 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating OWL and Semantic Web Rules into Prolog: Moving Toward Description Logic Programs
Nov 21, 2007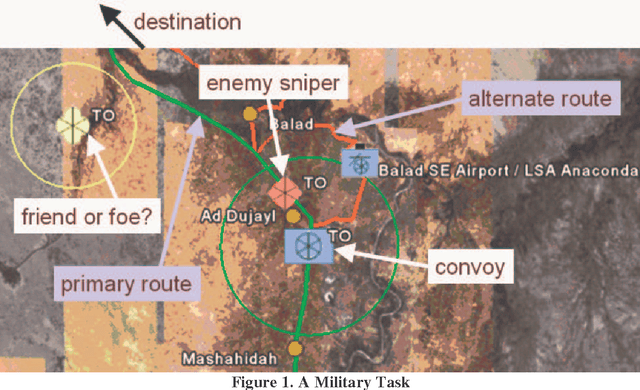
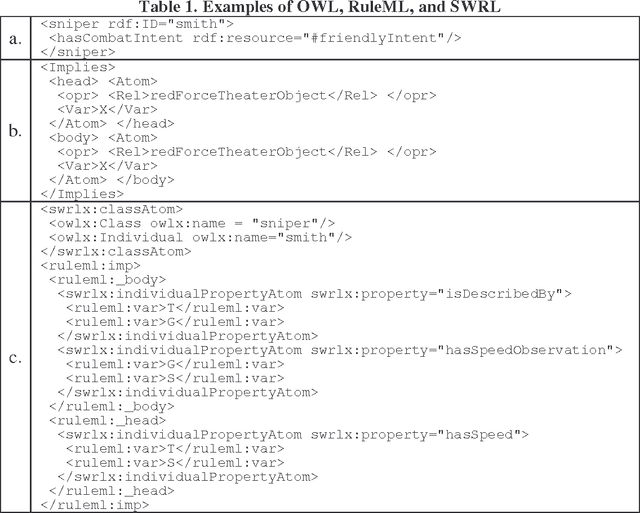
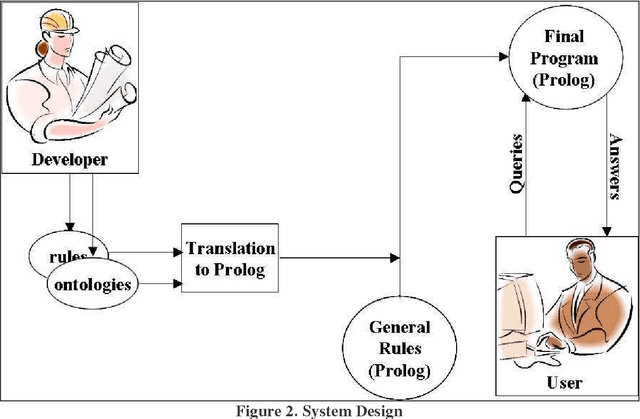

To appear in Theory and Practice of Logic Programming (TPLP), 2008. We are researching the interaction between the rule and the ontology layers of the Semantic Web, by comparing two options: 1) using OWL and its rule extension SWRL to develop an integrated ontology/rule language, and 2) layering rules on top of an ontology with RuleML and OWL. Toward this end, we are developing the SWORIER system, which enables efficient automated reasoning on ontologies and rules, by translating all of them into Prolog and adding a set of general rules that properly capture the semantics of OWL. We have also enabled the user to make dynamic changes on the fly, at run time. This work addresses several of the concerns expressed in previous work, such as negation, complementary classes, disjunctive heads, and cardinality, and it discusses alternative approaches for dealing with inconsistencies in the knowledge base. In addition, for efficiency, we implemented techniques called extensionalization, avoiding reanalysis, and code minimization.
Automatically Selecting Useful Phrases for Dialogue Act Tagging
Jun 18, 1999
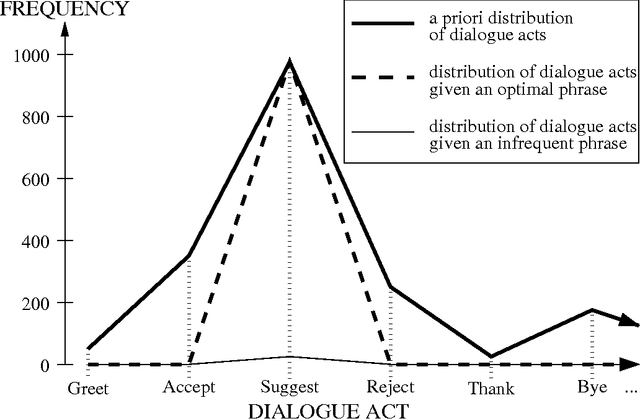
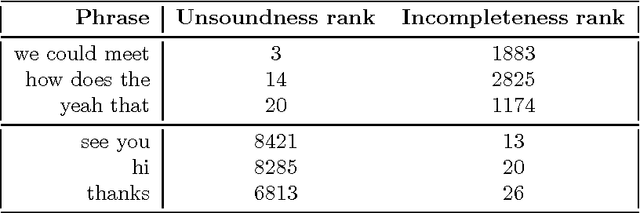
We present an empirical investigation of various ways to automatically identify phrases in a tagged corpus that are useful for dialogue act tagging. We found that a new method (which measures a phrase's deviation from an optimally-predictive phrase), enhanced with a lexical filtering mechanism, produces significantly better cues than manually-selected cue phrases, the exhaustive set of phrases in a training corpus, and phrases chosen by traditional metrics, like mutual information and information gain.
* 14 pages, published in PACLING'99
An Investigation of Transformation-Based Learning in Discourse
Jun 09, 1998
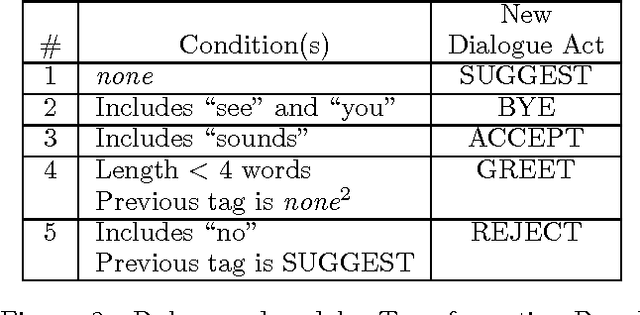

