 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCU-UD: text-mining drug and chemical-protein interactions with ensembles of BERT-based models
Paper and Code

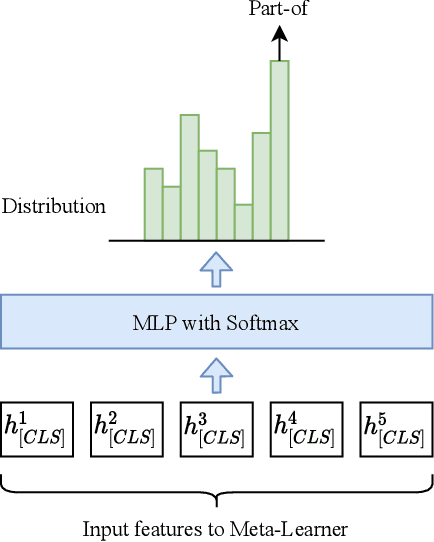
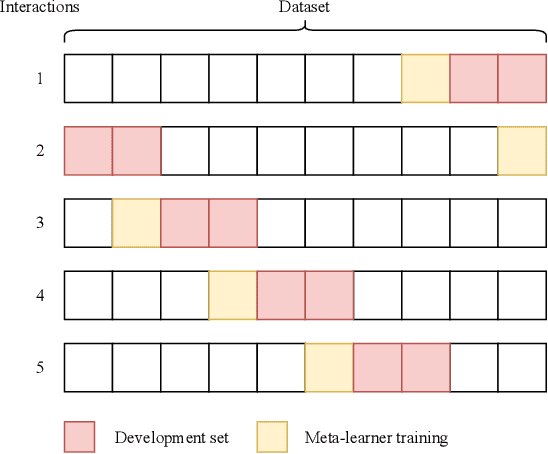
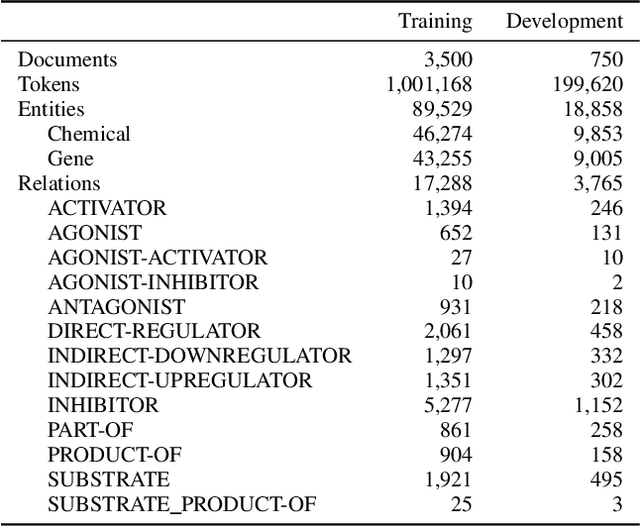
Identifying the relations between chemicals and proteins is an important text mining task. BioCreative VII track 1 DrugProt task aims to promote the development and evaluation of systems that can automatically detect relations between chemical compounds/drugs and genes/proteins in PubMed abstracts. In this paper, we describe our submission, which is an ensemble system, including multiple BERT-based language models. We combine the outputs of individual models using majority voting and multilayer perceptron. Our system obtained 0.7708 in precision and 0.7770 in recall, for an F1 score of 0.7739, demonstrating the effectiveness of using ensembles of BERT-based language models for automatically detecting relations between chemicals and proteins. Our code is available at https://github.com/bionlplab/drugprot_bcvii.