 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrection Focused Language Model Training for Speech Recognition
Paper and Code
Oct 17, 2023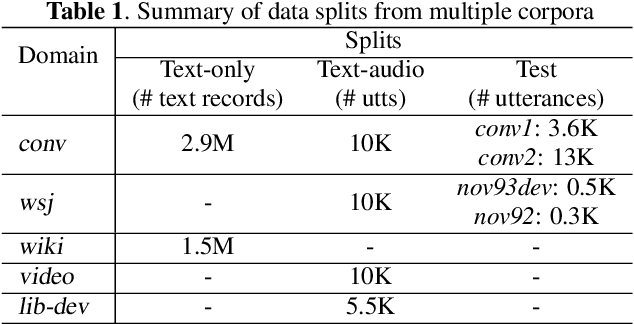

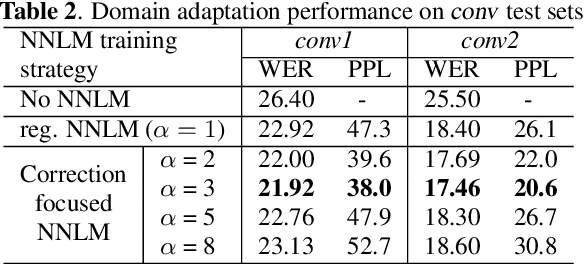
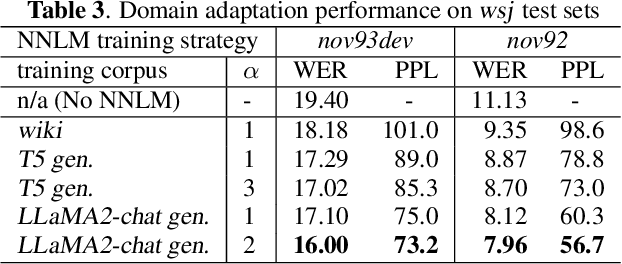
Language models (LMs) have been commonly adopted to boost the performance of automatic speech recognition (ASR) particularly in domain adaptation tasks. Conventional way of LM training treats all the words in corpora equally, resulting in suboptimal improvements in ASR performance. In this work, we introduce a novel correction focused LM training approach which aims to prioritize ASR fallible words. The word-level ASR fallibility score, representing the likelihood of ASR mis-recognition, is defined and shaped as a prior word distribution to guide the LM training. To enable correction focused training with text-only corpora, large language models (LLMs) are employed as fallibility score predictors and text generators through multi-task fine-tuning. Experimental results for domain adaptation tasks demonstrate the effectiveness of our proposed method. Compared with conventional LMs, correction focused training achieves up to relatively 5.5% word error rate (WER) reduction in sufficient text scenarios. In insufficient text scenarios, LM training with LLM-generated text achieves up to relatively 13% WER reduction, while correction focused training further obtains up to relatively 6% WER reduction.