 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSectioning of Biomedical Abstracts: A Sequence of Sequence Classification Task
Jan 18, 2022Rapid growth of the biomedical literature has led to many advances in the biomedical text mining field. Among the vast amount of information, biomedical article abstracts are the easily accessible sources. However, the number of the structured abstracts, describing the rhetorical sections with one of Background, Objective, Method, Result and Conclusion categories is still not considerable. Exploration of valuable information in the biomedical abstracts can be expedited with the improvements in the sequential sentence classification task. Deep learning based models has great performance/potential in achieving significant results in this task. However, they can often be overly complex and overfit to specific data. In this project, we study a state-of-the-art deep learning model, which we called SSN-4 model here. We investigate different components of the SSN-4 model to study the trade-off between the performance and complexity. We explore how well this model generalizes to a new data set beyond Randomized Controlled Trials (RCT) dataset. We address the question that whether word embeddings can be adjusted to the task to improve the performance. Furthermore, we develop a second model that addresses the confusion pairs in the first model. Results show that SSN-4 model does not appear to generalize well beyond RCT dataset.
CU-UD: text-mining drug and chemical-protein interactions with ensembles of BERT-based models
Nov 11, 2021
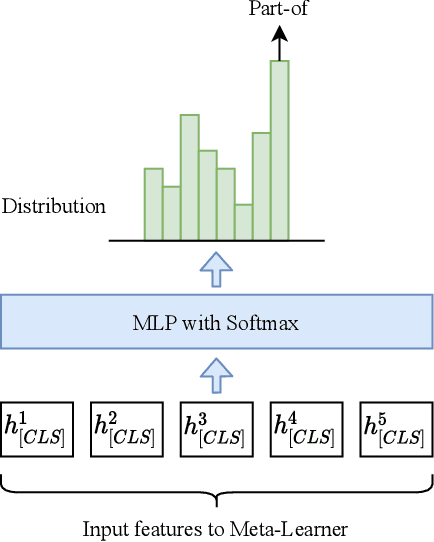
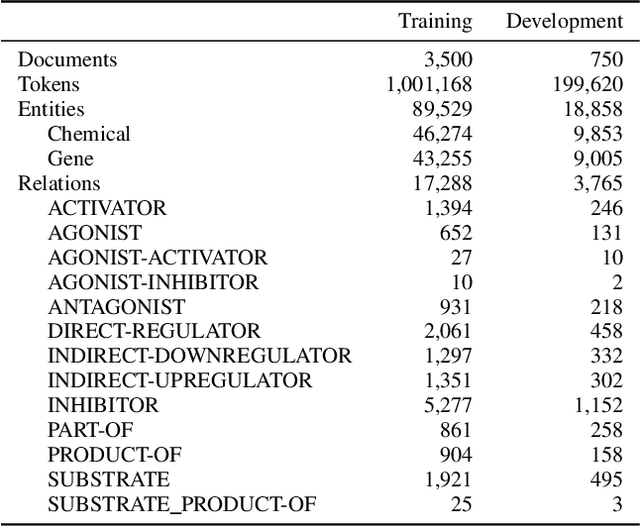
Identifying the relations between chemicals and proteins is an important text mining task. BioCreative VII track 1 DrugProt task aims to promote the development and evaluation of systems that can automatically detect relations between chemical compounds/drugs and genes/proteins in PubMed abstracts. In this paper, we describe our submission, which is an ensemble system, including multiple BERT-based language models. We combine the outputs of individual models using majority voting and multilayer perceptron. Our system obtained 0.7708 in precision and 0.7770 in recall, for an F1 score of 0.7739, demonstrating the effectiveness of using ensembles of BERT-based language models for automatically detecting relations between chemicals and proteins. Our code is available at https://github.com/bionlplab/drugprot_bcvii.
