Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaking into Account the Differences between Actively and Passively Acquired Data: The Case of Active Learning with Support Vector Machines for Imbalanced Datasets
Paper and Code
Sep 17, 2014
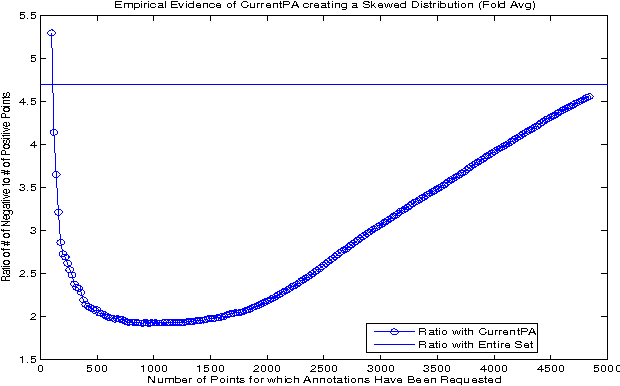
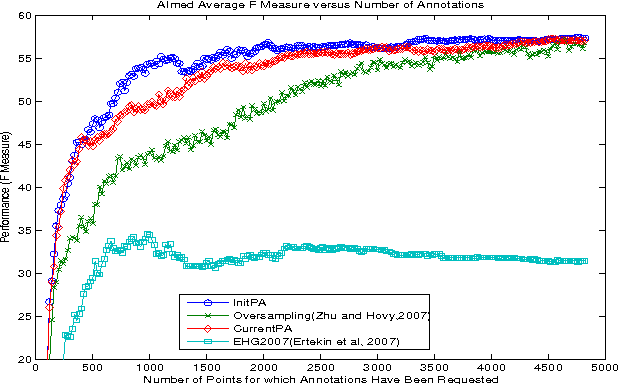

Actively sampled data can have very different characteristics than passively sampled data. Therefore, it's promising to investigate using different inference procedures during AL than are used during passive learning (PL). This general idea is explored in detail for the focused case of AL with cost-weighted SVMs for imbalanced data, a situation that arises for many HLT tasks. The key idea behind the proposed InitPA method for addressing imbalance is to base cost models during AL on an estimate of overall corpus imbalance computed via a small unbiased sample rather than the imbalance in the labeled training data, which is the leading method used during PL.
* Proceedings of HLT: The 2009 Annual Conference of the North
American Chapter of the Association for Computational Linguistics, Short
Papers, pages 137-140, Boulder, Colorado, June 2009. Association for
Computational Linguistics * 4 pages, 5 figures; appeared in Proceedings of Human Language
Technologies: The 2009 Annual Conference of the North American Chapter of the
Association for Computational Linguistics, Companion Volume: Short Papers,
pages 137-140, Boulder, Colorado, June 2009. Association for Computational
Linguistics
View paper on