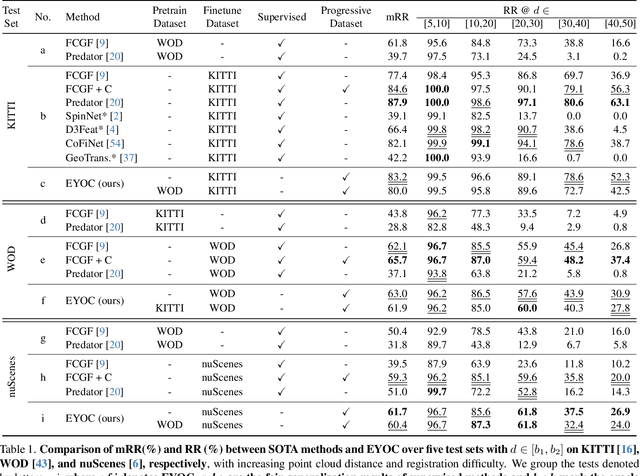
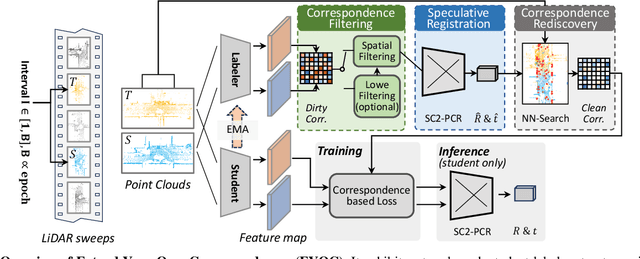

Registration of point clouds collected from a pair of distant vehicles provides a comprehensive and accurate 3D view of the driving scenario, which is vital for driving safety related applications, yet existing literature suffers from the expensive pose label acquisition and the deficiency to generalize to new data distributions. In this paper, we propose EYOC, an unsupervised distant point cloud registration method that adapts to new point cloud distributions on the fly, requiring no global pose labels. The core idea of EYOC is to train a feature extractor in a progressive fashion, where in each round, the feature extractor, trained with near point cloud pairs, can label slightly farther point cloud pairs, enabling self-supervision on such far point cloud pairs. This process continues until the derived extractor can be used to register distant point clouds. Particularly, to enable high-fidelity correspondence label generation, we devise an effective spatial filtering scheme to select the most representative correspondences to register a point cloud pair, and then utilize the aligned point clouds to discover more correct correspondences. Experiments show that EYOC can achieve comparable performance with state-of-the-art supervised methods at a lower training cost. Moreover, it outwits supervised methods regarding generalization performance on new data distributions.
Integrating Chemical Language and Molecular Graph in Multimodal Fused Deep Learning for Drug Property Prediction
Dec 29, 2023



Accurately predicting molecular properties is a challenging but essential task in drug discovery. Recently, many mono-modal deep learning methods have been successfully applied to molecular property prediction. However, the inherent limitation of mono-modal learning arises from relying solely on one modality of molecular representation, which restricts a comprehensive understanding of drug molecules and hampers their resilience against data noise. To overcome the limitations, we construct multimodal deep learning models to cover different molecular representations. We convert drug molecules into three molecular representations, SMILES-encoded vectors, ECFP fingerprints, and molecular graphs. To process the modal information, Transformer-Encoder, bi-directional gated recurrent units (BiGRU), and graph convolutional network (GCN) are utilized for feature learning respectively, which can enhance the model capability to acquire complementary and naturally occurring bioinformatics information. We evaluated our triple-modal model on six molecule datasets. Different from bi-modal learning models, we adopt five fusion methods to capture the specific features and leverage the contribution of each modal information better. Compared with mono-modal models, our multimodal fused deep learning (MMFDL) models outperform single models in accuracy, reliability, and resistance capability against noise. Moreover, we demonstrate its generalization ability in the prediction of binding constants for protein-ligand complex molecules in the refined set of PDBbind. The advantage of the multimodal model lies in its ability to process diverse sources of data using proper models and suitable fusion methods, which would enhance the noise resistance of the model while obtaining data diversity.