Improving BERT Model Using Contrastive Learning for Biomedical Relation Extraction
Apr 28, 2021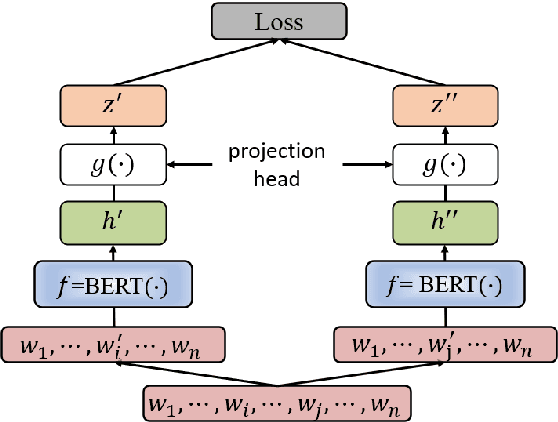

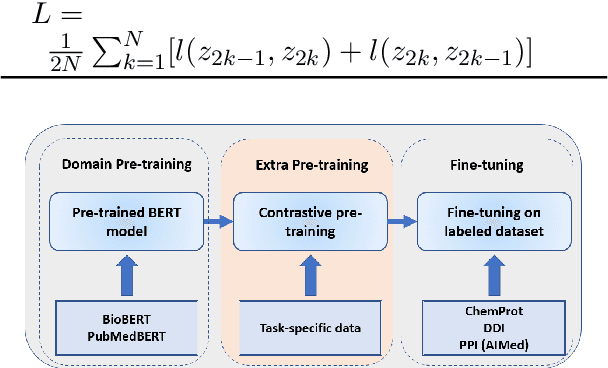
Contrastive learning has been used to learn a high-quality representation of the image in computer vision. However, contrastive learning is not widely utilized in natural language processing due to the lack of a general method of data augmentation for text data. In this work, we explore the method of employing contrastive learning to improve the text representation from the BERT model for relation extraction. The key knob of our framework is a unique contrastive pre-training step tailored for the relation extraction tasks by seamlessly integrating linguistic knowledge into the data augmentation. Furthermore, we investigate how large-scale data constructed from the external knowledge bases can enhance the generality of contrastive pre-training of BERT. The experimental results on three relation extraction benchmark datasets demonstrate that our method can improve the BERT model representation and achieve state-of-the-art performance. In addition, we explore the interpretability of models by showing that BERT with contrastive pre-training relies more on rationales for prediction. Our code and data are publicly available at: https://github.com/udel-biotm-lab/BERT-CLRE.
Investigation of BERT Model on Biomedical Relation Extraction Based on Revised Fine-tuning Mechanism
Nov 01, 2020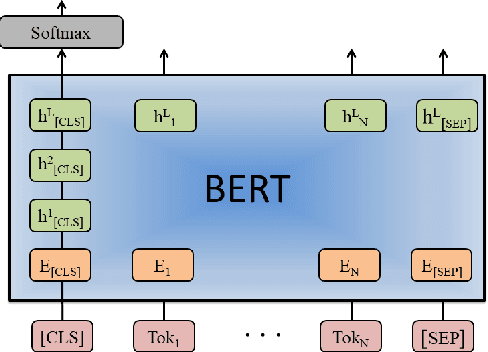
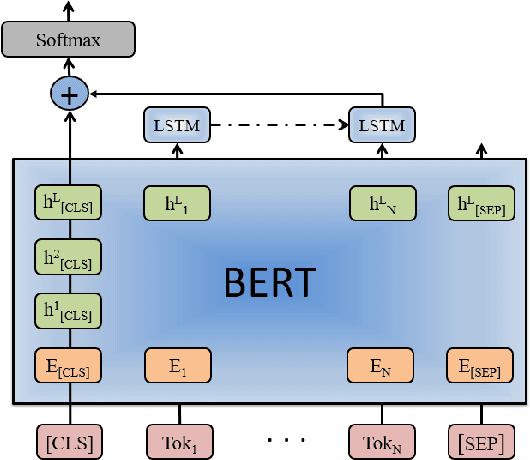
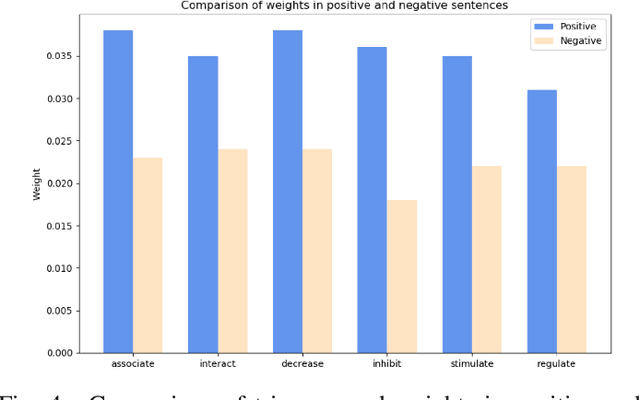
With the explosive growth of biomedical literature, designing automatic tools to extract information from the literature has great significance in biomedical research. Recently, transformer-based BERT models adapted to the biomedical domain have produced leading results. However, all the existing BERT models for relation classification only utilize partial knowledge from the last layer. In this paper, we will investigate the method of utilizing the entire layer in the fine-tuning process of BERT model. To the best of our knowledge, we are the first to explore this method. The experimental results illustrate that our method improves the BERT model performance and outperforms the state-of-the-art methods on three benchmark datasets for different relation extraction tasks. In addition, further analysis indicates that the key knowledge about the relations can be learned from the last layer of BERT model.
