Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Selecting Useful Phrases for Dialogue Act Tagging
Paper and Code
Jun 18, 1999
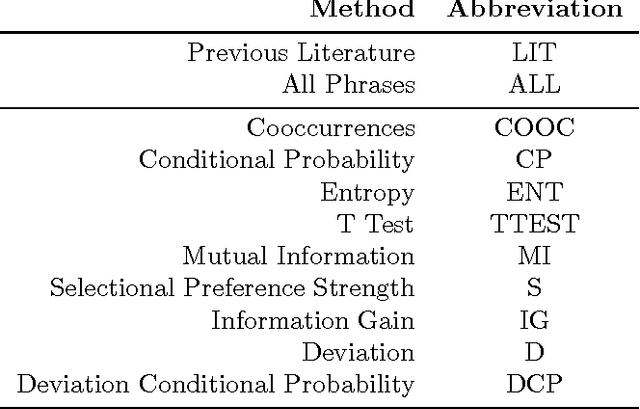
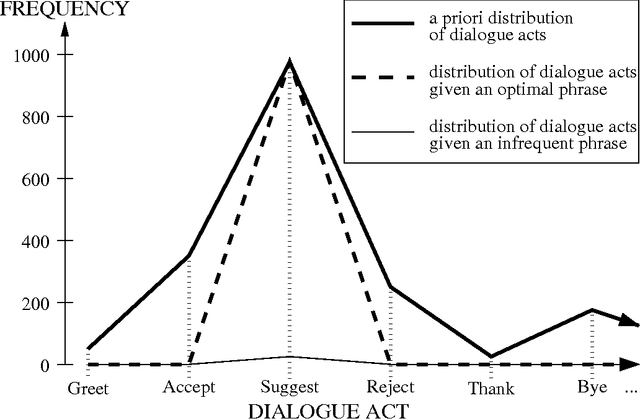
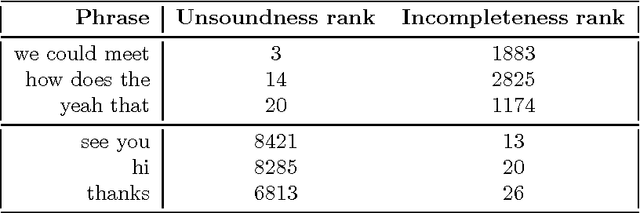
We present an empirical investigation of various ways to automatically identify phrases in a tagged corpus that are useful for dialogue act tagging. We found that a new method (which measures a phrase's deviation from an optimally-predictive phrase), enhanced with a lexical filtering mechanism, produces significantly better cues than manually-selected cue phrases, the exhaustive set of phrases in a training corpus, and phrases chosen by traditional metrics, like mutual information and information gain.
* Samuel, Ken and Carberry, Sandra and Vijay-Shanker, K. 1999.
Automatically Selecting Useful Phrases for Dialogue Act Tagging. In
Proceedings of the Fourth Conference of the Pacific Association for
Computational Linguistics. Waterloo, Ontario, Canada * 14 pages, published in PACLING'99
View paper on