Density-invariant Features for Distant Point Cloud Registration
Aug 08, 2023

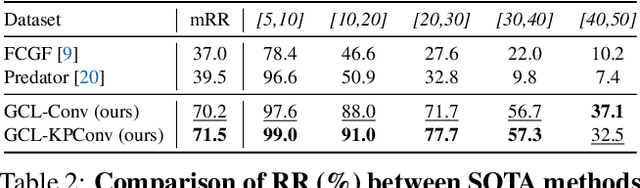
Registration of distant outdoor LiDAR point clouds is crucial to extending the 3D vision of collaborative autonomous vehicles, and yet is challenging due to small overlapping area and a huge disparity between observed point densities. In this paper, we propose Group-wise Contrastive Learning (GCL) scheme to extract density-invariant geometric features to register distant outdoor LiDAR point clouds. We mark through theoretical analysis and experiments that, contrastive positives should be independent and identically distributed (i.i.d.), in order to train densityinvariant feature extractors. We propose upon the conclusion a simple yet effective training scheme to force the feature of multiple point clouds in the same spatial location (referred to as positive groups) to be similar, which naturally avoids the sampling bias introduced by a pair of point clouds to conform with the i.i.d. principle. The resulting fully-convolutional feature extractor is more powerful and density-invariant than state-of-the-art methods, improving the registration recall of distant scenarios on KITTI and nuScenes benchmarks by 40.9% and 26.9%, respectively. Code is available at https://github.com/liuQuan98/GCL.
APR: Online Distant Point Cloud Registration Through Aggregated Point Cloud Reconstruction
May 08, 2023

For many driving safety applications, it is of great importance to accurately register LiDAR point clouds generated on distant moving vehicles. However, such point clouds have extremely different point density and sensor perspective on the same object, making registration on such point clouds very hard. In this paper, we propose a novel feature extraction framework, called APR, for online distant point cloud registration. Specifically, APR leverages an autoencoder design, where the autoencoder reconstructs a denser aggregated point cloud with several frames instead of the original single input point cloud. Our design forces the encoder to extract features with rich local geometry information based on one single input point cloud. Such features are then used for online distant point cloud registration. We conduct extensive experiments against state-of-the-art (SOTA) feature extractors on KITTI and nuScenes datasets. Results show that APR outperforms all other extractors by a large margin, increasing average registration recall of SOTA extractors by 7.1% on LoKITTI and 4.6% on LoNuScenes. Code is available at https://github.com/liuQuan98/APR.
MonoATT: Online Monocular 3D Object Detection with Adaptive Token Transformer
Mar 23, 2023
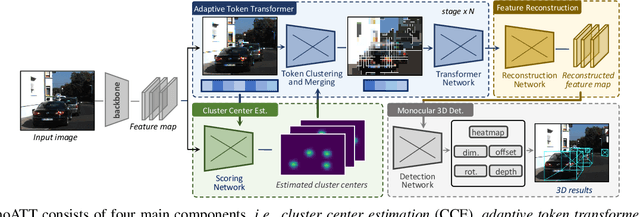
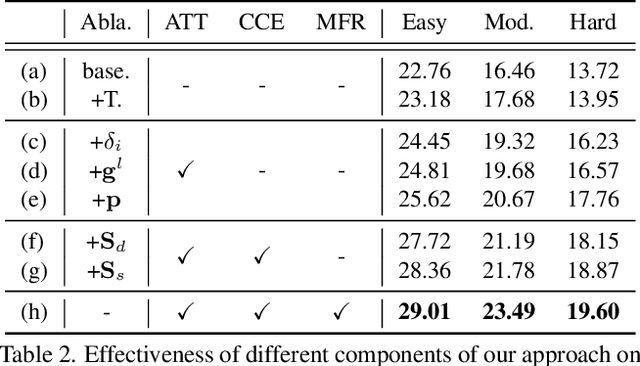
Mobile monocular 3D object detection (Mono3D) (e.g., on a vehicle, a drone, or a robot) is an important yet challenging task. Existing transformer-based offline Mono3D models adopt grid-based vision tokens, which is suboptimal when using coarse tokens due to the limited available computational power. In this paper, we propose an online Mono3D framework, called MonoATT, which leverages a novel vision transformer with heterogeneous tokens of varying shapes and sizes to facilitate mobile Mono3D. The core idea of MonoATT is to adaptively assign finer tokens to areas of more significance before utilizing a transformer to enhance Mono3D. To this end, we first use prior knowledge to design a scoring network for selecting the most important areas of the image, and then propose a token clustering and merging network with an attention mechanism to gradually merge tokens around the selected areas in multiple stages. Finally, a pixel-level feature map is reconstructed from heterogeneous tokens before employing a SOTA Mono3D detector as the underlying detection core. Experiment results on the real-world KITTI dataset demonstrate that MonoATT can effectively improve the Mono3D accuracy for both near and far objects and guarantee low latency. MonoATT yields the best performance compared with the state-of-the-art methods by a large margin and is ranked number one on the KITTI 3D benchmark.