Adversarial Learning for Supervised and Semi-supervised Relation Extraction in Biomedical Literature
May 08, 2020
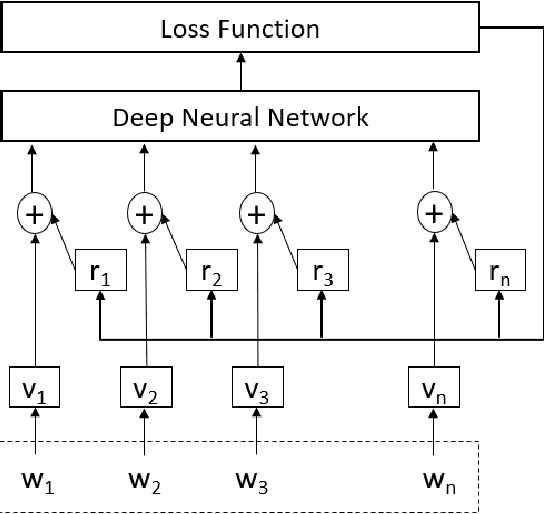
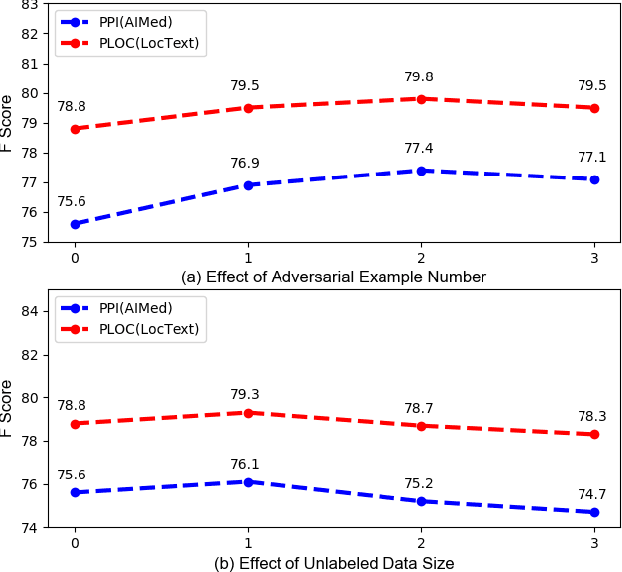

Adversarial training is a technique of improving model performance by involving adversarial examples in the training process. In this paper, we investigate adversarial training with multiple adversarial examples to benefit the relation extraction task. We also apply adversarial training technique in semi-supervised scenarios to utilize unlabeled data. The evaluation results on protein-protein interaction and protein subcellular localization task illustrate adversarial training provides improvement on the supervised model, and is also effective on involving unlabeled data in the semi-supervised training case. In addition, our method achieves state-of-the-art performance on two benchmarking datasets.
Rapid Adaptation of POS Tagging for Domain Specific Uses
Oct 31, 2014Part-of-speech (POS) tagging is a fundamental component for performing natural language tasks such as parsing, information extraction, and question answering. When POS taggers are trained in one domain and applied in significantly different domains, their performance can degrade dramatically. We present a methodology for rapid adaptation of POS taggers to new domains. Our technique is unsupervised in that a manually annotated corpus for the new domain is not necessary. We use suffix information gathered from large amounts of raw text as well as orthographic information to increase the lexical coverage. We present an experiment in the Biological domain where our POS tagger achieves results comparable to POS taggers specifically trained to this domain.