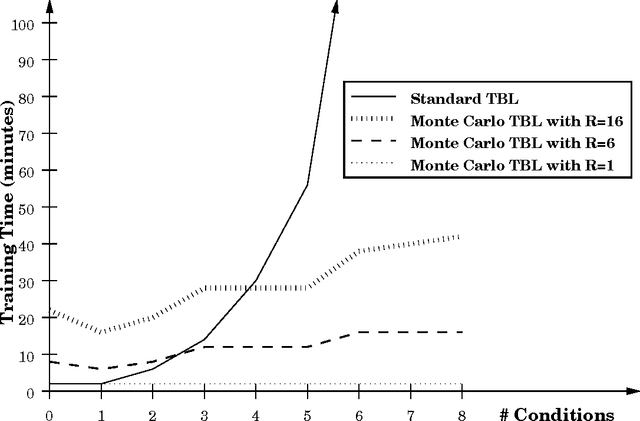
This paper presents results from the first attempt to apply Transformation-Based Learning to a discourse-level Natural Language Processing task. To address two limitations of the standard algorithm, we developed a Monte Carlo version of Transformation-Based Learning to make the method tractable for a wider range of problems without degradation in accuracy, and we devised a committee method for assigning confidence measures to tags produced by Transformation-Based Learning. The paper describes these advances, presents experimental evidence that Transformation-Based Learning is as effective as alternative approaches (such as Decision Trees and N-Grams) for a discourse task called Dialogue Act Tagging, and argues that Transformation-Based Learning has desirable features that make it particularly appealing for the Dialogue Act Tagging task.
* 9 pages, 3 Postscript figure, uses ml98.sty
Dialogue Act Tagging with Transformation-Based Learning
Jun 08, 1998


For the task of recognizing dialogue acts, we are applying the Transformation-Based Learning (TBL) machine learning algorithm. To circumvent a sparse data problem, we extract values of well-motivated features of utterances, such as speaker direction, punctuation marks, and a new feature, called dialogue act cues, which we find to be more effective than cue phrases and word n-grams in practice. We present strategies for constructing a set of dialogue act cues automatically by minimizing the entropy of the distribution of dialogue acts in a training corpus, filtering out irrelevant dialogue act cues, and clustering semantically-related words. In addition, to address limitations of TBL, we introduce a Monte Carlo strategy for training efficiently and a committee method for computing confidence measures. These ideas are combined in our working implementation, which labels held-out data as accurately as any other reported system for the dialogue act tagging task.
* 7 pages, no Postscript figures, uses colacl.sty and acl.bst
Lazy Transformation-Based Learning
Jun 03, 1998
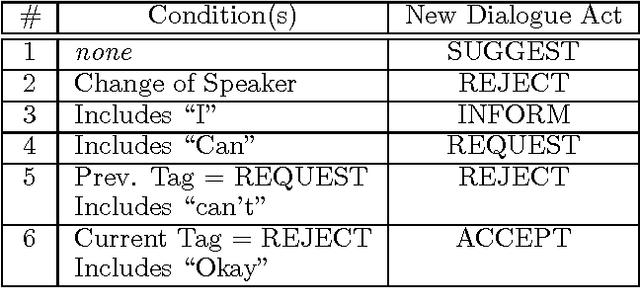

We introduce a significant improvement for a relatively new machine learning method called Transformation-Based Learning. By applying a Monte Carlo strategy to randomly sample from the space of rules, rather than exhaustively analyzing all possible rules, we drastically reduce the memory and time costs of the algorithm, without compromising accuracy on unseen data. This enables Transformation- Based Learning to apply to a wider range of domains, as it can effectively consider a larger number of different features and feature interactions in the data. In addition, the Monte Carlo improvement decreases the labor demands on the human developer, who no longer needs to develop a minimal set of rule templates to maintain tractability.
* 5 pages, 4 Postscript figures, uses aaai.sty and aaai.bst
Computing Dialogue Acts from Features with Transformation-Based Learning
Jun 02, 1998



To interpret natural language at the discourse level, it is very useful to accurately recognize dialogue acts, such as SUGGEST, in identifying speaker intentions. Our research explores the utility of a machine learning method called Transformation-Based Learning (TBL) in computing dialogue acts, because TBL has a number of advantages over alternative approaches for this application. We have identified some extensions to TBL that are necessary in order to address the limitations of the original algorithm and the particular demands of discourse processing. We use a Monte Carlo strategy to increase the applicability of the TBL method, and we select features of utterances that can be used as input to improve the performance of TBL. Our system is currently being tested on the VerbMobil corpora of spoken dialogues, producing promising preliminary results.
* 8 pages, 1 Postscript figure, uses aaai.sty and aaai.bst