 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Unintended Memorization in Language Models via Alternating Teaching
Paper and Code
Oct 13, 2022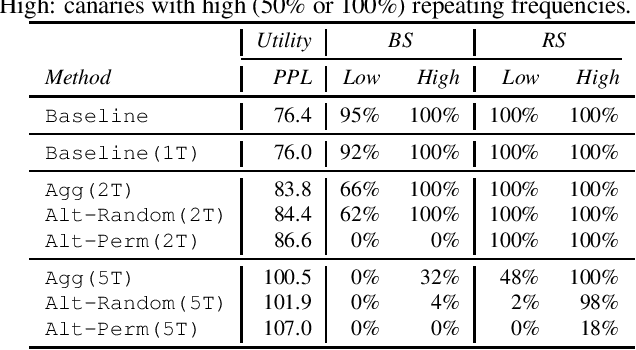
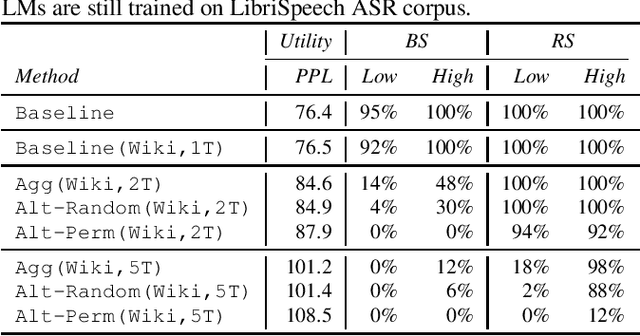
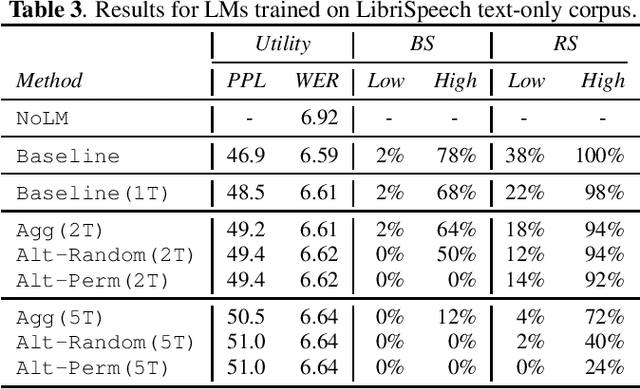
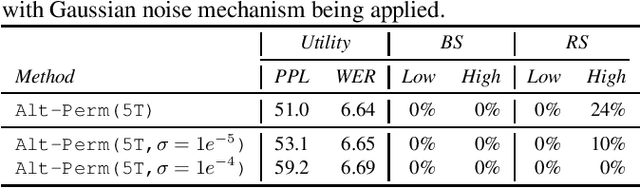
Recent research has shown that language models have a tendency to memorize rare or unique sequences in the training corpora which can thus leak sensitive attributes of user data. We employ a teacher-student framework and propose a novel approach called alternating teaching to mitigate unintended memorization in sequential modeling. In our method, multiple teachers are trained on disjoint training sets whose privacy one wishes to protect, and teachers' predictions supervise the training of a student model in an alternating manner at each time step. Experiments on LibriSpeech datasets show that the proposed method achieves superior privacy-preserving results than other counterparts. In comparison with no prevention for unintended memorization, the overall utility loss is small when training records are sufficient.