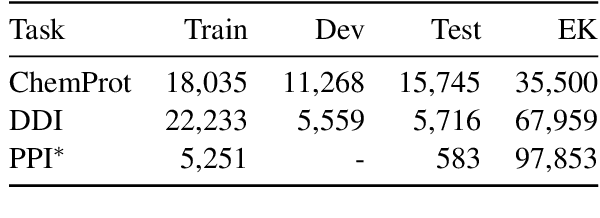
* 2 pages, 2 tables; appeared in Proceedings of the HLT-NAACL BioNLP Workshop on Linking Natural Language and Biology, June 2006
A Method for Stopping Active Learning Based on Stabilizing Predictions and the Need for User-Adjustable Stopping
Sep 17, 2014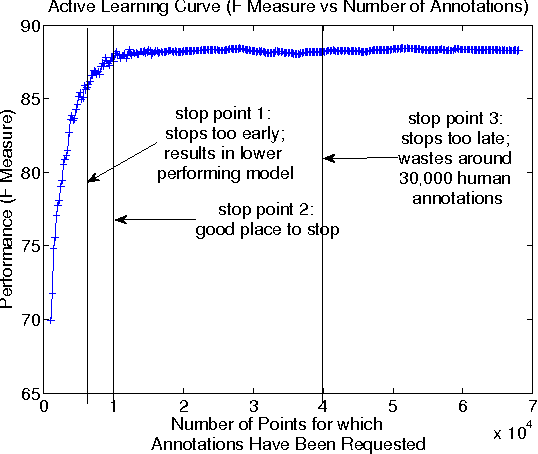
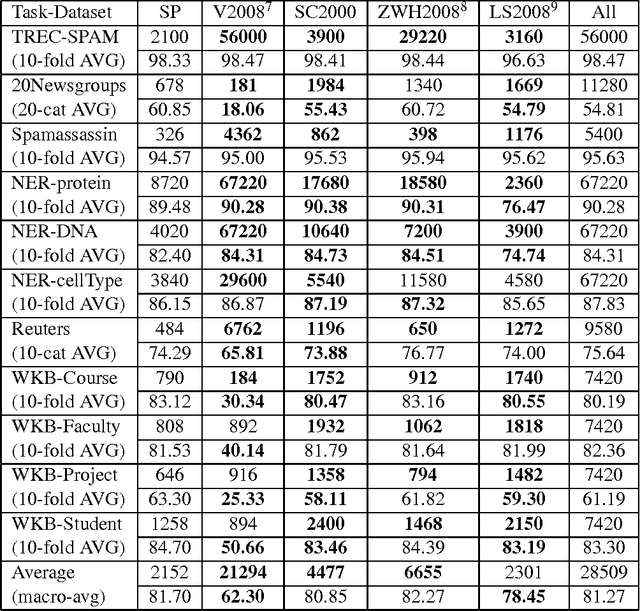
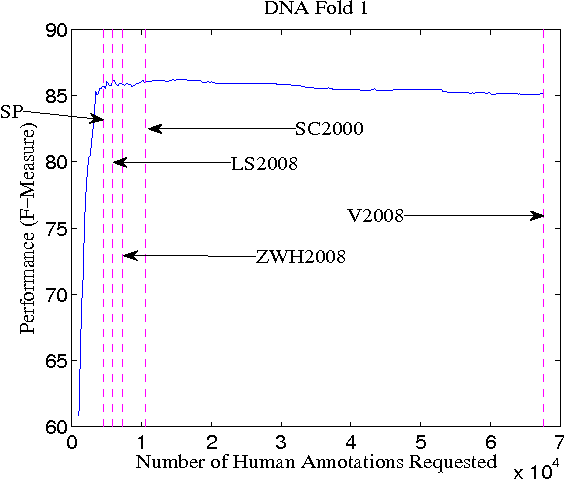
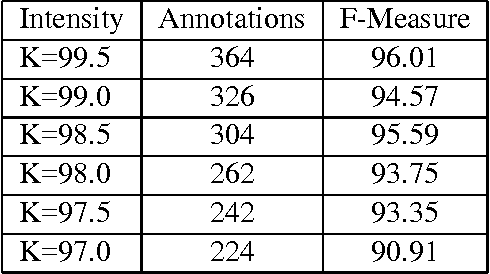
A survey of existing methods for stopping active learning (AL) reveals the needs for methods that are: more widely applicable; more aggressive in saving annotations; and more stable across changing datasets. A new method for stopping AL based on stabilizing predictions is presented that addresses these needs. Furthermore, stopping methods are required to handle a broad range of different annotation/performance tradeoff valuations. Despite this, the existing body of work is dominated by conservative methods with little (if any) attention paid to providing users with control over the behavior of stopping methods. The proposed method is shown to fill a gap in the level of aggressiveness available for stopping AL and supports providing users with control over stopping behavior.