MoGDE: Boosting Mobile Monocular 3D Object Detection with Ground Depth Estimation
Mar 23, 2023Monocular 3D object detection (Mono3D) in mobile settings (e.g., on a vehicle, a drone, or a robot) is an important yet challenging task. Due to the near-far disparity phenomenon of monocular vision and the ever-changing camera pose, it is hard to acquire high detection accuracy, especially for far objects. Inspired by the insight that the depth of an object can be well determined according to the depth of the ground where it stands, in this paper, we propose a novel Mono3D framework, called MoGDE, which constantly estimates the corresponding ground depth of an image and then utilizes the estimated ground depth information to guide Mono3D. To this end, we utilize a pose detection network to estimate the pose of the camera and then construct a feature map portraying pixel-level ground depth according to the 3D-to-2D perspective geometry. Moreover, to improve Mono3D with the estimated ground depth, we design an RGB-D feature fusion network based on the transformer structure, where the long-range self-attention mechanism is utilized to effectively identify ground-contacting points and pin the corresponding ground depth to the image feature map. We conduct extensive experiments on the real-world KITTI dataset. The results demonstrate that MoGDE can effectively improve the Mono3D accuracy and robustness for both near and far objects. MoGDE yields the best performance compared with the state-of-the-art methods by a large margin and is ranked number one on the KITTI 3D benchmark.
DePS: An improved deep learning model for de novo peptide sequencing
Mar 16, 2022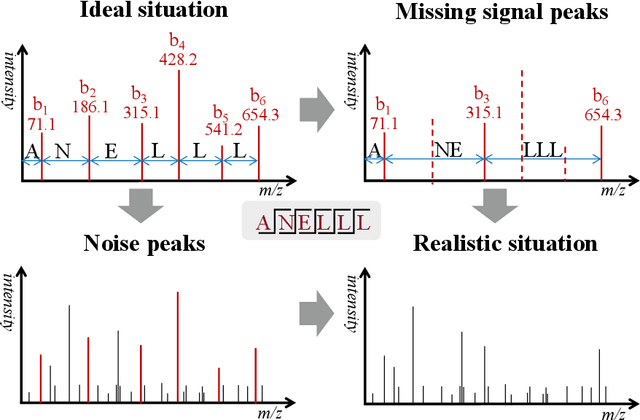
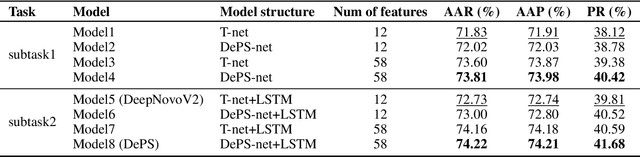
De novo peptide sequencing from mass spectrometry data is an important method for protein identification. Recently, various deep learning approaches were applied for de novo peptide sequencing and DeepNovoV2 is one of the represetative models. In this study, we proposed an enhanced model, DePS, which can improve the accuracy of de novo peptide sequencing even with missing signal peaks or large number of noisy peaks in tandem mass spectrometry data. It is showed that, for the same test set of DeepNovoV2, the DePS model achieved excellent results of 74.22%, 74.21% and 41.68% for amino acid recall, amino acid precision and peptide recall respectively. Furthermore, the results suggested that DePS outperforms DeepNovoV2 on the cross species dataset.