* 9 pages, 3 figures, 5 tables; appeared in Proceedings of the Thirteenth Conference on Computational Natural Language Learning (CoNLL-2009), June 2009
Taking into Account the Differences between Actively and Passively Acquired Data: The Case of Active Learning with Support Vector Machines for Imbalanced Datasets
Sep 17, 2014
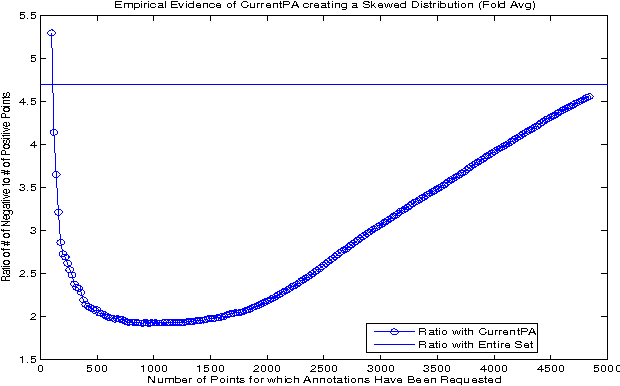
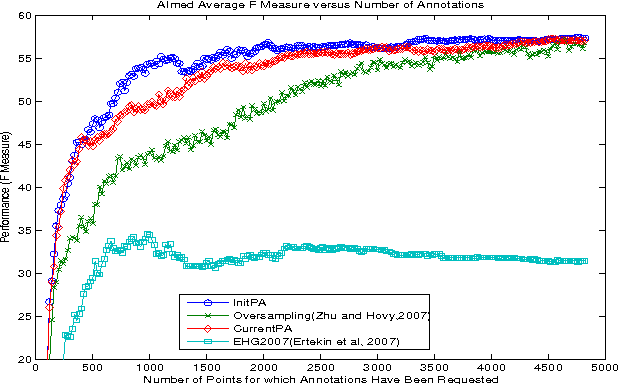

Actively sampled data can have very different characteristics than passively sampled data. Therefore, it's promising to investigate using different inference procedures during AL than are used during passive learning (PL). This general idea is explored in detail for the focused case of AL with cost-weighted SVMs for imbalanced data, a situation that arises for many HLT tasks. The key idea behind the proposed InitPA method for addressing imbalance is to base cost models during AL on an estimate of overall corpus imbalance computed via a small unbiased sample rather than the imbalance in the labeled training data, which is the leading method used during PL.
* 4 pages, 5 figures; appeared in Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Companion Volume: Short Papers, pages 137-140, Boulder, Colorado, June 2009. Association for Computational Linguistics
An Approach to Reducing Annotation Costs for BioNLP
Sep 12, 2014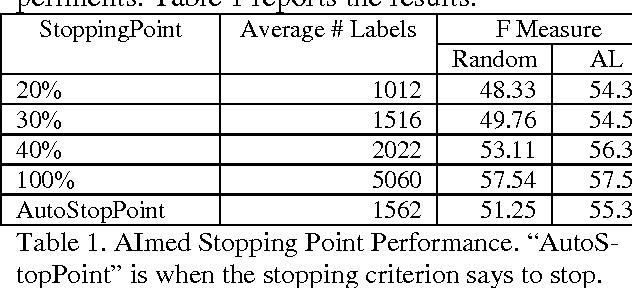
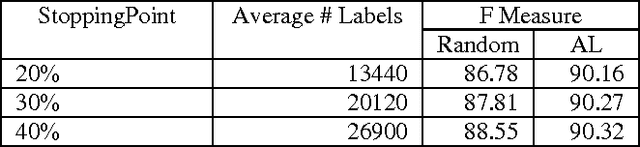

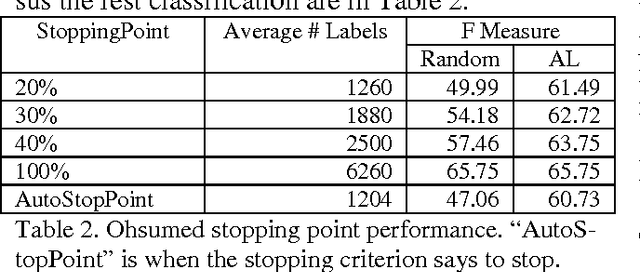
There is a broad range of BioNLP tasks for which active learning (AL) can significantly reduce annotation costs and a specific AL algorithm we have developed is particularly effective in reducing annotation costs for these tasks. We have previously developed an AL algorithm called ClosestInitPA that works best with tasks that have the following characteristics: redundancy in training material, burdensome annotation costs, Support Vector Machines (SVMs) work well for the task, and imbalanced datasets (i.e. when set up as a binary classification problem, one class is substantially rarer than the other). Many BioNLP tasks have these characteristics and thus our AL algorithm is a natural approach to apply to BioNLP tasks.
* 2 pages, 1 figure, 5 tables; appeared in Proceedings of the Workshop on Current Trends in Biomedical Natural Language Processing at ACL (Association for Computational Linguistics) 2008
Automatically Selecting Useful Phrases for Dialogue Act Tagging
Jun 18, 1999
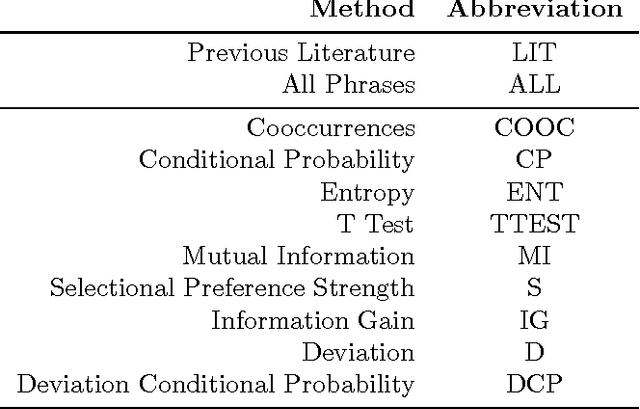
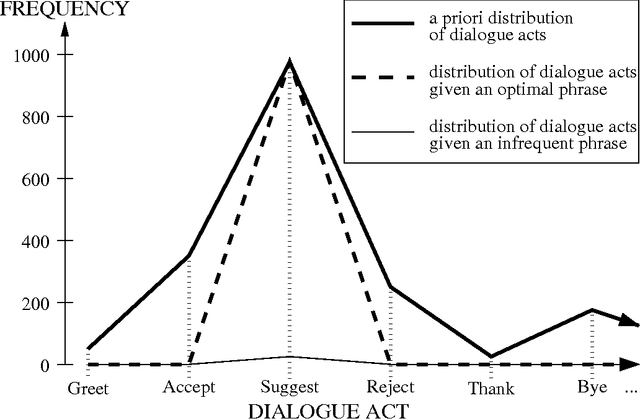
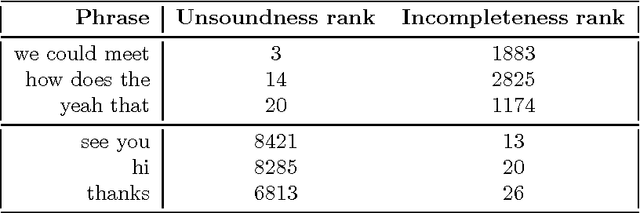
We present an empirical investigation of various ways to automatically identify phrases in a tagged corpus that are useful for dialogue act tagging. We found that a new method (which measures a phrase's deviation from an optimally-predictive phrase), enhanced with a lexical filtering mechanism, produces significantly better cues than manually-selected cue phrases, the exhaustive set of phrases in a training corpus, and phrases chosen by traditional metrics, like mutual information and information gain.
* 14 pages, published in PACLING'99